
GPT4RoI简介
GPT4RoI (GPT for Region of Interest) 是一个基于大型语言模型的视觉-语言模型,由香港大学和上海人工智能实验室的研究人员开发。它的主要特点是可以理解图像中的特定区域(Region of Interest),并基于这些区域进行自然语言交互。
GPT4RoI的主要创新点在于:
-
支持语言和空间指令的交互方式,用户可以通过自然语言或坐标来指定感兴趣的图像区域。
-
支持单区域和多区域的空间指令,能够对图像中的一个或多个区域进行理解和推理。
-
具备强大的区域级多模态能力,可以生成详细的区域描述,进行复杂的区域推理等。
-
在视觉常识推理(VCR)数据集上达到了81.6%的准确率,远超其他模型,接近人类85%的水平。
🔗 相关资源
官方资源
模型权重
由于LLaMA的许可限制,GPT4RoI-7B的权重以delta形式发布:
需要与原始LLaMA-7B权重结合使用,具体步骤请参考GitHub仓库的说明。
数据集
GPT4RoI使用了以下数据集进行训练:
- RefCOCO, RefCOCO+, RefCOCOg
- Visual Genome
- Flickr30K entities
- VCR (Visual Commonsense Reasoning)
这些数据集的下载和组织方式可以在GitHub仓库的Data部分找到详细说明。
📚 学习指南
-
首先阅读论文,了解GPT4RoI的基本原理和架构。
-
查看GitHub仓库的README,熟悉项目结构和主要功能。
-
尝试在本地安装和运行GPT4RoI:
- 克隆仓库并安装依赖
- 下载并处理数据集
- 获取模型权重
- 运行训练和推理脚本
-
使用在线演示体验GPT4RoI的交互功能,加深理解。
-
深入研究代码,特别关注:
gpt4roi目录下的核心模型实现scripts目录下的训练和推理脚本configs目录下的配置文件
-
尝试在自己的数据上微调或使用GPT4RoI,探索更多应用场景。
🖼️ 模型架构
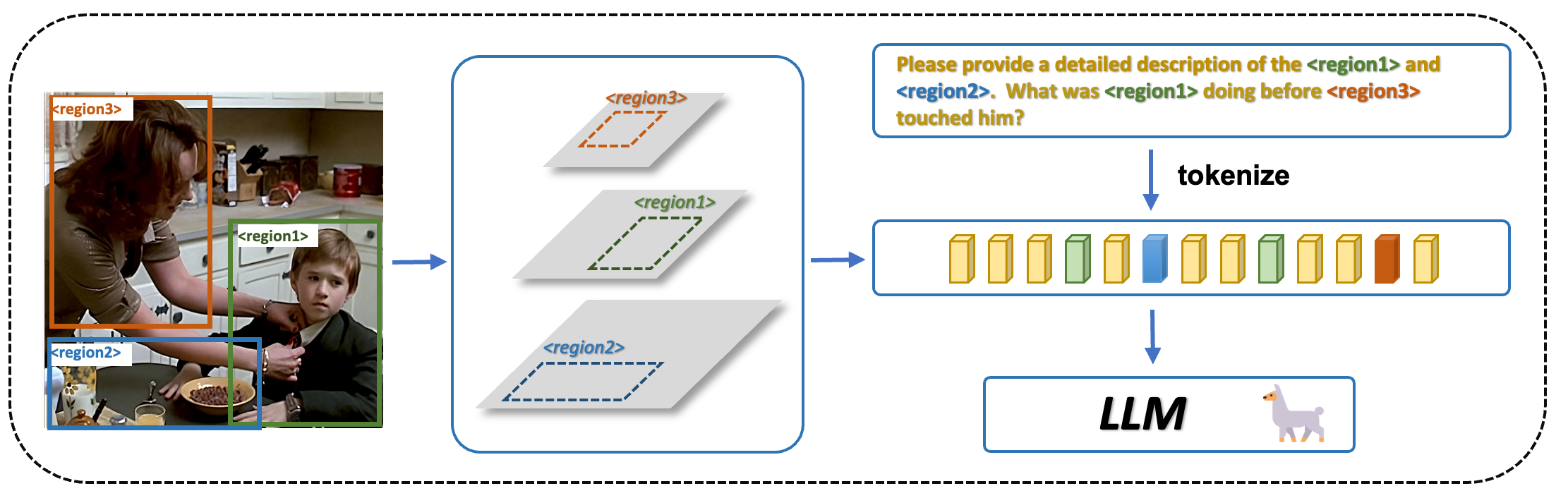
GPT4RoI的整体框架包括:
- 视觉编码器(ViT-H/14)
- 图像级特征投影器
- 区域特征提取器
- 大型语言模型(Vicuna-7B)
这些组件共同工作,实现了对图像区域的理解和自然语言交互。
🚀 未来展望
GPT4RoI为视觉-语言模型开辟了新的方向,但仍有改进空间:
- 提高对小区域和低分辨率图像的处理能力
- 扩充区域-文本对数据,提升模型性能
- 探索更多交互方式,如手势、语音等
研究者和开发者可以在这些方向上继续推动GPT4RoI的发展。
通过本文的资源汇总和学习指南,相信读者能够快速上手GPT4RoI,并在此基础上开展更多创新性的工作。欢迎探索这个强大的多模态AI模型,为计算机视觉和自然语言处理的结合贡献力量!










