
fastdup:释放视觉数据潜力的利器
在这个数据驱动的时代,高质量的数据集对于机器学习和人工智能的发展至关重要。然而,随着数据规模的不断扩大,如何高效地管理、清理和策划大规模视觉数据集已经成为一个巨大的挑战。为了解决这个问题,一款名为fastdup的开源工具应运而生,它正在revolutionize视觉数据分析的方式。
fastdup简介
fastdup是由XGBoost、Apache TVM和Turi Create的作者们共同开发的一款强大的免费工具。它专门设计用于快速从大规模图像和视频数据集中提取有价值的洞察。fastdup的主要目标是帮助用户提高数据集质量,降低数据运营成本,并实现前所未有的分析规模。

核心特性
fastdup具有以下几个突出的特点:
-
高质量分析: fastdup能够高质量地识别重复/近似重复图像、异常值、错误标签、损坏图像和低质量图像。这有助于用户快速发现并解决数据集中的问题。
-
超强扩展性: 该工具具有惊人的扩展能力,可以在单台CPU机器上处理多达4亿张图像。对于更大规模的数据集,它甚至可以扩展到处理数十亿张图像。
-
高速处理: 通过优化的C++引擎,fastdup即使在低配置的CPU机器上也能实现高性能运行。这意味着用户无需昂贵的硬件就能快速分析大规模数据集。
-
隐私保护: fastdup可以在本地或用户自己的云基础设施上运行,确保数据隐私和安全。
-
易用性: 该工具支持处理有标签或无标签的图像或视频数据集,并且兼容主流操作系统如MacOS、Linux和Windows。

快速上手
使用fastdup非常简单,只需几行代码就可以开始分析你的数据集:
- 首先通过pip安装fastdup:
pip install fastdup
- 然后在Python中初始化并运行fastdup:
import fastdup
fd = fastdup.create(input_dir="IMAGE_FOLDER/")
fd.run()
- 最后,你可以通过交互式Web UI或静态图库探索结果:
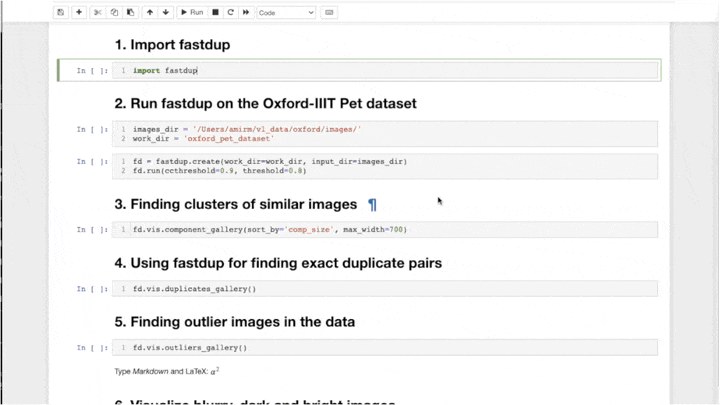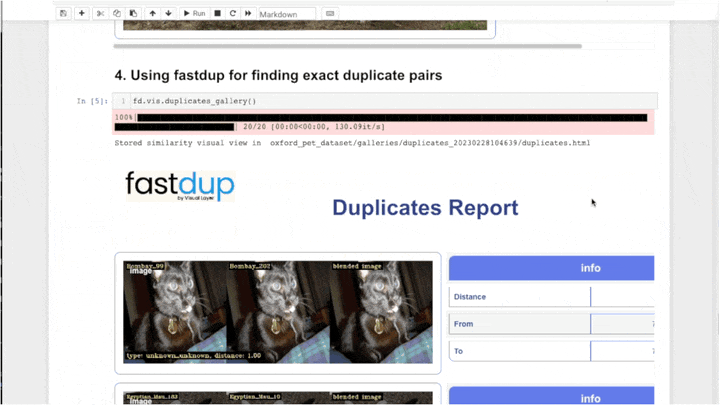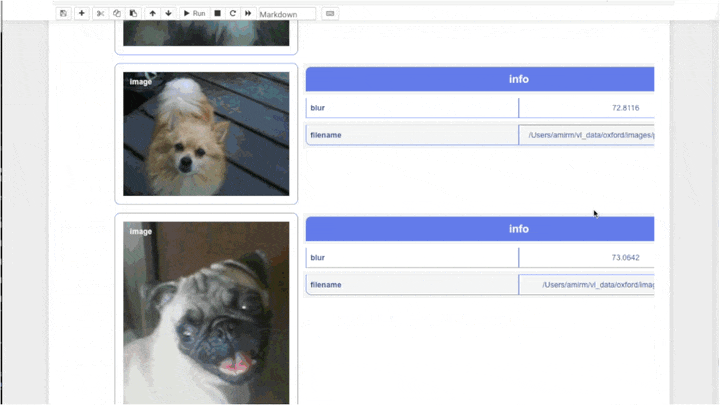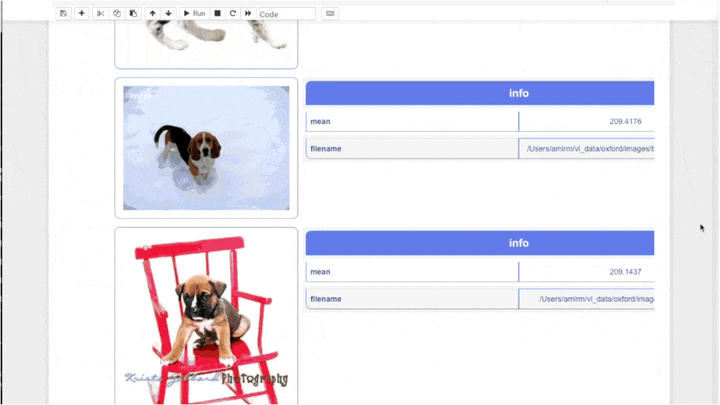
fd.vis.duplicates_gallery() # 重复图像画廊
fd.vis.outliers_gallery() # 异常值画廊
fd.vis.component_gallery() # 连通组件画廊
fd.vis.stats_gallery() # 图像统计画廊(如模糊度、亮度等)
fd.vis.similarity_gallery() # 相似图像画廊
应用场景
fastdup在多个领域都有广泛的应用前景:
-
数据清理: 快速识别并删除数据集中的重复、近似重复和低质量图像,提高数据集的整体质量。
-
异常检测: 发现数据集中的异常样本,这对于提高模型的鲁棒性和泛化能力至关重要。
-
标签质量控制: 识别可能存在错误标签的图像,帮助提高数据集的标注准确性。
-
视觉相似性搜索: 在大规模图像库中快速找到视觉上相似的图像,可用于图像检索、产品推荐等应用。
-
数据集缩减: 通过识别冗余和低质量样本,帮助用户有效地缩减数据集规模,同时保持数据集的多样性和代表性。
-
数据集探索: 为用户提供数据集的整体视图,帮助他们更好地理解数据分布和特征。
社区反馈
fastdup已经在开源社区引起了广泛关注和好评。许多用户表示,这个工具帮助他们极大地提高了数据处理效率。以下是一些用户的反馈:
"fastdup让我惊喜的不仅是它的速度,更是它的准确性。它帮我在几分钟内就找出了数据集中的问题,这在以前可能需要几天时间。"
"作为一个处理大规模图像数据的研究者,fastdup简直是救星。它不仅帮我清理了数据,还让我发现了许多有趣的数据模式。"
"fastdup的易用性令人印象深刻。即使是非技术背景的团队成员也能快速上手使用。"
未来展望
尽管fastdup已经表现出色,但其开发团队并未就此止步。他们正在积极开发新功能,包括:
- 支持更多类型的数据格式和模态。
- 改进异常检测算法,提高准确性。
- 增加更多可视化和报告功能,使结果更易理解和应用。
- 优化大规模数据处理的性能,进一步提高处理速度。
结语
在大数据时代,有效管理和分析大规模视觉数据集的重要性不言而喻。fastdup作为一款强大而易用的工具,无疑为这一领域带来了革命性的变化。无论你是数据科学家、机器学习工程师,还是计算机视觉研究者,fastdup都可能成为你工具箱中不可或缺的一员。
如果你正在处理大规模图像或视频数据集,不妨尝试使用fastdup。它可能会为你的工作带来意想不到的效率提升和洞察。你可以在GitHub上找到fastdup的源代码和详细文档。同时,活跃的社区也随时欢迎你的加入,与其他用户分享经验和想法。
让我们携手利用fastdup,共同推动视觉数据分析的边界,为人工智能和机器学习的发展贡献力量。🚀🔍🖼️









