
Hbox简介
Hbox是由奇虎360公司开发的一个创新型调度平台,它巧妙地将大数据技术与人工智能相结合,为用户提供了一个便捷高效的AI应用开发和运行环境。作为一个运行在Hadoop Yarn之上的平台,Hbox集成了多种主流的机器学习和深度学习框架,包括TensorFlow、MXNet、Caffe、Theano、PyTorch、Keras、XGBoost等,同时还支持GPU资源调度、Docker容器化运行以及RESTful API管理接口。

Hbox的设计理念是为AI开发者提供一个统一的、易用的、可扩展的平台,使他们能够更加专注于算法和模型的开发,而无需过多关注底层资源管理和调度的复杂性。通过Hbox,用户可以轻松地在Hadoop集群上运行各种AI任务,充分利用集群的计算资源,提高开发效率和资源利用率。
Hbox架构设计
Hbox的架构设计简洁而高效,主要包含三个核心组件:
-
Client: 负责启动应用程序并获取应用状态。用户通过Client提交任务到Hbox平台。
-
ApplicationMaster(AM): 作为内部调度和生命周期管理的核心,AM负责输入数据分发和容器管理。它是连接Client和Container的桥梁,确保任务的正确执行。
-
Container: 作为应用程序的实际执行者,Container负责启动Worker或PS(Parameter Server)进程,监控并向AM报告进程状态,保存输出结果。对于TensorFlow应用,Container还会启动TensorBoard服务以便实时查看训练过程。
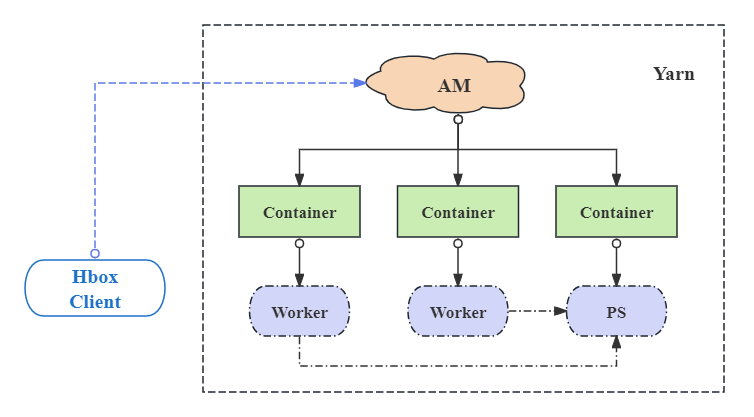
这种架构设计使得Hbox能够灵活地适应不同规模的集群和各种类型的AI任务,同时保证了系统的可扩展性和稳定性。
Hbox主要功能特性
1. 支持多种深度学习框架
Hbox的一大亮点是其对多种深度学习框架的广泛支持。除了支持TensorFlow和MXNet的分布式模式外,Hbox还支持Caffe、Theano、PyTorch等框架的单机模式。更重要的是,Hbox允许用户灵活地使用自定义版本和多版本的框架,这为研究人员和开发者提供了极大的便利。
2. 基于HDFS的统一数据管理
Hbox充分利用了Hadoop生态系统的优势,将训练数据和模型结果统一存储在HDFS(也支持S3)中。这种设计不仅简化了数据管理,还提高了数据访问的效率。Hbox提供了三种输入数据读取策略:
- Download: AM遍历指定HDFS路径下的所有文件,并将数据以文件为单位分发给workers。
- Placeholder: 与Download模式类似,但AM只发送相关HDFS文件列表给workers,由worker进程直接从HDFS读取数据。
- InputFormat: 集成了MapReduce的InputFormat功能,允许用户指定任何InputFormat实现来读取输入数据。
同样,Hbox也提供了两种输出策略:
- Upload: 程序结束后,每个worker直接将本地输出目录上传到指定的HDFS路径。
- OutputFormat: 集成了MapReduce的OutputFormat功能,允许用户指定任何OutputFormat实现来保存结果到HDFS。
这种灵活的数据管理机制使得Hbox能够高效地处理各种规模和类型的数据集。
3. 可视化展示
Hbox提供了直观的Web界面,让用户能够实时监控和管理任务执行状态。界面主要分为四个部分:
- All Containers: 显示容器列表及相关信息,包括容器主机、角色、当前状态、启动时间、结束时间和当前进度。
- View TensorBoard: 对于TensorFlow应用,提供TensorBoard服务的链接,方便实时查看训练过程。
- Save Model: 允许用户在应用执行过程中上传中间输出到指定HDFS路径。
- Worker Metrics: 展示每个worker的资源使用情况指标。
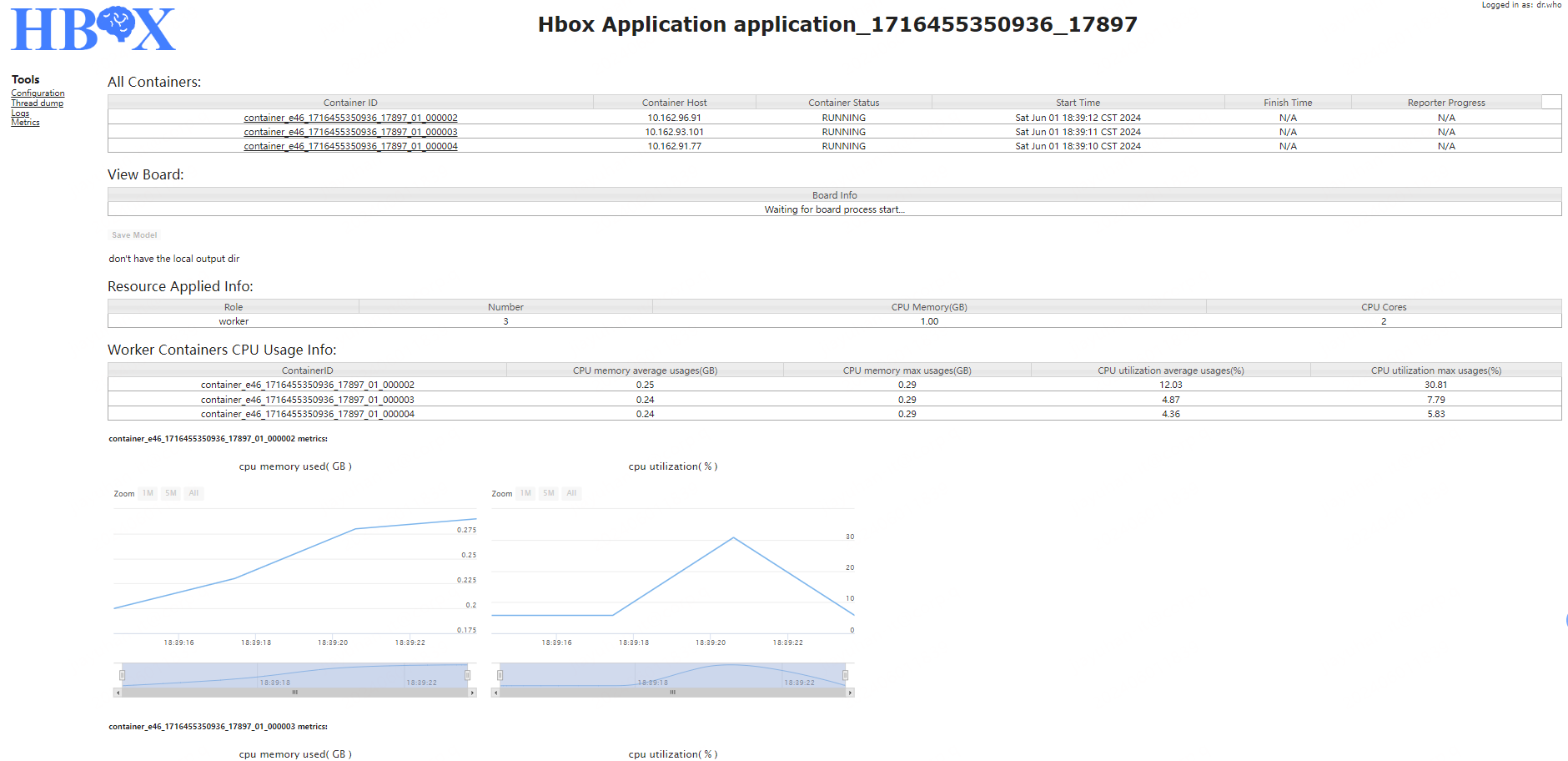
这种可视化界面大大提高了用户对任务执行状态的掌控能力,有助于及时发现和解决问题。
4. 兼容原生框架代码
Hbox的另一个重要特性是其对原生框架代码的兼容性。除了自动构建分布式TensorFlow的ClusterSpec外,其他深度学习框架的单机模式程序可以直接在Hbox上执行,无需修改代码。这种兼容性极大地降低了用户的学习成本和迁移难度。
Hbox的编译与部署
编译环境要求
- JDK >= 1.8
- Maven >= 3.6.3
编译方法
在源代码根目录下运行以下命令:
./mvnw package
编译完成后,在根目录的core/target下会生成名为hbox-1.1-dist.tar.gz的分发包。解压后,会在根目录下生成以下子目录:
- bin: 管理应用作业的脚本
- sbin: 历史服务的脚本
- lib: 依赖jar包
- libexec: 通用脚本和hbox-site.xml配置示例
- hbox-*.jar: HBox的jar包
部署环境要求
- CentOS 7.2
- Java >= 1.8
- Hadoop = 2.6 -- 3.2 (GPU要求3.1+)
- [可选] 集群节点上深度学习框架的依赖环境,如TensorFlow、numpy、Caffe等
Hbox客户端部署指南
在解压后的分发包的"conf"目录下,配置相关文件:
- hbox-env.sh: 设置环境变量,如JAVA_HOME和HADOOP_CONF_DIR
- hbox-site.xml: 配置相关属性,注意历史服务相关的属性需要与历史服务启动时的配置保持一致
- log4j.properties: 配置日志级别
Hbox历史服务启动方法 [可选]
运行 $HBOX_HOME/sbin/start-history-server.sh
Hbox快速入门
使用 $HBOX_HOME/bin/hbox-submit 在Hbox客户端提交应用到集群。以下是一个TensorFlow应用的提交示例:
1. 上传数据到HDFS
cd $HBOX_HOME
hadoop fs -put data /tmp/
2. 提交任务
cd $HBOX_HOME/examples/tensorflow
$HBOX_HOME/bin/hbox-submit \
--app-type "tensorflow" \
--app-name "tf-demo" \
--input /tmp/data/tensorflow#data \
--output /tmp/tensorflow_model#model \
--files demo.py,dataDeal.py \
--worker-memory 10G \
--worker-num 2 \
--worker-cores 3 \
--ps-memory 1G \
--ps-num 1 \
--ps-cores 2 \
--queue default \
python demo.py --data_path=./data --save_path=./model --log_dir=./eventLog --training_epochs=10
这个命令示例展示了Hbox强大的任务配置能力,用户可以精细地控制资源分配、数据输入输出、执行环境等多个方面。
结语
Hbox作为一个创新型的AI调度平台,为大数据和人工智能的融合提供了一个强大的解决方案。它不仅简化了AI应用的开发和部署流程,还提高了集群资源的利用效率。通过支持多种深度学习框架、统一的数据管理、直观的可视化界面以及与原生框架的兼容性,Hbox为AI研究人员和开发者提供了一个全面而灵活的工作环境。
随着AI技术的不断发展和大数据应用的日益广泛,像Hbox这样的平台将在推动技术创新和提高生产效率方面发挥越来越重要的作用。我们期待看到更多基于Hbox的创新应用和突破性研究成果的出现。
如果您对Hbox感兴趣,可以访问其GitHub仓库了解更多信息,或者加入Hbox的QQ交流群与其他开发者交流经验。让我们一起探索Hbox的无限可能,推动AI技术的进步与应用!












{kind=link}