
GILL:多模态语言模型的图像生成新突破
近年来,人工智能领域取得了长足的进步,特别是在自然语言处理和计算机视觉的交叉领域。而最近出现的GILL (Generating Images with Large Language Models) 模型无疑是这一领域的又一重大突破。GILL能够处理任意交错的图像和文本输入,不仅可以生成文本,还能检索图像和生成全新的图像。本文将深入探讨GILL的原理、应用及其对人工智能发展的深远影响。
GILL的核心原理
GILL的核心思想是将大型语言模型 (LLM) 的强大文本处理能力与视觉模型相结合。它采用了一种创新的架构,主要包含以下几个关键组件:
-
大型语言模型:GILL使用OPT (Open Pretrained Transformer) 作为其基础语言模型。OPT经过大规模文本数据的预训练,具有强大的语言理解和生成能力。
-
视觉编码器:GILL采用CLIP (Contrastive Language-Image Pre-training) 模型作为视觉编码器,将图像转换为向量表示。
-
线性映射层:这些层将CLIP的视觉特征映射到OPT的文本嵌入空间,实现了视觉信息和语言信息的融合。
-
特殊的[IMG]标记:GILL引入了[IMG]标记来表示图像在输入序列中的位置,使模型能够处理图文交错的输入。
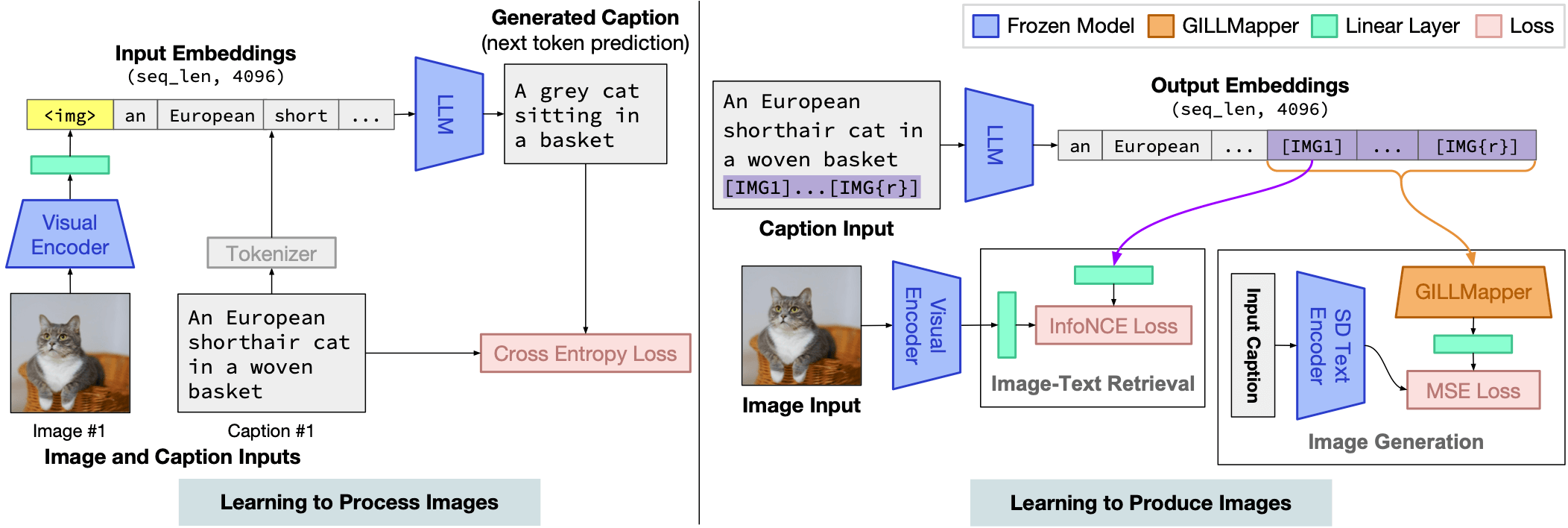
这种架构设计使GILL能够无缝地处理文本和图像信息,实现了多模态输入的理解和生成。
GILL的主要功能
GILL展现出了惊人的多功能性,主要包括以下几个方面:
-
文本生成:给定图文混合输入,GILL可以生成相关的文本描述或回答。
-
图像检索:GILL能够根据文本描述从大规模图像库中检索最相关的图像。
-
图像生成:最引人注目的是,GILL可以根据文本提示或图文混合输入生成全新的图像。
这些功能使GILL成为一个真正的多模态AI助手,能够理解和生成跨越文本和视觉领域的内容。
GILL的应用场景
GILL的多功能性为其开辟了广泛的应用前景:
-
创意设计:设计师可以使用GILL快速将文本描述转化为视觉概念,加速创意过程。
-
内容创作:作家和内容创作者可以利用GILL生成与文本相匹配的图像,丰富内容表现力。
-
教育辅助:GILL可以根据教学内容生成相关图像,帮助学生更好地理解抽象概念。
-
视觉问答:在客户服务等场景中,GILL可以理解用户的图文混合查询,并提供准确的回答。
-
虚拟助手:GILL的多模态能力使其成为更智能、更自然的虚拟助手,能够理解和生成多种形式的信息。
GILL的技术创新
GILL在技术上有几个关键的创新点:
-
多模态融合:GILL成功地将大型语言模型与视觉模型结合,实现了真正的多模态理解和生成。
-
灵活的输入处理:通过引入[IMG]标记,GILL能够处理任意交错的图文输入,大大增加了模型的灵活性。
-
零样本学习:GILL展现出了强大的零样本学习能力,能够在没有专门训练的情况下完成新任务。
-
高效的架构:GILL通过重用预训练模型并仅训练少量参数,实现了高效的训练和推理。
GILL的训练与优化
GILL的训练过程也有几个值得注意的特点:
-
数据集:GILL主要在Conceptual Captions数据集上训练,该数据集包含大量的图像-文本对。
-
预处理:为提高训练效率,研究人员预先计算了图像的视觉嵌入。
-
决策分类器:研究人员训练了一个额外的分类器,用于决定是检索还是生成图像。
-
评估:GILL在VIST(Visual Storytelling)和VisDial(Visual Dialog)等任务上进行了评估,展现出优秀的性能。
GILL的局限性与未来发展
尽管GILL展现出了令人印象深刻的能力,但它仍然存在一些局限性:
-
图像生成质量:虽然GILL可以生成相关图像,但其质量可能不如专门的图像生成模型。
-
计算资源需求:作为一个大型多模态模型,GILL需要considerable的计算资源。
-
偏见与伦理问题:如同其他AI模型,GILL也可能继承训练数据中的偏见,需要谨慎处理。
未来,GILL的发展方向可能包括:
-
提升图像生成质量,可能通过结合更先进的图像生成技术。
-
扩大训练数据范围,提高模型的知识广度和理解深度。
-
探索更多应用场景,如视频处理、3D建模等。
-
优化模型架构,提高效率并减少资源需求。
-
加强模型的可解释性和可控性,以应对潜在的伦理问题。
结论
GILL代表了人工智能向真正的多模态理解和生成迈出的重要一步。它不仅展示了大型语言模型在处理视觉信息方面的潜力,也为未来的AI系统指明了方向。随着技术的不断进步,我们可以期待看到更多像GILL这样的创新模型,它们将进一步模糊人类感知和机器智能之间的界限,为我们带来更智能、更自然的人机交互体验。
GILL的出现无疑激发了研究人员和开发者的想象力。它为跨模态AI的发展提供了新的思路,也为各行各业的应用开辟了新的可能性。虽然还有许多挑战需要克服,但GILL已经向我们展示了AI的美好未来。在这个未来中,机器将能够更全面地理解和表达信息,就像人类一样自如地在文字和图像之间切换。
随着GILL和类似技术的不断发展,我们可以期待看到更多令人惊叹的AI应用。这些应用将改变我们与信息交互的方式,提高工作效率,激发创造力,并可能带来全新的艺术形式。GILL的故事仍在继续,而它所代表的多模态AI革命才刚刚开始。让我们拭目以待,见证AI带来的更多精彩。









