GPT4Tools: 开启人机视觉交互新纪元
在人工智能快速发展的今天,如何让AI系统更好地理解和处理视觉信息,实现与人类的自然交互,一直是研究者们孜孜以求的目标。近期,由腾讯AI实验室、香港中文大学和清华大学联合开发的GPT4Tools系统,在这一领域取得了突破性进展。这个智能系统能够自动决策、控制和利用不同的视觉基础模型,让用户在对话过程中与图像进行自然交互,为多模态AI应用开辟了新的可能性。
GPT4Tools的核心理念与创新
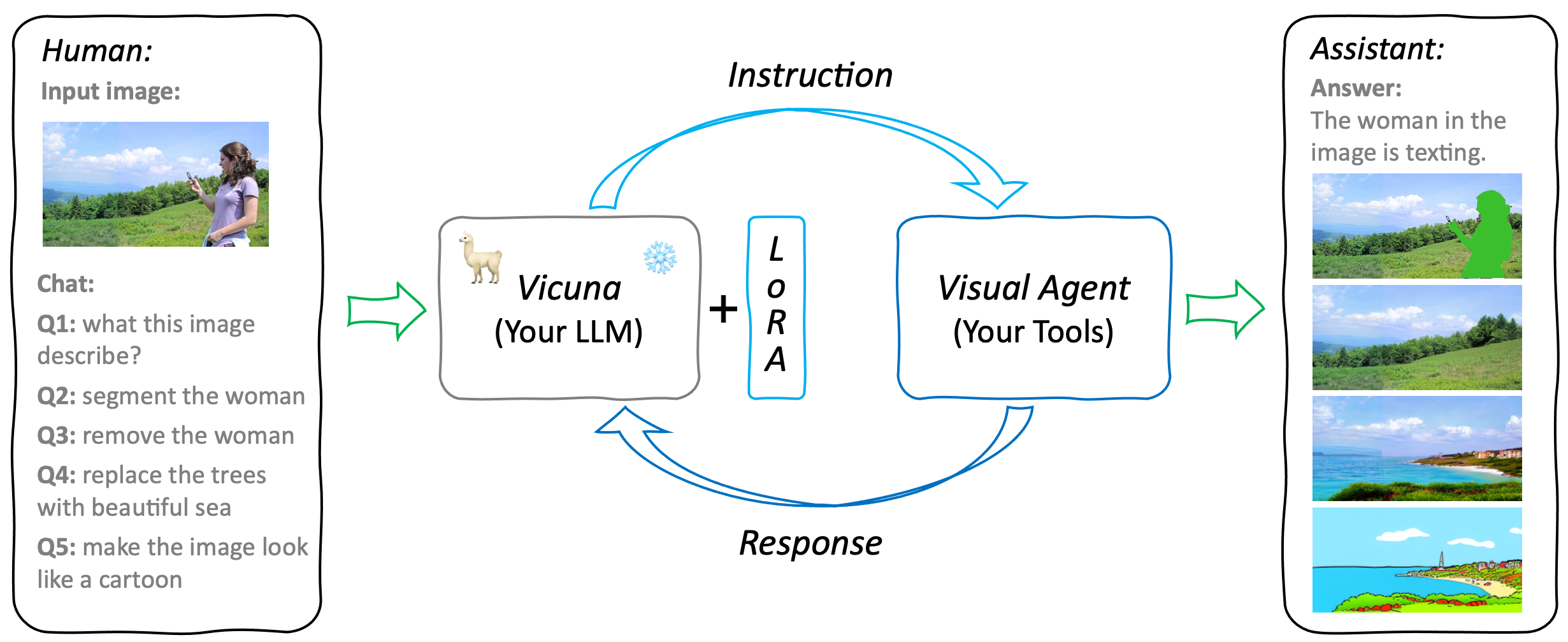
GPT4Tools的核心理念是通过"自我指导"(self-instruction)的方式,教会大语言模型(LLM)使用各种视觉工具。与传统方法不同,GPT4Tools支持用户通过简单的自我指导和低秩适应(LoRA)技术来训练自己的LLM使用工具,大大降低了多模态AI系统的开发门槛。
这个系统主要由三个部分组成:
- 用于指令理解的大语言模型(LLM)
- 用于模型适应的LoRA
- 用于提供各种视觉功能的Visual Agent
GPT4Tools的架构设计非常灵活和可扩展,用户可以轻松地替换现有的LLM或工具,或者向系统添加新的工具。唯一需要做的就是使用提供的指令对LoRA进行微调,从而教会LLM如何使用新的工具。
强大的数据集与训练方法
为了训练GPT4Tools,研究团队构建了一个包含71K条指令跟随信息的数据集。他们首先使用GPT-3.5模型,基于3K张图像的描述和22个视觉任务的说明,生成了66K条指令。经过去重和筛选,最终保留了41K条高质量指令。为了教会模型以预定义的方式使用工具,研究者们将这些指令转换成了对话格式。
这种数据构建方法不仅高效,而且能够生成多样化、高质量的训练样本,为GPT4Tools的强大性能奠定了基础。
GPT4Tools的核心功能
-
自动决策: GPT4Tools能够根据用户输入的自然语言指令,自动决定使用哪种视觉模型来处理任务。
-
多模型控制: 系统可以无缝控制多个视觉基础模型,包括图像分割、目标检测、图像生成等。
-
图像交互: 用户可以在对话过程中与图像进行自然交互,如修改、分析或生成新图像。
-
灵活扩展: 得益于其模块化设计,GPT4Tools可以方便地添加新的视觉工具或替换现有模型。
实际应用示例
GPT4Tools在多个视觉任务中展现出了卓越的性能。以下是一些具体的应用示例:
-
图像分割: 系统可以精确地识别和分割图像中的不同物体。
-
关键点检测: GPT4Tools能够准确定位图像中物体的关键点,如人体姿态估计。
-
问题解答: 基于图像内容,系统可以回答复杂的视觉问题。
-
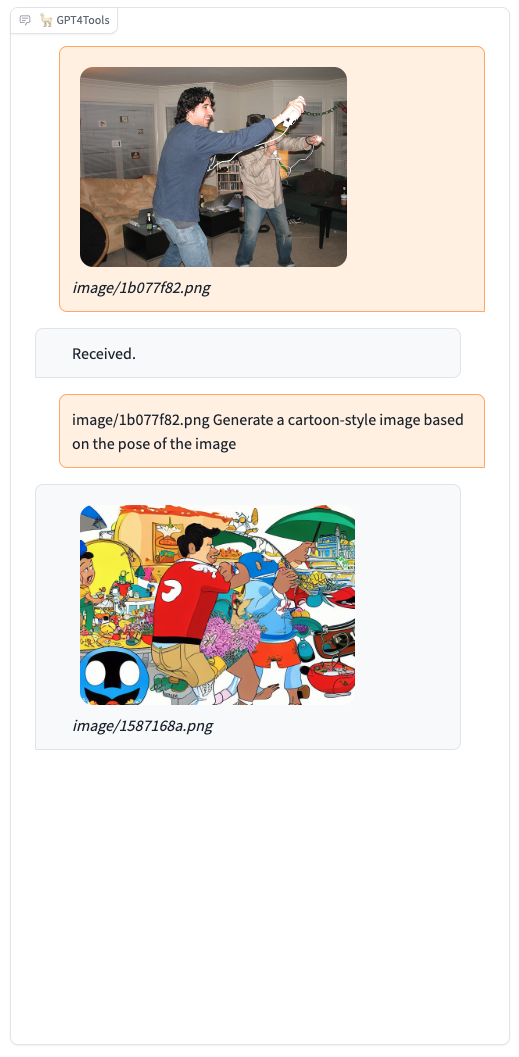
图像风格迁移: GPT4Tools可以将一张图片的风格应用到另一张图片上。
开源与社区贡献
GPT4Tools项目采用开源方式发布,这为整个AI社区带来了巨大价值。研究者们不仅公开了代码,还发布了预训练的模型权重和用于自我指导的数据集。这种开放态度极大地促进了技术的传播和改进。
目前,GPT4Tools已经在GitHub上获得了超过750颗星标,充分体现了社区对这一项目的关注和支持。研究团队也在持续更新项目,如最近就发布了适配vicuna-v1.5的新代码和模型。
未来展望
GPT4Tools的出现为多模态AI系统的发展指明了新的方向。随着更多研究者和开发者的加入,我们可以期待:
-
更多视觉工具的集成: 未来可能会有更多专业的视觉处理工具被整合到系统中。
-
跨模态理解能力的提升: 系统将更好地理解文本和图像之间的关系,实现更自然的人机交互。
-
实际应用场景的拓展: GPT4Tools有望在教育、医疗、设计等领域找到更多实际应用。
-
个性化定制: 用户可能可以根据特定需求,更容易地定制和训练自己的视觉交互系统。
结语
GPT4Tools的诞生标志着多模态AI系统进入了一个新的阶段。它不仅展示了令人印象深刻的技术能力,更重要的是为未来的研究和应用开辟了广阔的道路。随着技术的不断演进和完善,我们有理由相信,像GPT4Tools这样的智能系统将在不久的将来彻底改变人类与数字世界的交互方式,为各行各业带来革命性的变革。









