
Horovod:高效易用的分布式深度学习训练框架
Horovod是一个由Uber开发并开源的分布式深度学习训练框架,目前由Linux Foundation AI & Data基金会托管。它支持TensorFlow、Keras、PyTorch和Apache MXNet等主流深度学习框架,旨在让分布式深度学习变得快速而简单。
Horovod的主要特点
-
易用性:只需几行代码就可以将单GPU训练脚本扩展到多GPU分布式训练。
-
高性能:采用ring-allreduce算法,可以高效地进行梯度聚合,在大规模集群上也能保持较高的扩展性。
-
灵活性:支持多种深度学习框架,可以在CPU、GPU或混合环境下运行。
-
可移植性:同一套代码可以在单机多卡、多机多卡等不同环境下运行,无需修改。
-
自动调优:提供自动性能调优功能,可以自动优化参数以获得最佳性能。
Horovod的工作原理
Horovod的核心原理是基于MPI(消息传递接口)的概念,主要包括:
-
初始化:调用
hvd.init()初始化Horovod环境。 -
梯度平均:使用
hvd.DistributedOptimizer包装优化器,在反向传播时自动进行梯度的all-reduce操作。 -
广播初始状态:使用
hvd.BroadcastGlobalVariablesHook确保所有worker的初始模型参数一致。 -
调整学习率:根据worker数量调整学习率,以适应有效batch size的增加。
通过这些操作,Horovod可以高效地协调多个GPU或多台机器上的训练过程。
Horovod的性能优势
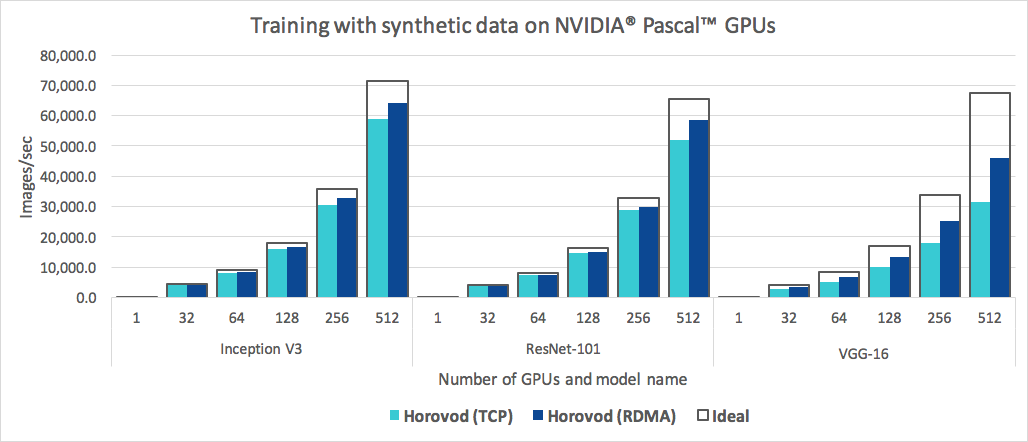
上图展示了Horovod在512个GPU上的扩展性能。可以看到,对于Inception V3和ResNet-101模型,Horovod能够达到90%的扩展效率,而对于VGG-16模型也能达到68%的扩展效率。这说明Horovod在大规模分布式训练中具有出色的性能表现。
如何使用Horovod
使用Horovod进行分布式训练非常简单,只需要对现有的单GPU训练脚本做少量修改:
- 导入Horovod并初始化:
import horovod.tensorflow as hvd
hvd.init()
- 将优化器包装成分布式优化器:
opt = tf.train.AdamOptimizer(0.001 * hvd.size())
opt = hvd.DistributedOptimizer(opt)
- 广播初始变量:
hooks = [hvd.BroadcastGlobalVariablesHook(0)]
- 调整学习率:
opt = tf.train.AdamOptimizer(0.001 * hvd.size())
- 只在主进程上保存检查点:
if hvd.rank() == 0:
checkpoint.save(...)
通过这些简单的修改,就可以将单GPU训练脚本转换为分布式训练脚本。
运行Horovod
Horovod提供了horovodrun命令来启动分布式训练作业。例如,要在4台机器上各使用4个GPU进行训练,可以使用以下命令:
horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python train.py
Horovod还支持在Kubernetes、Spark、Ray等各种环境中运行,具有很强的灵活性和适应性。
Horovod的高级特性
-
Tensor Fusion:可以将小的allreduce操作批量处理,提高通信效率。
-
Timeline:可以记录Horovod的活动时间线,用于性能分析。
-
自动调优:可以自动优化Tensor Fusion等参数以获得最佳性能。
-
Process Sets:支持在不同的进程组中并发运行不同的集合通信操作。
这些高级特性使得Horovod能够在各种复杂场景下都能获得出色的性能表现。
总结
Horovod作为一个高效易用的分布式深度学习训练框架,极大地简化了分布式训练的复杂性,同时又能保持出色的性能。无论是在学术研究还是工业应用中,Horovod都是一个值得考虑的强大工具。随着深度学习模型规模的不断增长和分布式训练需求的增加,Horovod必将在未来的AI领域发挥更加重要的作用。










