
FastEmbed简介
FastEmbed是一个由Qdrant开发的轻量级、快速、准确的Python嵌入生成库。它支持多种流行的文本模型,可以生成高质量的文本嵌入向量,广泛应用于信息检索、推荐系统等场景。
FastEmbed的主要特点包括:
- 轻量级:依赖少,无需GPU,适合serverless环境如AWS Lambda
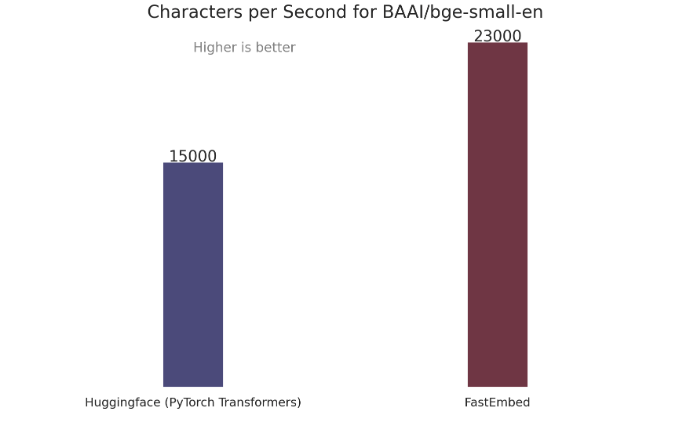
- 快速:使用ONNX Runtime,比PyTorch更快
- 准确:性能优于OpenAI Ada-002,支持多语言模型
快速入门
安装
使用pip安装FastEmbed:
pip install fastembed
如需GPU支持:
pip install fastembed-gpu
基本使用
from fastembed import TextEmbedding
documents = [
"This is a sample document.",
"FastEmbed is easy to use."
]
embedding_model = TextEmbedding()
embeddings = list(embedding_model.embed(documents))
进阶用法
稀疏文本嵌入
from fastembed import SparseTextEmbedding
model = SparseTextEmbedding(model_name="prithivida/Splade_PP_en_v1")
embeddings = list(model.embed(documents))
图像嵌入
from fastembed import ImageEmbedding
images = [
"./path/to/image1.jpg",
"./path/to/image2.jpg"
]
model = ImageEmbedding(model_name="Qdrant/clip-ViT-B-32-vision")
embeddings = list(model.embed(images))
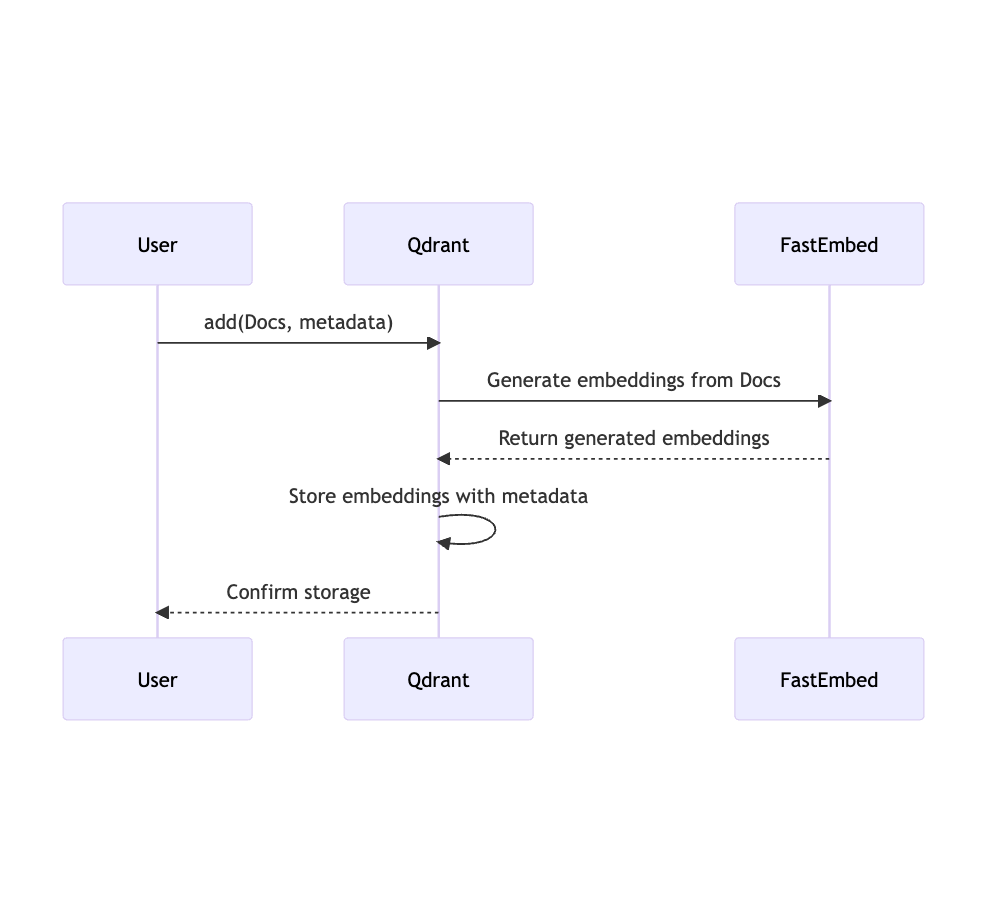
与Qdrant集成
FastEmbed可以与Qdrant向量数据库无缝集成:
from qdrant_client import QdrantClient
client = QdrantClient("localhost", port=6333)
docs = ["Qdrant has Langchain integrations", "Qdrant also has Llama Index integrations"]
metadata = [
{"source": "Langchain-docs"},
{"source": "Llama-index-docs"},
]
ids = [42, 2]
client.add(
collection_name="demo_collection",
documents=docs,
metadata=metadata,
ids=ids
)
search_result = client.query(
collection_name="demo_collection",
query_text="This is a query document"
)
print(search_result)
学习资源
总结
FastEmbed作为一个高效、准确的嵌入生成库,为开发者提供了强大的工具来处理文本和图像数据。通过本文的介绍和资源汇总,相信读者可以快速上手FastEmbed,并在实际项目中充分发挥其优势。如果您在使用过程中遇到任何问题,欢迎在GitHub Issues上提出,或加入Qdrant Discord社区寻求帮助。












