
Gemma 2B:突破10M上下文长度的革命性进展
在人工智能和自然语言处理领域,大型语言模型(LLM)的上下文长度一直是备受关注的关键指标之一。近日,由Mustafa Aljadery、Siddharth Sharma和Aksh Garg组成的研究团队在GitHub上发布了一个突破性的项目——Gemma 2B-10M,该项目成功将Gemma 2B模型的上下文长度扩展到了惊人的1000万个token。这一成就不仅标志着语言模型能力的重大飞跃,也为未来AI应用开辟了广阔的可能性。
创新技术:Infini-attention的魔力
Gemma 2B-10M项目的核心在于其采用的Infini-attention技术。这种创新方法巧妙地解决了传统多头注意力机制在处理长序列时面临的内存瓶颈问题。通常情况下,随着输入序列长度的增加,模型所需的内存会呈二次方增长,这极大地限制了模型能够处理的上下文长度。
Infini-attention通过将注意力机制分解为局部注意力块,并对这些局部块应用递归处理,成功实现了内存使用的线性增长(O(N))。这意味着,即使在处理长达1000万token的序列时,模型仍能保持相对较低的内存占用。
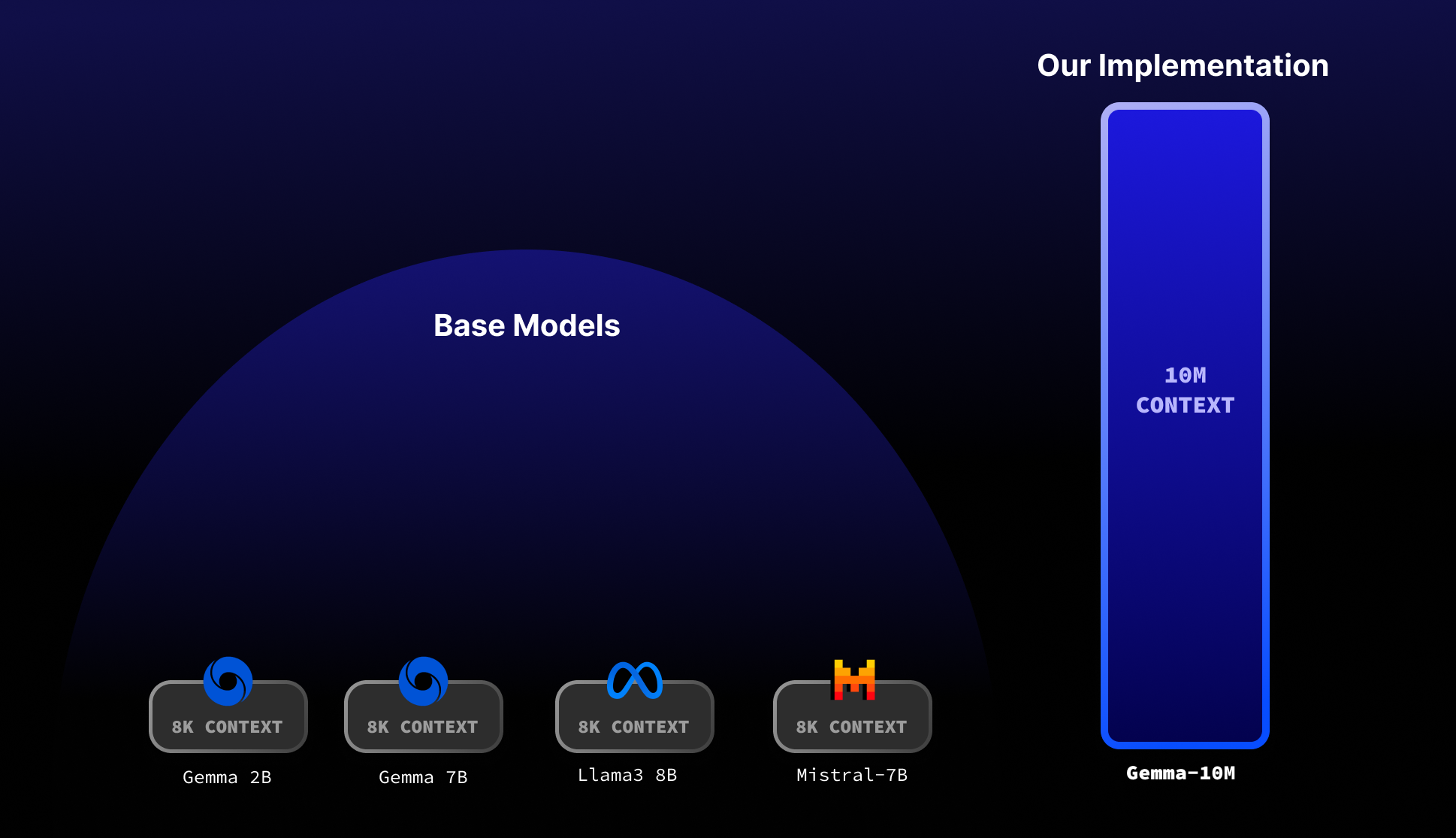
令人瞩目的特性
Gemma 2B-10M模型展现出了多项令人印象深刻的特性:
-
超长上下文: 能够处理长达1000万token的序列,这在当前的语言模型中是极为罕见的。
-
低内存占用: 即使处理如此长的序列,模型也只需要不到32GB的内存。这意味着它可以在普通的消费级硬件上运行,大大降低了使用门槛。
-
CUDA优化: 通过对CUDA进行原生优化,模型在GPU上的推理性能得到了显著提升。
-
线性内存增长: 得益于递归局部注意力机制,模型的内存使用随序列长度呈线性增长,而非传统的二次方增长。
潜在应用与影响
Gemma 2B-10M的出现为众多AI应用领域带来了新的可能性:
-
长文档分析: 能够一次性处理和理解超长文档,如学术论文、法律合同或技术报告。
-
对话系统升级: 大幅提升聊天机器人的上下文理解能力,使其能够进行更加连贯和深入的对话。
-
代码生成与分析: 可以一次性分析或生成更大规模的代码库,提高软件开发效率。
-
多模态应用: 为处理长视频转录文本或大规模图像描述等任务提供了新的解决方案。
-
知识密集型任务: 在需要综合大量信息的任务中,如学术研究辅助或复杂问题解答,表现出色。
实现细节与使用指南
对于有兴趣尝试Gemma 2B-10M的开发者,项目提供了详细的使用说明:
- 首先需要安装必要的依赖:
pip install -r requirements.txt
- 从Hugging Face下载预训练模型:
model_path = "./models/gemma-2b-10m"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = GemmaForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16
)
- 使用模型进行推理:
prompt_text = "Summarize this harry potter book..."
with torch.no_grad():
generated_text = generate(
model, tokenizer, prompt_text, max_length=512, temperature=0.8
)
print(generated_text)
值得注意的是,当前发布的版本仍处于早期阶段,仅经过200步训练。研究团队表示,他们计划在未来进行更多轮次的训练,以进一步提升模型性能。
技术原理深度解析
Gemma 2B-10M的核心创新在于其对注意力机制的改进。传统的多头注意力机制在处理长序列时会导致内存使用呈二次方增长,这是因为需要存储所有token之间的注意力权重。Infini-attention通过以下方式解决这一问题:
-
局部注意力块: 将输入序列分割成多个较小的局部块,每个块内部执行传统的注意力计算。
-
递归处理: 对局部注意力块应用递归处理,允许信息在不同块之间传递。
-
压缩记忆: 使用一种压缩机制来存储和更新长期依赖信息,避免了存储完整的注意力矩阵。
这种方法的灵感部分来自于Transformer-XL架构,但Gemma 2B-10M在此基础上进行了创新和优化,使其能够处理更长的序列。
未来展望与研究方向
尽管Gemma 2B-10M已经展现出惊人的潜力,但研究团队表示这仅仅是开始。未来的研究方向可能包括:
-
进一步扩展上下文长度: 探索突破1000万token限制的可能性。
-
提升推理效率: 优化模型架构和算法,以实现更快的推理速度。
-
多语言支持: 扩展模型以支持更多语言,增强其全球应用潜力。
-
领域特化: 为特定领域(如医疗、法律等)开发专门的长上下文模型。
-
与其他技术结合: 探索将Infini-attention与其他先进技术(如稀疏注意力、混合专家模型等)结合的可能性。
结语
Gemma 2B-10M项目的出现无疑为NLP领域带来了一股新的革命性力量。它不仅展示了突破传统上下文长度限制的可能性,也为未来AI系统的设计提供了新的思路。随着进一步的优化和应用,我们有理由相信,这项技术将在不久的将来为各行各业带来深远的影响。
对于研究人员、开发者和AI爱好者来说,Gemma 2B-10M提供了一个绝佳的机会来探索和推动语言模型的边界。通过开源这一项目,研究团队不仅分享了他们的创新成果,也为整个AI社区的协作与进步做出了重要贡献。
随着技术的不断演进,我们期待看到更多基于Gemma 2B-10M的创新应用出现,进一步推动人工智能在理解和生成长文本方面的能力。这一突破性进展无疑将为未来的智能系统开辟新的可能性,让我们共同期待AI技术带来的更多惊喜。









