
GigaGAN:突破性的文本到图像生成模型
GigaGAN 是 Adobe 研究团队最新推出的生成对抗网络(GAN)模型,代表了文本到图像生成领域的最新突破。这个项目由知名开发者 Phil Wang (GitHub 用户名 lucidrains) 在 PyTorch 中实现,为研究人员和开发者提供了一个强大的工具来探索和应用这一前沿技术。
GigaGAN 的核心特点
GigaGAN 建立在近十年 GAN 研究的基础之上,融合了多项创新技术:
-
多尺度生成器和判别器:通过在不同分辨率上同时进行图像生成和判别,大幅提高了生成图像的质量和细节。
-
视觉辅助判别器:利用预训练的视觉模型来增强判别器的能力,使其能更好地捕捉图像的语义信息。
-
匹配感知损失:确保生成的图像与输入文本描述的语义一致性。
-
对比损失:进一步提高生成图像的多样性和质量。
-
高效的注意力机制:采用 FlashAttention 等技术,提高了模型的训练效率。
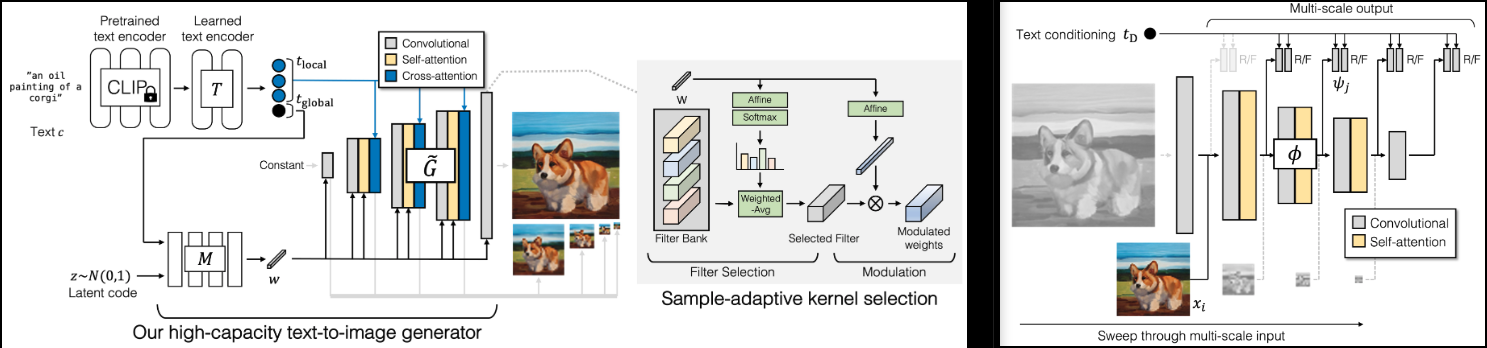
项目亮点
-
灵活的实现:支持条件和非条件 GAN 训练,以及上采样网络的训练。
-
多 GPU 训练支持:集成了 Hugging Face 的 Accelerator 库,轻松实现多 GPU 训练。
-
丰富的辅助损失:包括梯度惩罚、重建损失等,有助于提高训练稳定性和生成质量。
-
开源社区支持:项目得到了 StabilityAI 和 Hugging Face 等机构的赞助,并欢迎社区贡献。
使用示例
以下是一个简单的非条件 GAN 训练示例:
import torch
from gigagan_pytorch import GigaGAN, ImageDataset
gan = GigaGAN(
generator = dict(
dim_capacity = 8,
style_network = dict(
dim = 64,
depth = 4
),
image_size = 256,
dim_max = 512,
num_skip_layers_excite = 4,
unconditional = True
),
discriminator = dict(
dim_capacity = 16,
dim_max = 512,
image_size = 256,
num_skip_layers_excite = 4,
unconditional = True
),
amp = True
).cuda()
# 设置数据集和数据加载器
dataset = ImageDataset(
folder = '/path/to/your/data',
image_size = 256
)
dataloader = dataset.get_dataloader(batch_size = 1)
gan.set_dataloader(dataloader)
# 训练模型
gan(
steps = 100,
grad_accum_every = 8
)
# 生成图像
images = gan.generate(batch_size = 4) # 输出形状: (4, 3, 256, 256)
未来发展方向
GigaGAN-PyTorch 项目仍在积极开发中,计划实现更多功能:
- 完善文本条件训练
- 优化上采样网络架构
- 增加差异化增强技术
- 提高训练效率和稳定性
- 集成 LAION 数据集支持

总结
GigaGAN-PyTorch 为研究人员和开发者提供了一个强大的工具,用于探索最新的 GAN 技术。通过结合多项创新,该项目有望推动文本到图像生成领域的进一步发展。随着持续的改进和社区贡献,我们可以期待看到更多令人惊叹的应用和突破。
欢迎有兴趣的开发者访问 GigaGAN-PyTorch GitHub 仓库 了解更多详情,并参与到这个激动人心的项目中来。让我们一起探索 AI 驱动的创意新世界!🚀🎨









