
GluonTS: 强大的概率时间序列建模库
GluonTS是一个功能强大的Python库,专门用于概率时间序列建模,尤其关注基于深度学习的模型。它基于PyTorch和MXNet构建,为数据科学家和研究人员提供了一套全面的工具,用于处理常见的时间序列任务,如预测和异常检测。
主要特点
GluonTS的主要特点包括:
-
简化的建模流程: GluonTS提供了必要的组件和工具,使时间序列建模变得简单高效。用户可以快速开发模型、进行实验和评估。
-
多种预训练模型: 库中包含了多种最先进的时间序列模型的实现,如DeepAR、Temporal Fusion Transformer等,方便用户进行基准测试和比较。
-
灵活性: 支持概率模型和状态空间模型,以及各种深度学习架构。
-
可扩展性: 设计目标是能够同样轻松地处理不同规模的数据集。通过流式处理数据而不是一次性加载到内存,实现了良好的可扩展性。
-
可重现性: 每个组件都可以序列化和存储,便于后续检查、检索和复现配置的模型和实验。
安装和使用
GluonTS可以通过pip轻松安装:
# 安装支持PyTorch模型的版本
pip install "gluonts[torch]"
# 安装支持MXNet模型的版本
pip install "gluonts[mxnet]"
使用GluonTS进行时间序列建模通常包括以下步骤:
- 数据准备: 将时间序列数据转换为GluonTS所需的格式。
- 模型选择: 选择合适的预训练模型或自定义模型。
- 模型训练: 使用训练数据集训练选定的模型。
- 预测: 使用训练好的模型对未来时间段进行预测。
- 评估: 使用内置的评估工具评估模型性能。
示例应用
让我们通过一个简单的例子来展示GluonTS的使用。我们将使用著名的"空乘客"数据集,训练一个DeepAR模型来预测未来的乘客数量。
import pandas as pd
import matplotlib.pyplot as plt
from gluonts.dataset.pandas import PandasDataset
from gluonts.dataset.split import split
from gluonts.torch import DeepAREstimator
# 加载数据
df = pd.read_csv(
"https://raw.githubusercontent.com/AileenNielsen/TimeSeriesAnalysisWithPython/master/data/AirPassengers.csv",
index_col=0,
parse_dates=True,
)
dataset = PandasDataset(df, target="#Passengers")
# 分割训练集和测试集
training_data, test_gen = split(dataset, offset=-36)
test_data = test_gen.generate_instances(prediction_length=12, windows=3)
# 训练模型并进行预测
model = DeepAREstimator(
prediction_length=12, freq="M", trainer_kwargs={"max_epochs": 5}
).train(training_data)
forecasts = list(model.predict(test_data.input))
# 绘制预测结果
plt.plot(df["1954":], color="black")
for forecast in forecasts:
forecast.plot()
plt.legend(["True values"], loc="upper left", fontsize="xx-large")
plt.show()
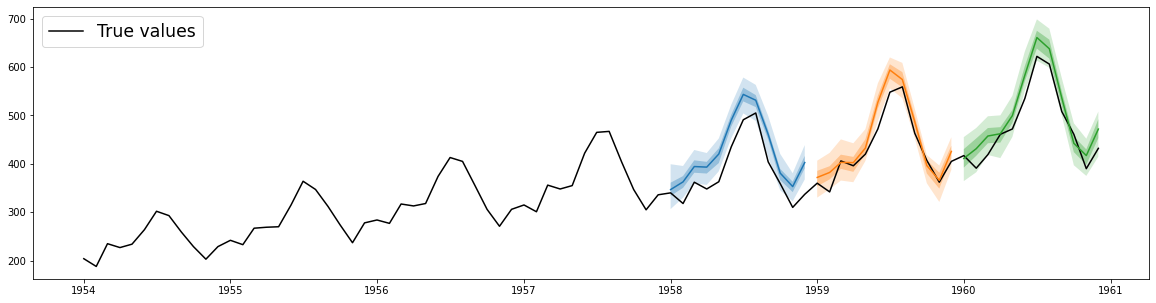
这个例子展示了GluonTS的强大功能。它能够轻松地处理时间序列数据,训练复杂的深度学习模型,并生成概率预测结果。预测结果以概率分布的形式呈现,阴影区域表示50%和90%的预测区间。
社区和贡献
GluonTS是一个开源项目,欢迎社区贡献。如果你想为项目做出贡献,可以参考GitHub仓库中的贡献指南。此外,项目还提供了详细的文档、教程和示例,帮助用户更好地理解和使用这个库。
结论
GluonTS为时间序列分析和预测提供了一个强大而灵活的工具集。无论是初学者还是经验丰富的数据科学家,都能从这个库中受益,快速构建和部署高质量的时间序列模型。随着时间序列数据在各个领域的重要性不断增加,GluonTS无疑将成为许多数据科学工作流程中不可或缺的一部分。










