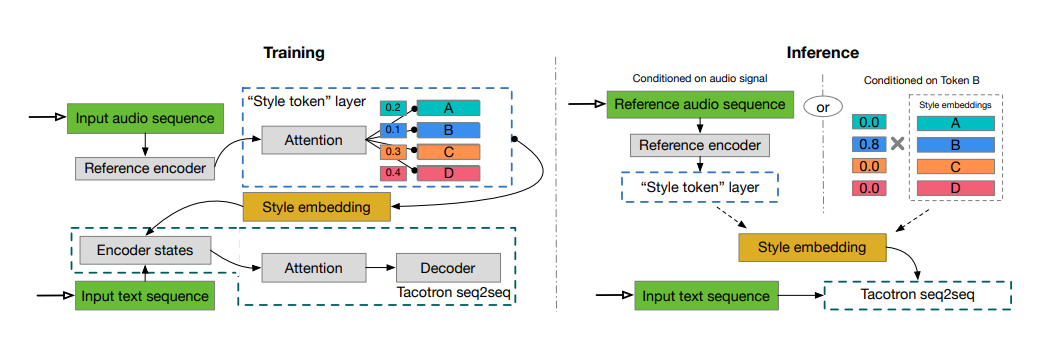
GST-Tacotron简介
GST-Tacotron是Google AI团队提出的一种端到端语音合成系统,在Tacotron的基础上引入了全局风格令牌(Global Style Tokens, GST)机制,实现了对语音风格的无监督建模、控制和迁移。该项目的主要特点包括:
- 无需显式标注就能学习建模大范围的语音表现力
- 可以通过控制GST实现语速、说话风格等的调节,独立于文本内容
- 支持风格迁移,将单个音频片段的说话风格复制到整个长文本语料中
- 在训练时使用噪声和无标注数据,可以学习分解噪声和说话人身份
学习资料
1. 论文
这是GST-Tacotron的原始论文,详细介绍了模型的设计思路和实验结果。
2. 代码实现
这是一个PyTorch版本的GST-Tacotron实现,包含了模型训练和推理的完整代码。
3. 示例与演示
这个页面提供了大量GST-Tacotron合成的音频样本,展示了模型在风格选择、风格缩放、风格迁移等方面的能力。
4. 相关教程
NVIDIA的OpenSeq2Seq框架中也实现了GST-Tacotron,这个教程详细介绍了如何使用该框架训练和推理GST-Tacotron模型。
深入学习
要深入理解GST-Tacotron,建议按以下步骤学习:
- 仔细阅读原始论文,理解模型的设计思路和创新点
- 查看GitHub代码实现,了解模型的具体结构和训练过程
- 听取音频样本,感受GST-Tacotron的风格建模和控制能力
- 尝试使用开源实现训练自己的模型
通过以上资料和步骤,相信读者可以全面掌握GST-Tacotron的原理和应用。如果在学习过程中遇到问题,欢迎在相关项目的GitHub Issues中讨论交流。