
扩散模型简介
扩散模型是近年来兴起的一种强大的生成模型,在图像生成等领域取得了令人瞩目的成果。本文将介绍如何从头开始实现一个扩散模型,包括DDPM(去噪扩散概率模型)、DDIM(去噪扩散隐式模型)以及无分类器引导等技术。通过动手实现这些模型,我们可以深入理解扩散模型的工作原理。
扩散模型的核心思想是通过一个逐步添加噪声的前向过程和一个逐步去噪的反向过程来生成数据。在训练时,模型学习如何从噪声数据中恢复原始数据。在生成时,模型从纯噪声开始,逐步去噪直到生成所需的样本。
项目概述
本项目实现了以下几种扩散模型:
- 标准DDPM
- 改进的DDPM(使用余弦调度器和方差预测)
- DDIM(用于更快的推理)
- 无分类器引导(用于提高图像质量)
这些模型都是在ImageNet 64x64数据集上训练的。项目使用PyTorch框架实现,并支持多GPU并行训练。
环境配置
要运行本项目,首先需要配置好Python环境。建议使用虚拟环境来管理依赖:
pip install virtualenv
python -m venv MyEnv
激活虚拟环境后,安装所需的依赖包:
pip install -U requirements.txt
注意:PyTorch应该安装支持CUDA的版本,以便在GPU上训练和生成图像。
模型架构
本项目实现了5种不同的U-Net块结构:
- res -> conv -> clsAtn -> chnAtn (Res-Conv)
- res -> clsAtn -> chnAtn (Res)
- res -> res -> clsAtn -> chnAtn (Res-Res)
- res -> res -> clsAtn -> atn -> chnAtn (Res-Res-Atn)
- res -> clsAtn -> chnAtn with 192 channels (Res Large)
其中:
- res: 普通残差块
- conv: ConvNext块
- clsAtn: 包含额外类别信息的注意力块
- atn: 用于隐藏特征的ViT注意力块
- chnAtn: 轻量级的通道注意力块
模型训练
在训练模型之前,需要下载ImageNet 64x64数据集。数据集可以从ImageNet官网下载,需要申请访问权限。
训练脚本的主要参数包括:
- embCh: U-Net顶层的通道数
- num_layers: U-Net的层数
- T: 扩散过程的时间步数
- beta_sched: 噪声调度器类型(linear或cosine)
- batchSize: 每个GPU上的批量大小
- device: 使用的设备(gpu或cpu)
- epochs: 训练的轮数
- lr: 学习率
可以使用以下命令开始训练:
torchrun --nproc_per_node=[num_gpus] src/train.py --[params]
例如,使用8个GPU并设置batch size为32:
torchrun --nproc_per_node=8 src/train.py --blk_types res,res,clsAtn,chnAtn --batchSize 32
图像生成
训练完成后,可以使用预训练模型生成图像。生成脚本的主要参数包括:
- step_size: 生成时的步长
- DDIM_scale: DDIM采样的比例(0表示纯DDIM,1表示纯DDPM)
- guidance: 分类器引导的尺度
- class_label: 要生成的类别标签
使用以下命令生成图像:
python -m src.infer --loadDir [model_dir] --loadFile [model_file] --loadDefFile [param_file] --[other params]

模型评估
本项目使用FID(Fréchet Inception Distance)来评估生成图像的质量。计算FID需要以下步骤:
- 计算ImageNet数据集的统计信息
- 计算生成图像的统计信息
- 计算两组统计信息之间的FID分数
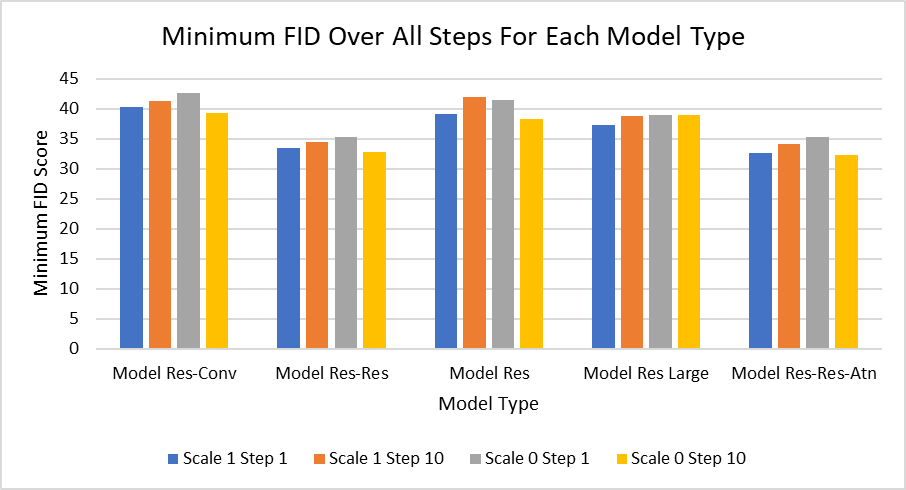
实验结果表明,具有两个残差块的模型(Res-Res和Res-Res-Atn)表现最好。有趣的是,使用DDIM(scale=0)和较大的步长(10)能够在生成速度和图像质量之间取得很好的平衡。
结论与展望
通过从头实现扩散模型,我们深入理解了DDPM、DDIM和无分类器引导等技术的工作原理。实验结果表明,这些模型能够生成高质量的图像,特别是在使用DDIM采样和适当的引导尺度时。
尽管如此,扩散模型仍然存在一些挑战,如生成速度较慢、训练时间长等。未来的研究方向可能包括:
- 进一步优化模型架构,提高生成质量和效率
- 探索更高效的采样方法,减少生成所需的步骤
- 将扩散模型应用到其他领域,如文本生成、音频合成等
通过不断改进和创新,扩散模型有望在更多领域发挥重要作用,为生成式AI的发展做出贡献。
参考资料
- Diffusion Models Beat GANs on Image Synthesis
- Denoising Diffusion Probabilistic Models
- Denoising Diffusion Implicit Models
- Classifier-Free Diffusion Guidance
- U-Net: Convolutional Networks for Biomedical Image Segmentation
本项目的完整代码和详细说明可以在GitHub仓库中找到。欢迎感兴趣的读者尝试运行和改进这些模型,共同推动扩散模型技术的发展。











