
HDBSCAN算法简介
HDBSCAN(Hierarchical Density-Based Spatial Clustering of Applications with Noise)是一种高效的密度聚类算法,由Campello、Moulavi和Sander于2013年提出。它是DBSCAN算法的扩展版本,通过将DBSCAN转化为层次聚类算法,并使用基于聚类稳定性的技术来提取平面聚类结果。
HDBSCAN的主要优势在于:
- 能够发现任意形状的聚类
- 可以处理不同密度的数据分布
- 对噪声和异常值具有较强的鲁棒性
- 参数调整简单直观
这些特性使HDBSCAN成为数据探索和分析的理想选择,能够快速可靠地发现数据中有意义的聚类结构(如果存在的话)。
HDBSCAN的工作原理
密度估计
HDBSCAN的核心思想是基于数据的密度分布来进行聚类。它通过估计每个数据点的局部密度来识别高密度区域和低密度区域。具体来说,HDBSCAN使用"核心距离"(core distance)的概念来估计局部密度:
- 对于每个数据点,计算到第k个最近邻居的距离,称为核心距离。
- 核心距离越小,表示该点周围的局部密度越高。
这种方法可以有效地估计多维空间中的密度分布,而不需要显式地计算概率密度函数。
相互可达性距离
在密度估计的基础上,HDBSCAN引入了"相互可达性距离"(mutual reachability distance)的概念,用于衡量两个点之间的密度感知距离:
mutual_reachability_distance(a, b) = max(
core_distance(a),
core_distance(b),
distance(a, b)
)
这个距离度量考虑了两个点各自的局部密度以及它们之间的实际距离,能够更好地反映数据的密度结构。
构建层次结构
HDBSCAN使用相互可达性距离构建一个最小生成树,然后将这个树转化为聚类层次结构:
- 从最高密度水平开始,逐步降低密度阈值。
- 在每个密度水平,连接满足密度条件的点,形成聚类。
- 随着密度阈值的降低,聚类会逐渐合并,形成一个层次结构。
这个过程可以通过一个树状图(dendrogram)来可视化,展示了聚类是如何随密度变化而形成和合并的。

提取稳定聚类
HDBSCAN不是简单地在某个密度水平上切割层次结构,而是通过评估聚类的稳定性来选择最终的聚类结果:
- 计算每个聚类在不同密度水平下的持续性(persistence)。
- 选择具有最大总持续性的非重叠聚类集合。
这种方法能够自动确定聚类的数量,并且可以发现不同尺度和密度的聚类。
HDBSCAN的实现和使用
HDBSCAN算法有多种实现,其中最流行的是Python的hdbscan库。这个库提供了高性能的HDBSCAN实现,并与scikit-learn兼容。
基本用法
使用hdbscan库进行聚类非常简单:
import hdbscan
from sklearn.datasets import make_blobs
# 生成示例数据
data, _ = make_blobs(1000)
# 创建HDBSCAN聚类器
clusterer = hdbscan.HDBSCAN(min_cluster_size=10)
# 拟合数据并预测聚类标签
cluster_labels = clusterer.fit_predict(data)
关键参数
HDBSCAN算法的主要参数是:
min_cluster_size: 最小聚类大小,控制了聚类的粒度。min_samples: 用于计算核心距离的样本数,影响密度估计的稳定性。cluster_selection_epsilon: 控制最终聚类提取的阈值。
这些参数相对直观,通常不需要大量调优就能得到合理的结果。
可视化和分析
hdbscan库提供了多种可视化工具,帮助理解聚类结果:
- 聚类树图:展示聚类层次结构。
- 凝聚树图:显示聚类的形成和合并过程。
- 单连通树图:展示数据的密度结构。
# 绘制凝聚树图
clusterer.condensed_tree_.plot()
这些可视化工具对于调整参数和解释结果非常有帮助。
HDBSCAN的优势和应用
与其他聚类算法的比较
相比传统的K-means或DBSCAN算法,HDBSCAN具有以下优势:
- 无需预先指定聚类数量。
- 能够处理任意形状的聚类。
- 对噪声和异常值更加鲁棒。
- 可以发现不同密度的聚类。
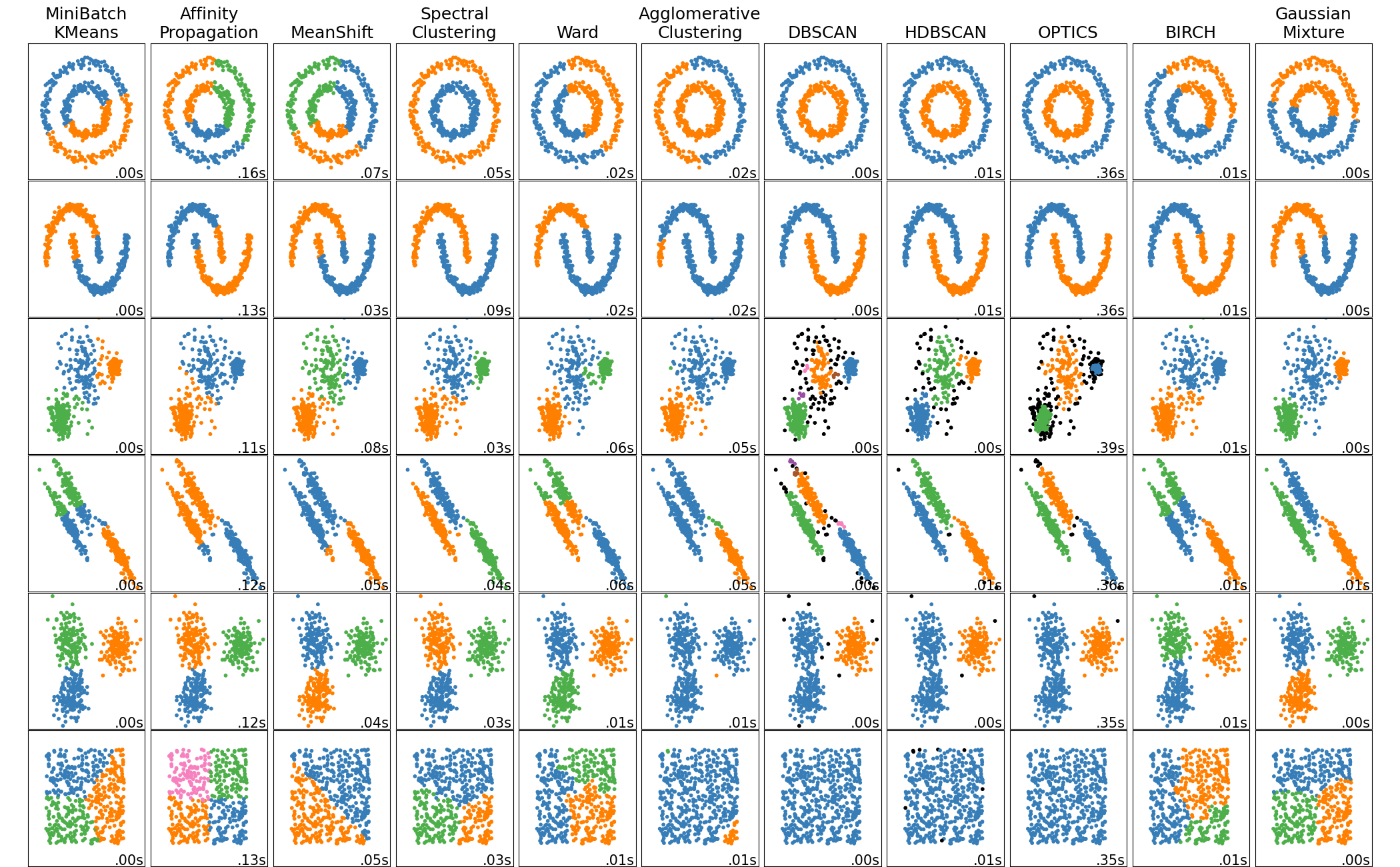
应用领域
HDBSCAN在多个领域都有广泛应用:
- 客户分群:识别具有相似行为模式的客户群体。
- 异常检测:发现数据中的异常点或离群值。
- 图像分割:在计算机视觉中用于图像分割任务。
- 生物信息学:分析基因表达数据,发现功能相关的基因群。
- 地理空间分析:识别地理位置数据中的热点区域。
HDBSCAN的扩展和优化
加速技术
为了提高HDBSCAN的性能,研究人员提出了多种加速技术:
- 近似最近邻搜索:使用树结构或哈希技术加速距离计算。
- 核心距离近似:通过采样或降维来加速核心距离的计算。
- 并行化:利用多核处理器或GPU加速计算。
这些技术使HDBSCAN能够处理更大规模的数据集。
软聚类和成员度
HDBSCAN还支持软聚类,为每个数据点分配聚类成员度:
# 获取软聚类结果
soft_clusters = clusterer.probabilities_
这提供了聚类结果的不确定性信息,对于边界模糊的数据点特别有用。
分支检测
最近的研究扩展了HDBSCAN,增加了分支检测功能。这允许识别聚类中的分支结构,揭示更复杂的数据模式:
from hdbscan import BranchDetector
branch_detector = BranchDetector().fit(clusterer)
branch_detector.cluster_approximation_graph_.plot(edge_width=0.1)
这个功能对于分析具有层次或进化结构的数据集特别有用。
结论
HDBSCAN作为一种强大的密度聚类算法,在处理复杂、高维数据时表现出色。它的自适应性、对噪声的鲁棒性以及直观的参数使其成为数据科学家和研究人员的首选工具之一。随着算法的不断优化和新功能的加入,HDBSCAN在未来的数据分析和机器学习领域将发挥越来越重要的作用。
无论是进行探索性数据分析,还是构建复杂的机器学习管道,HDBSCAN都是一个值得考虑的聚类算法。通过深入理解其原理和使用方法,我们可以更好地利用这个强大的工具,从复杂的数据中发现有价值的洞察。









