
Flickr Scraper:为计算机视觉任务提供海量图像数据
在当今数据驱动的人工智能时代,高质量的训练数据对于构建优秀的计算机视觉模型至关重要。而Flickr作为全球最大的图片分享社区之一,无疑是获取海量图像数据的理想来源。为了帮助研究人员和开发者更便捷地从Flickr采集所需的图像数据,Ultralytics公司开发了一款名为Flickr Scraper的开源工具,为计算机视觉领域的数据采集工作带来了新的解决方案。
🚀 强大而简洁的图像采集工具
Flickr Scraper是一款基于Python开发的图像爬取工具,其设计理念是简化从Flickr网站采集图像数据的过程,为YOLO等计算机视觉模型的训练提供便捷的数据集构建方案。尽管市面上已有不少图像爬虫工具,但Flickr Scraper凭借其简洁的设计和强大的功能,正在赢得越来越多开发者的青睐。
这款工具的核心优势包括:
- 使用关键词搜索Flickr上的图片
- 直接下载图片用于构建数据集
- 简化YOLO等模型训练数据的收集过程
通过这些功能,研究人员可以快速获取特定主题的大量图像数据,为后续的模型训练和算法开发奠定基础。
🛠️ 安装与使用指南
要开始使用Flickr Scraper,首先需要确保您的系统已安装Python 3.7或更高版本。接下来,按照以下步骤进行安装和配置:
-
克隆项目仓库:
git clone https://github.com/ultralytics/flickr_scraper cd flickr_scraper -
安装依赖:
pip install -U -r requirements.txt -
获取Flickr API密钥: 访问Flickr API申请页面获取API密钥和密钥
-
配置API密钥: 在
flickr_scraper.py文件中填入您的API密钥和密钥:key = "YOUR_API_KEY" secret = "YOUR_API_SECRET"
完成上述配置后,您就可以开始使用Flickr Scraper采集图像了。以下是一个简单的使用示例:
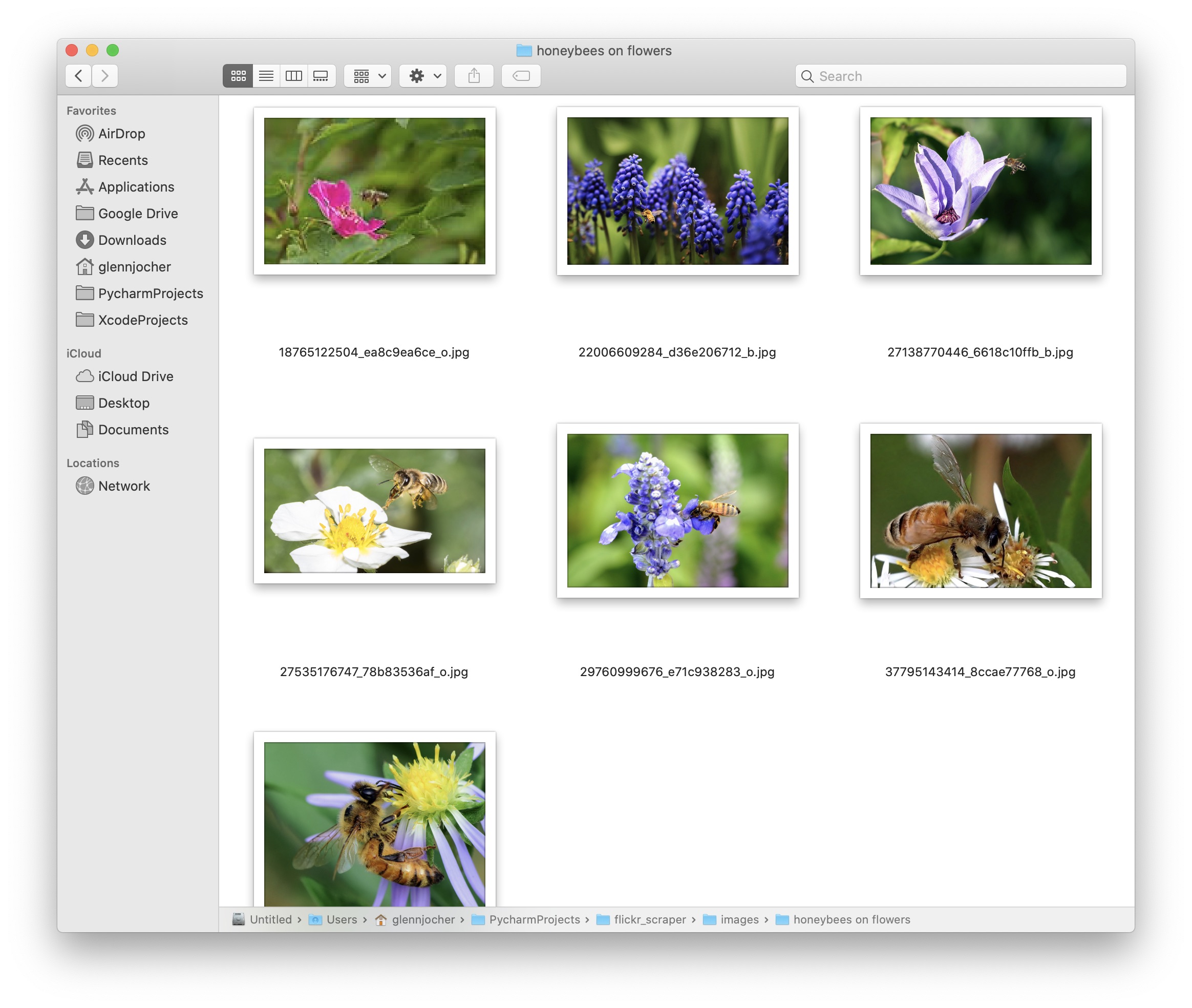
python3 flickr_scraper.py --search '蜜蜂 花朵' --n 100 --download
这条命令将搜索与"蜜蜂 花朵"相关的100张图片,并将它们下载到本地。您可以根据需要调整搜索关键词和图片数量。
🌟 社区贡献与开源精神
Flickr Scraper不仅仅是一款实用工具,更是开源社区协作的成果。Ultralytics公司鼓励开发者参与到项目的改进中来,无论是修复bug、添加新功能,还是完善文档,每一份贡献都将推动工具的进步。

如果您在使用过程中遇到任何问题,或有任何改进建议,欢迎通过GitHub Issues提出。同时,Ultralytics还提供了Discord社区,方便用户交流讨论。
📜 版权与许可
Flickr Scraper采用了两种许可方式,以满足不同用户的需求:
- AGPL-3.0许可:适合学生和爱好者使用,鼓励协作学习和知识共享。
- 企业许可:面向商业用途,允许将Ultralytics的软件和AI模型集成到商业产品中。
使用Flickr Scraper时,请务必遵守Flickr的使用条款和API限制。同时,如果您的研究或工作中使用了这个工具,建议在发表时引用相关信息。
🔮 未来展望
随着计算机视觉技术的不断发展,对高质量训练数据的需求只会越来越大。Flickr Scraper作为一款开源工具,将继续在社区的推动下不断完善和进步。未来,我们可以期待看到更多功能的加入,如:
- 支持更多图像源的整合
- 增强的图像筛选和预处理功能
- 与其他机器学习框架的深度集成
这些进步将使Flickr Scraper成为计算机视觉研究和应用中更加强大和不可或缺的工具。
总之,Flickr Scraper为研究人员和开发者提供了一个便捷的途径,助力他们从海量的Flickr图像中获取所需的训练数据。无论您是计算机视觉领域的新手还是经验丰富的专家,这款工具都将成为您数据采集工作中的得力助手。让我们一起期待Flickr Scraper在开源社区的推动下,为计算机视觉的发展做出更大的贡献。









