Firefly-LLaMA2-Chinese 项目简介
Firefly-LLaMA2-Chinese 是一个基于 LLaMA2 的开源中文大模型项目。该项目通过对 LLaMA2 进行中文词表扩充和增量预训练,提高了模型在中文上的性能。主要特点包括:
- 对 LLaMA2 进行中文词表扩充,提高编解码效率
- 使用 22GB 中英文语料进行增量预训练
- 使用大规模中英文多轮对话数据进行指令微调
- 开源了 7B 和 13B 的 Base 和 Chat 模型权重
- 全流程训练代码和数据开源
- 在多个榜单上进行了评测,效果优秀
模型下载
项目开源了以下模型:
训练数据
项目使用的主要训练数据包括:
- firefly-pretrain-dataset: 22GB 预训练语料
- moss-003-sft-data: 100万+ 中英文多轮对话数据
- ultrachat: 140万+ 英文多轮对话数据
- school_math_0.25M: 25万条数学运算指令数据
模型评测结果
项目在多个榜单上进行了评测:
-
Open LLM Leaderboard:
- Firefly-LLaMA2-13B-Chat: 59.05 分
- Firefly-LLaMA2-7B-Chat: 54.19 分
-
CMMLU 榜单:
- Firefly-LLaMA2-13B-Chat: 39.47 分
- Firefly-LLaMA2-7B-Chat: 34.03 分
- Firefly-Baichuan2-13B: 56.83 分 (排名第 8)
-
人工评测:
- 与 Linly-LLaMA2-13B 相比,获胜率 33.08%,平局 60.77%
- 与 LLaMA2-Chat-13B 相比,获胜率 66.15%,平局 30.77%
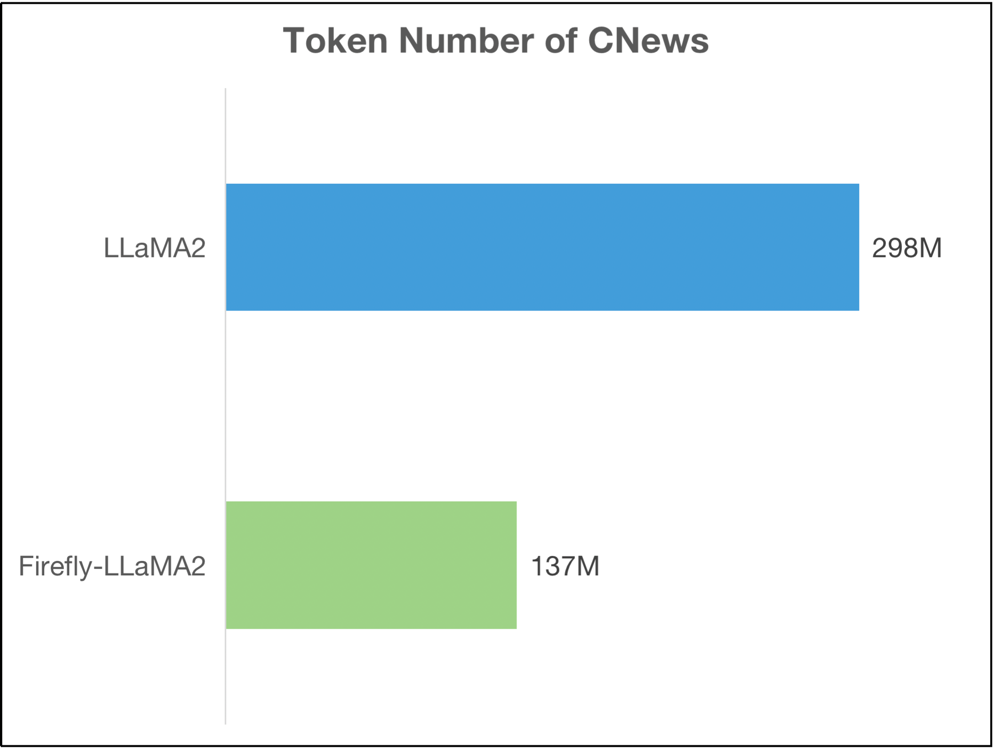
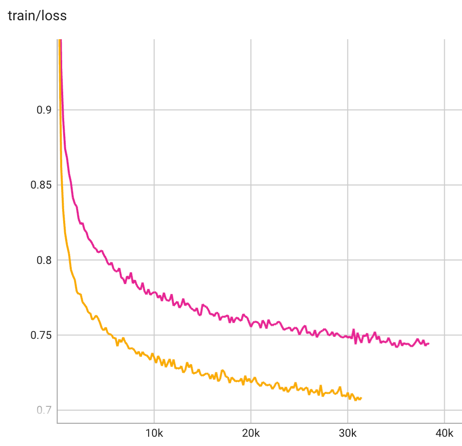
训练细节
-
词表扩充:使用 Chinese-LLaMA-Alpaca-2 项目的扩充词表
-
增量预训练:使用 22GB 中英文语料,训练 2B tokens
-
指令微调:使用 200万+ 中英文多轮对话数据
-
训练资源:最多使用 4*V100 GPU
-
训练参数:
- 序列长度: 1024
- LoRA rank: 64
- LoRA alpha: 16
- 参与训练参数量: 7B 约 612.9M, 13B 约 816.6M
使用方法
增量预训练
torchrun --nproc_per_node={num_gpus} train.py --train_args_file train_args/llama2-13b-ext.yaml
指令微调
参考 Firefly 项目的 QLoRA 训练流程
模型推理
-
权重合并:使用
script/merge_lora.py脚本合并 adapter 和 base model 权重 -
直接使用 adapter 和 base model 进行推理,无需手动合并权重
项目链接
- GitHub 仓库: Firefly-LLaMA2-Chinese
- 技术文章: QLoRA增量预训练与指令微调,及汉化Llama2的实践
总结
Firefly-LLaMA2-Chinese 项目通过低资源的方式实现了 LLaMA2 的中文优化,在多个榜单上取得了不错的成绩。项目开源了全流程的训练代码和数据,为中文大模型的研究和应用提供了宝贵的参考。希望本文能帮助读者快速了解和使用这个优秀的开源中文大模型项目。










