
Gather-Deployment:Python部署、基础设施和实践的综合集合
在当今快速发展的技术环境中,掌握高效的部署和基础设施管理技能对于Python开发者来说至关重要。Gather-Deployment项目应运而生,它是由GitHub用户huseinzol05创建的一个开源仓库,旨在收集和展示Python部署、基础设施和最佳实践的各种示例和工具。本文将深入探讨Gather-Deployment项目的内容、特点以及它如何帮助开发者提升工程实践能力。
项目概述
Gather-Deployment是一个综合性的Python工程实践资源库,涵盖了从简单的后端服务到复杂的大数据处理等多个方面。该项目的主要目标是为Python开发者提供实用的部署方案、基础设施设置和最佳实践示例,帮助他们更好地理解和应用现代软件开发中的各种技术和工具。
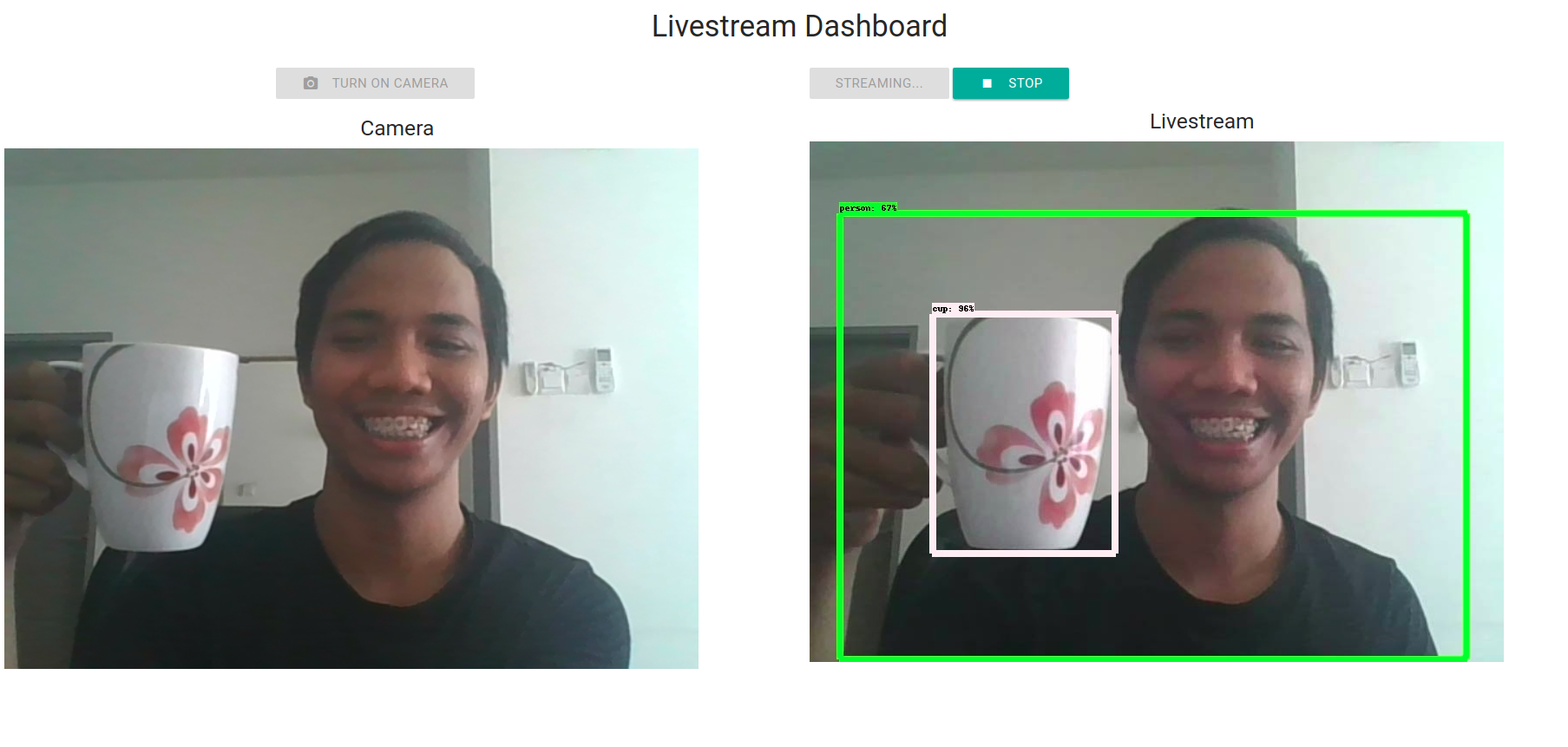
主要特点
-
多样化的部署示例: Gather-Deployment提供了丰富的部署示例,涵盖了从简单的Flask应用到复杂的分布式系统。这些示例不仅包括代码,还包括详细的配置和说明,使开发者能够快速理解和应用。
-
基础设施即代码: 项目中大量使用Docker和Docker Compose,体现了"基础设施即代码"的理念。这不仅简化了部署过程,也使得环境配置更加可重复和可维护。
-
机器学习模型部署: 特别关注TensorFlow模型的部署,提供了多种场景下的实际应用示例,如对象检测、语音识别等。
-
大数据处理实践: 包含了Hadoop、Spark、Flink等大数据技术的实践示例,帮助开发者了解如何在Python中处理和分析大规模数据。
-
实时处理和流式计算: 提供了使用Kafka、Storm等技术进行实时数据处理的示例,适用于需要处理高吞吐量数据流的场景。
-
监控和测试: 包括了使用Prometheus、Grafana等工具进行系统监控,以及使用Locust进行压力测试的实例。
-
容器化和微服务: 通过Docker和Kubernetes相关的示例,展示了如何构建和管理微服务架构。
核心组件
TensorFlow部署
Gather-Deployment提供了多种TensorFlow模型部署的方案:
- WebRTC和Flask SocketIO: 用于实时对象检测的视频流处理。
- TF Serving: 展示了如何使用TensorFlow Serving部署图像分类模型。
- 分布式TensorFlow: 演示了如何在多台机器上部署和运行单个神经网络模型。
这些示例不仅涵盖了模型的部署,还包括了与前端的集成,为开发者提供了端到端的解决方案。
简单后端
项目提供了多种后端服务的实现和部署方式:
- Flask: 包括基本的Flask应用、与MongoDB集成、RESTful API实现等。
- Redis PubSub: 演示了如何使用Redis实现发布-订阅模式。
- 负载均衡: 使用Nginx实现多个Flask实例的负载均衡。
- 消息队列: 展示了RabbitMQ和Celery的集成使用。
这些示例涵盖了后端开发中常见的场景和技术,为开发者提供了实用的参考。
Apache生态系统
Gather-Deployment对Apache生态系统的多个组件提供了支持:
- Hadoop MapReduce: 展示了如何在Flask应用中使用Hadoop进行大规模数据处理。
- Kafka: 提供了Kafka与Flask的集成示例,适用于构建实时数据流处理系统。
- PySpark: 包含了PySpark的使用示例,展示了如何进行大规模数据分析。
- Flink: 提供了Apache Flink的使用示例,适用于流处理和批处理场景。
这些示例帮助开发者了解如何在Python中使用这些强大的大数据处理工具。
数据管道
项目还包含了几个简单的数据管道示例:
- Tweepy to Elasticsearch: 展示了如何从Twitter实时抓取数据并存储到Elasticsearch。
- Luigi调度: 使用Spotify的Luigi库进行任务调度和数据处理。
- Airflow: 演示了如何使用Apache Airflow构建和管理复杂的数据处理工作流。
这些示例为构建可靠和可扩展的数据处理管道提供了参考。
实时ETL
实时ETL(Extract, Transform, Load)是现代数据处理中的重要环节。Gather-Deployment提供了两个相关的示例:
- MySQL -> Apache NiFi -> Apache Hive: 展示了如何使用Apache NiFi进行实时数据抽取和转换。
- PostgreSQL CDC -> Debezium -> KsqlDB: 演示了基于变更数据捕获(CDC)的实时数据同步方案。
这些示例对于需要构建实时数据集成和分析系统的开发者来说非常有价值。
单元测试和压力测试
项目还包含了测试相关的示例:
- Pytest: 展示了如何使用Pytest进行单元测试。
- Locust: 提供了使用Locust进行压力测试的示例。
这些示例强调了测试在软件开发中的重要性,并提供了实际的实现方法。
监控
监控是确保系统稳定运行的关键。Gather-Deployment提供了两个监控相关的示例:
- PostgreSQL + Prometheus + Grafana: 展示了如何监控PostgreSQL数据库的性能。
- FastAPI + Prometheus + Loki + Jaeger: 演示了如何对FastAPI应用进行全面的监控,包括性能指标和分布式追踪。
这些示例帮助开发者了解如何构建全面的监控系统,以便及时发现和解决问题。
使用指南
要使用Gather-Deployment项目,您需要满足以下前提条件:
- 安装Docker
- 安装Docker Compose
clone项目后,可以按照各个子目录中的README文件进行操作。大多数示例都可以通过简单的Docker Compose命令启动:
docker-compose up -d
项目价值
Gather-Deployment项目的价值主要体现在以下几个方面:
- 学习资源: 为Python开发者提供了丰富的实践示例,涵盖了从基础到高级的多个主题。
- 快速原型: 开发者可以基于项目中的示例快速构建原型系统。
- 最佳实践: 项目展示了许多行业最佳实践,如容器化、微服务架构、CI/CD等。
- 技术探索: 通过实际的代码和配置,帮助开发者快速了解和评估各种技术。
- 社区贡献: 作为开源项目,Gather-Deployment欢迎社区贡献,促进了知识共享和技术进步。
结语
Gather-Deployment项目为Python开发者提供了一个宝贵的资源库,涵盖了现代软件开发中的多个关键领域。无论您是初学者还是经验丰富的开发者,都可以从这个项目中获得有价值的见解和实践经验。通过探索和应用这些示例,您可以提升自己的技能,更好地应对复杂的软件开发和部署挑战。
随着技术的不断发展,保持学习和实践的态度至关重要。Gather-Deployment项目为我们提供了一个很好的起点,让我们能够跟上技术发展的步伐,不断提升自己的专业能力。我们鼓励读者深入探索这个项目,并在实际工作中应用所学到的知识和技能。
参考链接
- Gather-Deployment GitHub仓库
- Docker官方文档
- TensorFlow官方网站
- Apache Hadoop官方网站
- Apache Kafka官方网站
- Elasticsearch官方文档
通过深入学习和实践Gather-Deployment项目中的示例,相信每一位Python开发者都能在复杂的现代软件开发领域中找到自己的方向,并不断提升自己的技能水平。让我们一起在这个快速发展的技术世界中探索、学习、成长吧!🚀💻🐍


















