
FMBench: 为AWS上的基础模型提供全面基准测试解决方案
在当今快速发展的人工智能领域,基础模型(Foundation Models, FM)的性能评估至关重要。为了满足这一需求,AWS推出了名为FMBench的开源Python工具包,旨在为部署在各种AWS生成式AI服务上的基础模型提供全面的基准测试解决方案。
FMBench的核心功能与特点
FMBench具有以下几个显著特点:
-
高度灵活: FMBench支持多种实例类型(如g5、p4d、p5、Inf2等)、推理容器(如DeepSpeed、TensorRT、HuggingFace TGI等)以及各种参数组合(如张量并行度、滚动批处理等)。这种灵活性使得用户可以根据具体需求进行全面的性能测试。
-
广泛兼容: 无论是开源模型、第三方模型还是企业自训练的专有模型,FMBench都能胜任基准测试工作。它不仅可以评估模型的性能,还能测量模型的准确性。值得一提的是,最新版本(2.0.0)引入了由LLM评估器组成的评审团功能,进一步提升了模型评估的可靠性。
-
部署灵活: FMBench可以在任何支持Python运行的AWS平台上使用,包括Amazon EC2、Amazon SageMaker,甚至AWS CloudShell。这种灵活性确保了测试结果不会受到网络延迟的影响。
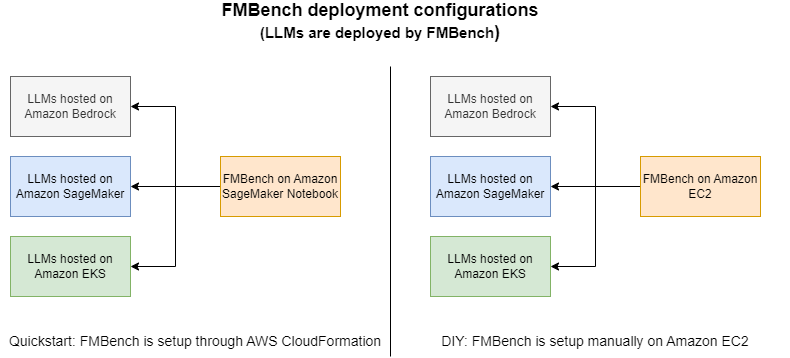
FMBench的工作原理
FMBench的工作流程如下:
- 通过FMBench部署模型或连接到已部署的端点。
- 向模型端点发送推理请求。
- 收集关键指标,如推理延迟、每分钟事务数、错误率和每次事务成本等。
- 生成包含解释性文本、表格和图表的Markdown格式报告。
这些报告为用户提供了宝贵的洞察,帮助他们为特定用例选择最佳的服务堆栈(实例类型、推理容器和配置参数)。
FMBench的实际应用
性能基准测试
以Llama2-13b模型为例,FMBench可以在不同的SageMaker实例类型上运行基准测试,使用来自LongBench数据集的Q&A任务提示(3000-3840个token)。测试结果以图表形式呈现,展示了不同实例类型的推理延迟、每分钟事务数和并发级别等关键指标。
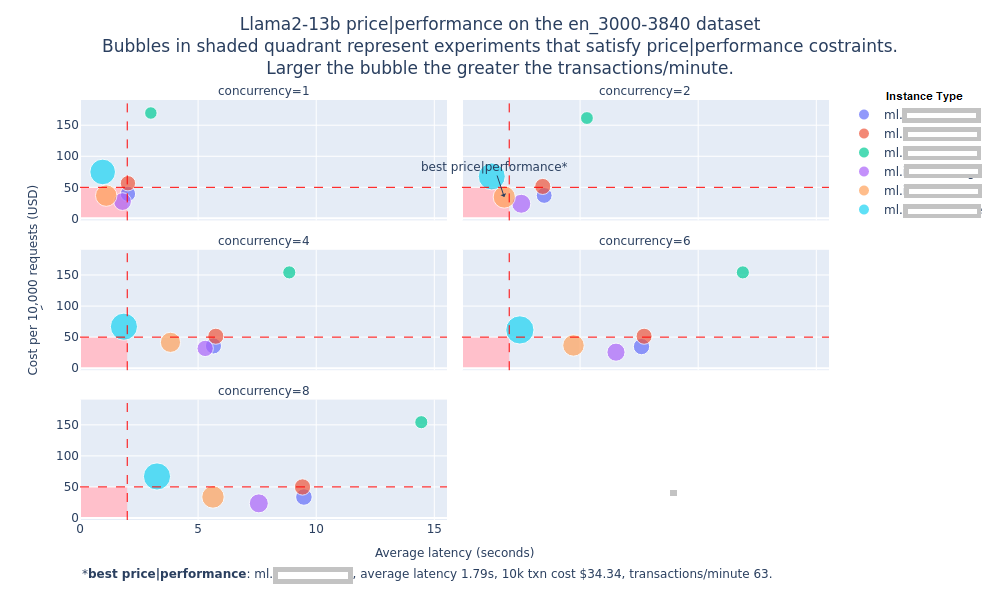
此外,FMBench还提供了详细的实验信息表格,包括最佳实例类型、平均提示token数、token吞吐量、平均完成token数、各种延迟指标(平均值、p50、p95、p99)以及每次事务的价格等。
准确性评估
FMBench引入了LLM评估器组成的评审团(PoLL)来评估模型准确性。这种方法可以为Amazon Bedrock上的各种基础模型生成准确性评估图表,帮助用户选择最适合其工作负载的模型。
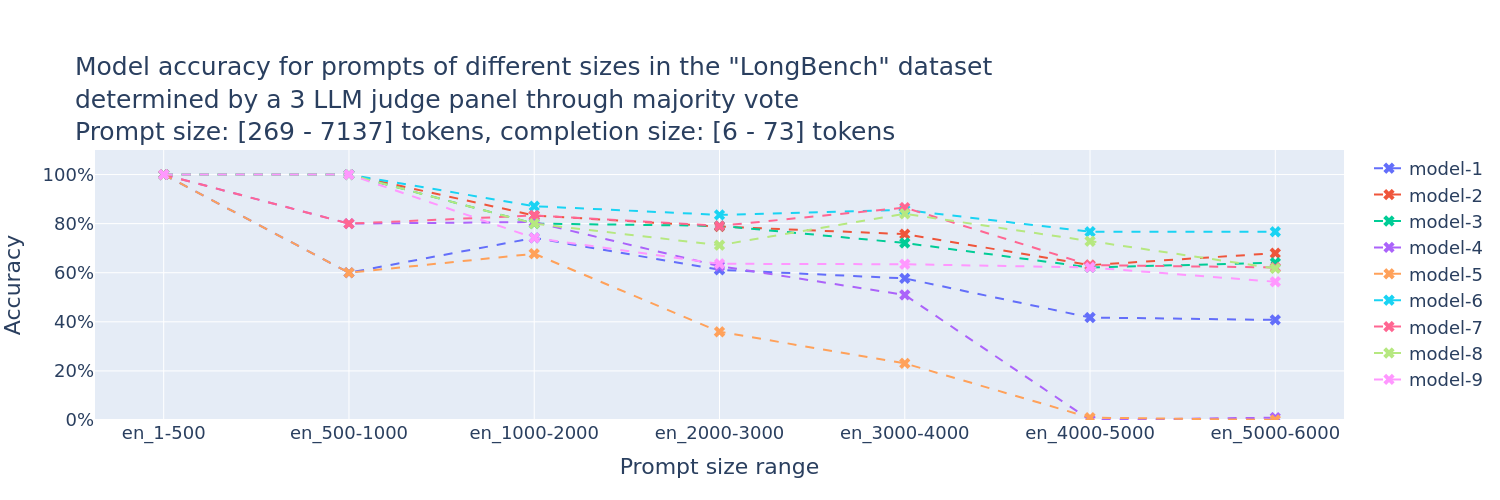
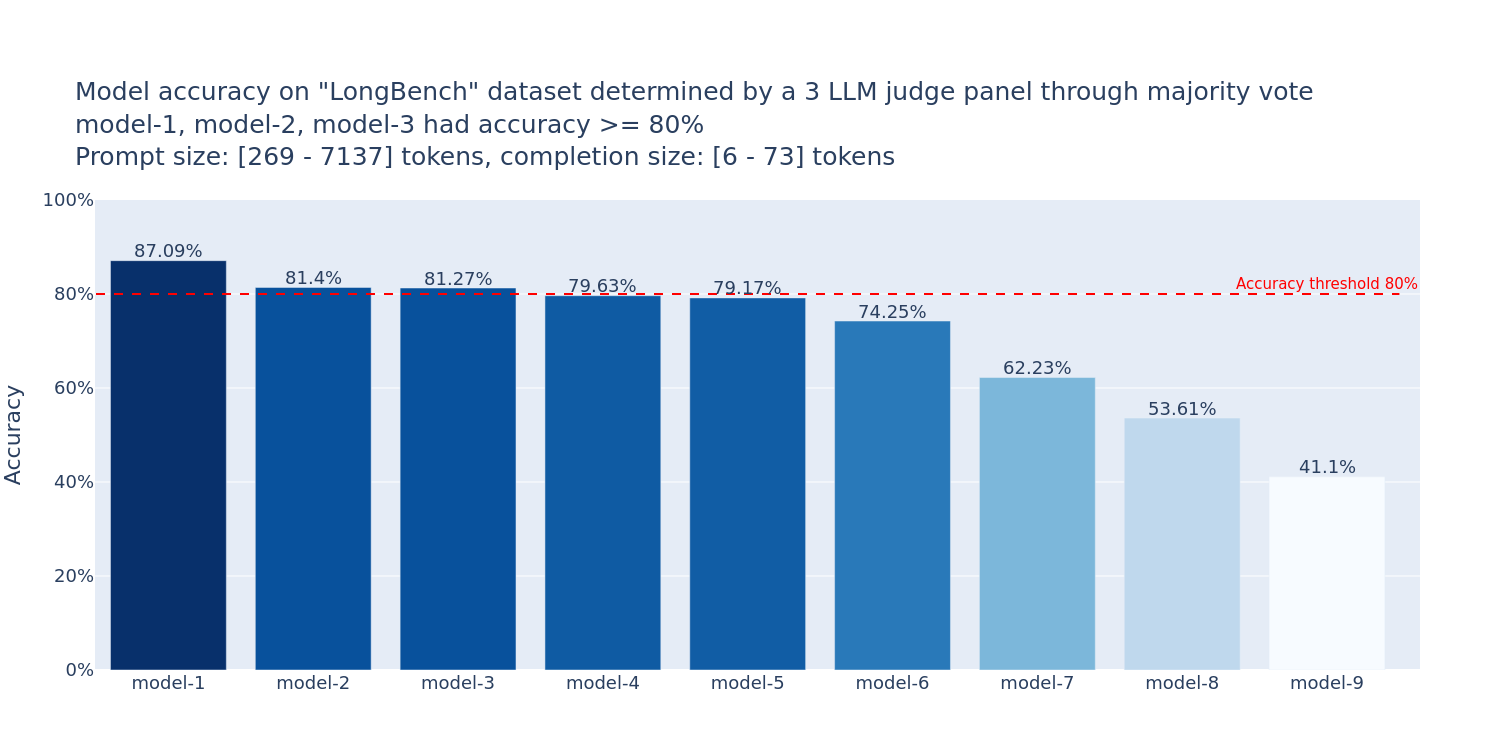
FMBench支持的模型和平台
FMBench支持多种模型和AWS平台的组合,包括:
- 模型: 从Anthropic Claude-3系列到Llama3、Mistral、Amazon Titan等多种主流模型。
- 平台: 覆盖EC2(g5、Inf2/Trn1)、SageMaker(g4dn/g5/p3、Inf2/Trn1、P4、P5)以及Bedrock(按需吞吐量和预配置吞吐量)。
这种广泛的支持使得FMBench能够满足不同用户在各种场景下的基准测试需求。
快速上手FMBench
FMBench作为Python包发布在PyPI上,安装后可作为命令行工具使用。以下是在SageMaker笔记本上快速开始使用FMBench的步骤:
-
创建并激活Python环境:
conda create --name fmbench_python311 -y python=3.11 ipykernel source activate fmbench_python311 pip install -U fmbench -
准备配置文件,可以使用FMBench GitHub仓库中提供的示例配置文件。
-
通过CloudFormation模板部署必要的AWS资源。
-
运行FMBench命令:
account=`aws sts get-caller-identity | jq .Account | tr -d '"'` region=`aws configure get region` fmbench --config-file s3://sagemaker-fmbench-read-${region}-${account}/configs/llama2/7b/config-llama2-7b-g5-quick.yml > fmbench.log 2>&1 -
查看生成的报告和指标,这些内容会保存在本地的
results目录和指定的S3存储桶中。
FMBench的高级应用
客户端-服务器配置
FMBench支持一种特殊的客户端-服务器配置,允许在一个AWS账户(服务器账户)中部署模型端点,而在另一个AWS账户(客户端账户)中运行FMBench进行测试。这种配置特别适合平台团队为数据科学团队或应用团队提供长期可用的LLM端点进行基准测试。
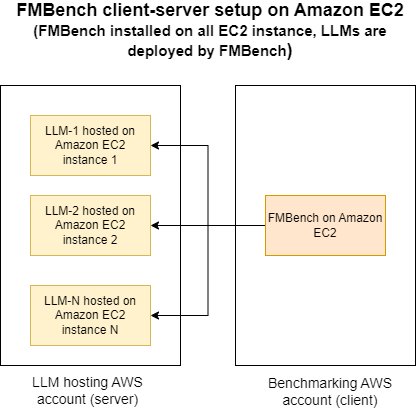
这种方法简化了流程,使平台团队能够轻松部署和管理模型,而其他团队则可以专注于使用不同数据集、性能标准和推理参数进行测试。
结语
FMBench为AWS用户提供了一个强大而灵活的工具,用于全面评估和比较各种基础模型在不同AWS生成式AI服务上的性能。通过提供详细的性能指标和准确性评估,FMBench帮助用户做出明智的决策,选择最适合其特定用例的模型和部署方案。随着AI技术的不断发展,FMBench这样的工具将在优化AI系统性能和成本效益方面发挥越来越重要的作用。
🔗 相关链接:
通过使用FMBench,AWS用户可以更好地理解和优化其AI工作负载,从而在性能、成本和准确性之间取得最佳平衡。无论您是数据科学家、ML工程师还是IT决策者,FMBench都是一个值得关注和使用的强大工具。









