
FunCodec: 开源神经语音编解码工具包
FunCodec是一个基础的、可复现的、可集成的开源神经语音编解码工具包。它由阿里巴巴达摩院开发,旨在为语音编解码和下游应用提供一个统一的研究平台。本文将全面介绍FunCodec的主要特性、模型架构、使用方法以及最新研究进展。
主要特性
FunCodec具有以下几个主要特点:
-
开源性: FunCodec完全开源,研究人员可以自由使用和修改代码。
-
可复现性: 提供了详细的训练和推理脚本,保证实验结果可以被轻松复现。
-
可集成性: 采用模块化设计,可以方便地集成到其他语音处理系统中。
-
多任务支持: 除了基本的语音编解码,还支持文本到语音合成、音乐生成等下游任务。
-
高性能: 在相同比特率下,FunCodec模型可以达到更高的重建语音质量。
模型架构
FunCodec采用了基于变分自编码器(VAE)的架构,主要包含以下几个模块:
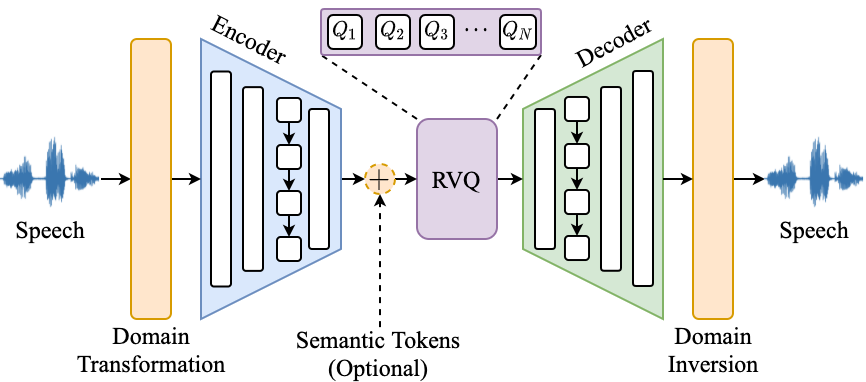
-
域转换模块: 将输入信号转换到时域、短时频域、幅度-角度域或幅度-相位域。
-
编码器: 使用卷积和LSTM层将信号编码为紧凑的表示。
-
残差向量量化(RVQ)模块: 将连续表示量化为离散的token序列。
-
解码器: 将量化后的嵌入解码回原始信号域。
-
域逆变换模块: 将解码后的信号重新合成为可感知的波形。
这种设计使得FunCodec可以灵活地处理不同域的信号,并实现高质量的语音重建。
预训练模型
FunCodec提供了多个预训练模型,适用于不同的应用场景:
| 模型名称 | 训练语料 | 比特率 | 参数量 | FLOPs |
|---|---|---|---|---|
| encodec-zh_en-general-16k-nq32ds640 | 通用 | 250~8000 | 57.83M | 7.73G |
| encodec-zh_en-general-16k-nq32ds320 | 通用 | 500~16000 | 14.85M | 3.72G |
| encodec-en-libritts-16k-nq32ds640 | LibriTTS | 250~8000 | 57.83M | 7.73G |
| encodec-en-libritts-16k-nq32ds320 | LibriTTS | 500~16000 | 14.85M | 3.72G |
| freqcodec_magphase-en-libritts-16k-gr8nq32ds320 | LibriTTS | 500~16000 | 4.50M | 2.18G |
| freqcodec_magphase-en-libritts-16k-gr1nq32ds320 | LibriTTS | 500~16000 | 0.52M | 0.34G |
这些模型在Hugging Face和ModelScope上均可获取,方便研究人员直接使用。
使用方法
安装
FunCodec的安装非常简单:
git clone https://github.com/alibaba/FunCodec.git && cd FunCodec
pip install --editable ./
模型下载
可以使用提供的脚本从ModelScope或Hugging Face下载预训练模型:
cd egs/LibriTTS/codec
model_name=audio_codec-encodec-zh_en-general-16k-nq32ds640-pytorch
bash encoding_decoding.sh --stage 0 --model_name ${model_name} --model_hub modelscope
推理
FunCodec支持批量推理,可以方便地进行编码和解码:
# 编码
bash encoding_decoding.sh --stage 1 --batch_size 16 --num_workers 4 --gpu_devices "0,1" \
--model_dir exp/${model_name} --bit_width 16000 \
--wav_scp input_wav.scp --out_dir outputs/codecs/
# 解码
bash encoding_decoding.sh --stage 2 --batch_size 16 --num_workers 4 --gpu_devices "0,1" \
--model_dir exp/${model_name} --bit_width 16000 --file_sampling_rate 16000 \
--wav_scp codecs.txt --out_dir outputs/recon_wavs
训练
FunCodec提供了在开源语料库上训练模型的脚本,以LibriTTS为例:
cd egs/LibriTTS/codec
bash run.sh --stage 0 --stop_stage 3 --gpu_devices 0,1 --gpu_num 2
同时也支持在自定义数据集上训练,只需准备好kaldi格式的wav.scp文件即可。
最新研究进展
FunCodec团队一直在持续改进这个工具包。最近的一项重要进展是LauraTTS的发布。LauraTTS是一个基于编解码器的零样本文本到语音合成器,在语义一致性和说话人相似度方面都优于VALL-E。
LauraTTS的训练和推理脚本已经集成到FunCodec中,感兴趣的研究者可以参考egs/LibriTTS/text2speech_laura/README.md获取更多细节。
总结
FunCodec作为一个开源的神经语音编解码工具包,为语音处理研究提供了一个强大而灵活的平台。它不仅支持高质量的语音编解码,还可以应用于文本到语音合成等下游任务。随着持续的更新和改进,FunCodec有望在语音处理领域发挥越来越重要的作用。
研究人员如果对FunCodec感兴趣,可以访问其GitHub仓库获取更多信息,也欢迎通过Issues提出问题和建议,共同推动这个开源项目的发展。
参考文献
-
Du, Z., Zhang, S., Hu, K., & Zheng, S. (2023). FunCodec: A Fundamental, Reproducible and Integrable Open-source Toolkit for Neural Speech Codec. arXiv preprint arXiv:2309.07405.
-
Zeng, Z., Wang, X., Du, Z., Shen, F., & Zhang, S. (2023). LauraTTS: A Multi-Speaker Text-to-Speech System Without Using Speaker Embeddings. arXiv preprint arXiv:2310.04673.










