
Hiera: 重新定义层级视觉Transformer
Hiera是Facebook AI研究院最新推出的一种层级视觉Transformer模型,它以其出色的性能和简洁的设计引起了广泛关注。作为ICML 2023会议的口头报告论文,Hiera展示了如何通过创新的架构设计和训练策略,在不增加复杂度的情况下显著提升视觉Transformer的性能。
🚀 Hiera的核心创新
Hiera的设计哲学可以概括为"less is more"。与之前复杂的层级Transformer模型不同,Hiera通过简化架构和优化训练方法,实现了更高的效率和准确性:
-
层级结构: Hiera采用类似ResNet的层级设计,在网络的不同阶段逐步减少空间分辨率和增加特征维度。这种结构能更好地平衡计算资源,提高模型效率。
-
简化设计: Hiera移除了许多常见的"bells and whistles"(花哨的模块),如相对位置编码、局部注意力等。这不仅简化了模型结构,还降低了计算复杂度。
-
MAE预训练: Hiera使用Masked Autoencoder (MAE)进行自监督预训练。这种方法能帮助模型学习到更强的空间偏置,无需显式地在架构中加入复杂的空间感知模块。
-
标准化像素目标: 在MAE预训练中,Hiera对每个图像块进行单独的归一化处理。这种方法提高了预训练的效果,使模型能更好地学习图像的局部特征。
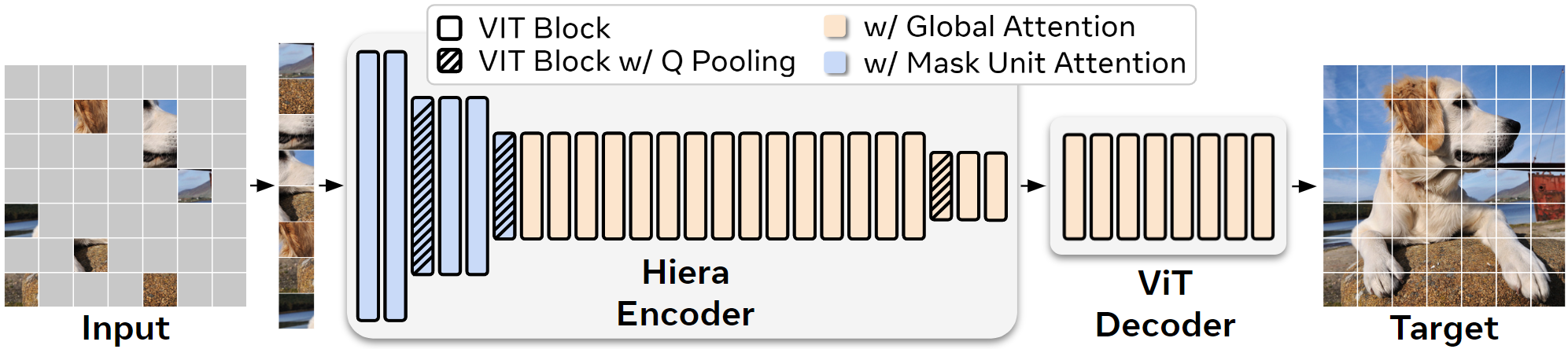
💪 卓越的性能表现
Hiera在多个视觉任务上展现出了优异的性能:
-
图像分类: 在ImageNet-1K数据集上,Hiera-H模型达到了86.9%的Top-1准确率,超越了许多更复杂的模型。
-
视频理解: 在Kinetics-400数据集上,Hiera-H模型实现了87.8%的Top-1准确率,展示了其在时空建模方面的强大能力。
-
推理速度: Hiera模型在保持高精度的同时,推理速度明显快于同类模型。例如,Hiera-B在A100 GPU上的推理速度可达1556 images/s。
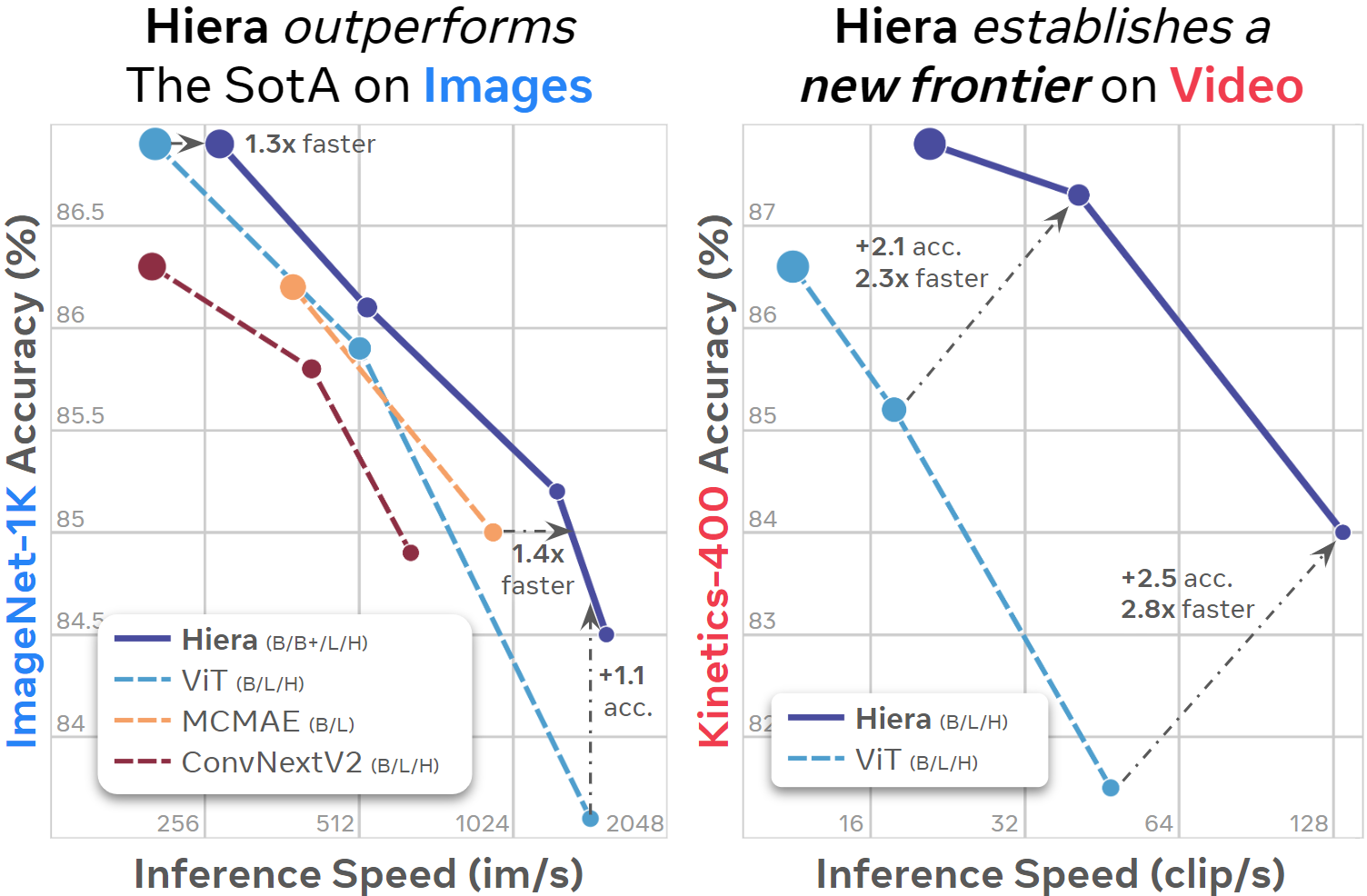
🛠️ 使用和部署Hiera
Hiera的使用非常简单直观。研究者和开发者可以通过以下方式快速上手:
-
安装: 通过pip安装Hiera包:
pip install hiera-transformer -
模型加载: 使用torch hub或Hugging Face hub加载预训练模型:
import torch model = torch.hub.load("facebookresearch/hiera", model="hiera_base_224", pretrained=True, checkpoint="mae_in1k_ft_in1k") -
推理: Hiera的使用方式与标准的PyTorch模型相同:
output = model(input_tensor) -
MAE预训练: 如果需要使用MAE解码器或计算MAE损失,可以加载包含解码器的版本:
model = hiera.mae_hiera_base_224(pretrained=True, checkpoint="mae_in1k")
🌟 未来展望
Hiera的成功为视觉Transformer的发展指明了新的方向。它证明了通过合理的设计和训练策略,可以在不增加模型复杂度的情况下显著提升性能。未来,我们可以期待:
-
更多下游任务: Hiera在图像分类和视频理解任务上表现出色,未来有望在目标检测、语义分割等更多视觉任务中发挥作用。
-
跨模态应用: Hiera的简洁高效特性使其有潜力应用于视觉-语言等跨模态任务。
-
移动端部署: 得益于其高效的设计,Hiera可能在移动设备等计算资源受限的场景中找到更多应用。
-
进一步的架构优化: Hiera的成功可能激发更多关于如何简化和优化Transformer架构的研究。
📚 结语
Hiera的出现为计算机视觉领域带来了新的可能性。它不仅在性能上超越了现有模型,更重要的是展示了"简单却高效"的设计理念。对于研究人员和工程师来说,Hiera提供了一个强大而灵活的工具,有望推动视觉AI技术在更多领域的应用和创新。
随着深度学习模型越来越复杂,Hiera的成功或许预示着一个新的趋势:通过智慧的设计和训练策略,而不是简单地堆叠更多层或增加参数,来提升模型性能。这种方法不仅能带来更高的效率,还可能帮助我们更好地理解和解释深度学习模型的工作原理。
对于想要深入了解或使用Hiera的读者,可以访问Hiera的GitHub仓库获取更多信息和资源。让我们期待Hiera在未来能为计算机视觉领域带来更多突破和创新。









