
Flash Attention: 革新Transformer模型的高效注意力机制
在人工智能领域,Transformer模型因其强大的性能而备受关注。然而,随着模型规模的不断扩大,传统的注意力机制在计算效率和内存使用方面面临着巨大挑战。Flash Attention应运而生,作为一种突破性的注意力算法,它不仅显著提高了计算效率,还大幅降低了内存消耗,为大规模语言模型的发展铺平了道路。
Flash Attention的核心原理
Flash Attention的核心思想是通过优化数据移动和计算模式来提高注意力机制的效率。传统的注意力实现需要在高带宽内存(HBM)和GPU片上SRAM之间频繁地读写数据,这导致了大量的内存访问开销。相比之下,Flash Attention采用了以下几个关键策略:
-
分块处理: 将输入数据划分为更小的块,以充分利用GPU的片上SRAM。
-
重计算: 在反向传播过程中,不存储中间结果,而是通过重新计算来获得所需的梯度信息。
-
IO感知: 充分考虑硬件的内存层次结构,最小化数据在不同内存层之间的移动。
-
核融合: 将多个计算步骤合并成单一的GPU操作,减少内存访问次数。
这些优化使得Flash Attention能够在保持精确计算的同时,显著提高处理速度和减少内存使用。
Flash Attention的性能优势
Flash Attention相较于传统注意力机制带来了显著的性能提升:
-
计算速度: 在各种序列长度下,Flash Attention都能实现2-4倍的加速。对于长序列(如4K tokens),加速效果更为明显,可达到5倍以上。
-
内存效率: Flash Attention的内存使用量与序列长度呈线性关系,而非传统方法的二次方关系。这意味着在处理长序列时,可以节省高达20倍的内存。
-
可扩展性: 由于内存效率的提高,Flash Attention能够处理更长的序列,为大规模语言模型的训练和推理提供了可能。
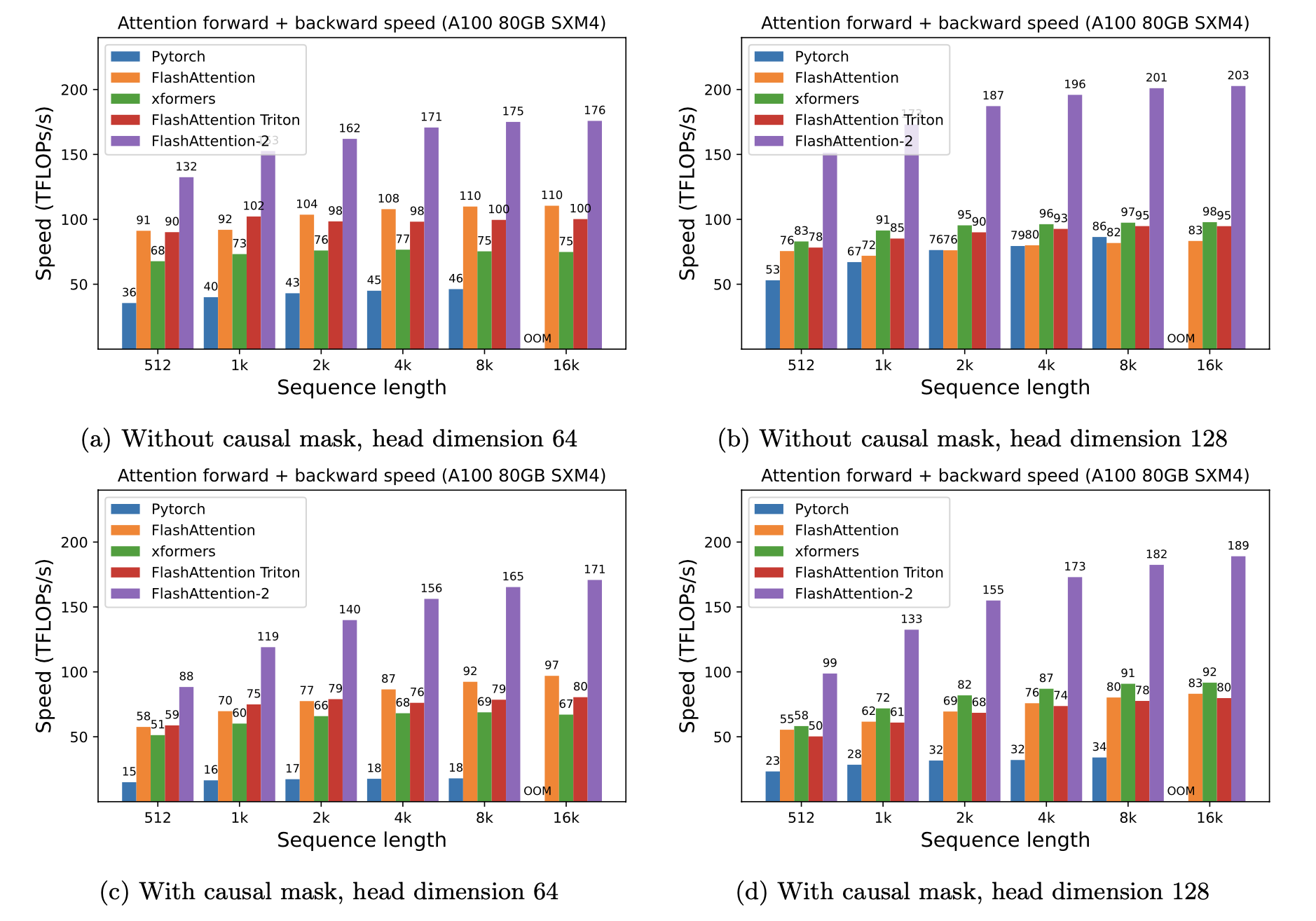
Flash Attention在大型语言模型中的应用
Flash Attention已被广泛应用于多个知名的大型语言模型项目中:
-
GPT-3: OpenAI在训练GPT-3时采用了Flash Attention,这极大地加快了训练速度并降低了成本。
-
BERT: 使用Flash Attention训练BERT-large模型(序列长度512)比MLPerf 1.1中的训练速度记录快15%。
-
长文本处理: 对于长范围arena(序列长度1K-4K),Flash Attention比基线实现快2.4倍。
-
Mistral 7B: Mistral AI在其7B参数模型中使用了Flash Attention的滑动窗口注意力变体。
这些应用案例充分证明了Flash Attention在实际大规模模型训练中的有效性和重要性。
Flash Attention的最新发展
Flash Attention技术仍在不断发展和完善。最新的Flash Attention-3版本针对最新的GPU架构(如NVIDIA H100)进行了进一步优化:
-
更高的并行度: 通过改进的工作分区策略,充分利用新一代GPU的并行计算能力。
-
精度优化: 支持FP8数据类型,在保持精度的同时进一步提高计算效率。
-
动态序列长度支持: 优化了对变长序列的处理,提高了在实际应用中的灵活性。
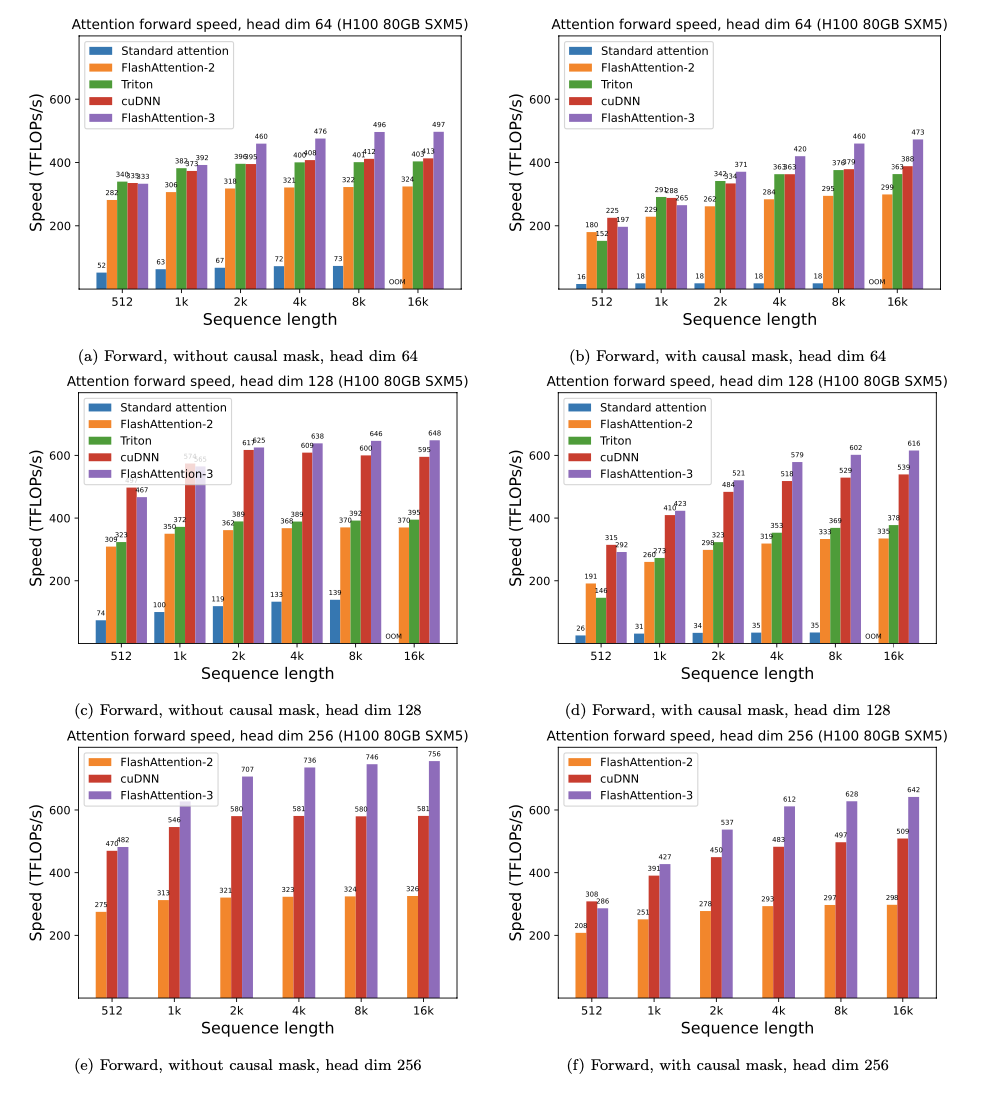
实施Flash Attention
对于希望在自己的项目中使用Flash Attention的开发者,可以通过以下方式开始:
-
安装: 使用pip安装Flash Attention包:
pip install flash-attn --no-build-isolation -
基本使用: Flash Attention提供了简单易用的API,可以直接替换标准的注意力实现:
from flash_attn import flash_attn_qkvpacked_func output = flash_attn_qkvpacked_func(qkv, dropout_p=0.0, softmax_scale=None, causal=False) -
高级功能: Flash Attention还支持滑动窗口注意力、ALiBi(注意力线性偏置)等高级特性,可根据需求灵活配置。
结论
Flash Attention代表了注意力机制实现的一个重要突破,它不仅大幅提高了Transformer模型的训练和推理效率,还为处理更长序列、构建更大规模的语言模型铺平了道路。随着AI模型规模的不断增长,Flash Attention及其衍生技术将在未来的AI发展中发挥越来越重要的作用。
对于研究人员和工程师而言,深入理解并应用Flash Attention技术,将有助于推动更高效、更强大的AI模型的发展。随着技术的不断演进,我们期待看到更多基于Flash Attention的创新应用,进一步推动人工智能领域的进步。
参考资源
通过持续关注Flash Attention的发展和应用,我们可以更好地把握AI技术的前沿动向,为构建下一代高效、强大的AI系统做好准备。













