
HQQ: 革命性的模型量化技术
在人工智能和机器学习领域,模型量化一直是一个重要的研究方向。随着模型规模的不断扩大,如何在有限的计算资源下高效部署大型模型成为了一个亟待解决的问题。近日,由Mobius Labs开发的Half-Quadratic Quantization (HQQ)技术为这一难题提供了一个创新的解决方案。
HQQ的核心优势
HQQ是一种快速且精确的模型量化器,其最大的特点是无需校准数据。这意味着即使是最大规模的模型,也可以在短短几分钟内完成量化。🚀 相比传统的量化方法,HQQ具有以下显著优势:
- 极快的量化速度
- 支持1-8比特的灵活量化
- 适用于各种模型类型(LLMs、视觉模型等)
- 反量化步骤为线性操作,兼容多种优化CUDA/Triton内核
- 与PEFT训练兼容
- 努力实现与
torch.compile的全面兼容,以加速推理和训练
量化质量与速度
HQQ团队在语言和视觉模型上进行了详细的基准测试。根据他们的博客文章,HQQ在保持模型性能的同时,显著降低了模型的大小和计算需求。
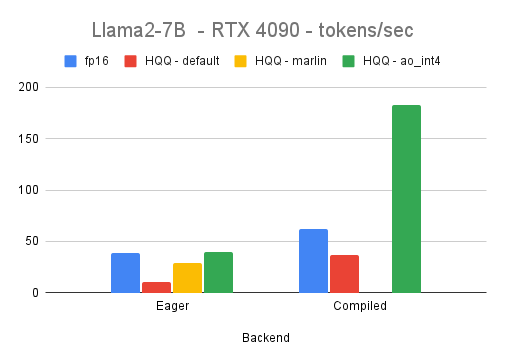
在速度方面,使用axis=1的4比特模型可以利用优化的推理融合内核,如torchao的int4_gemm。这与gpt-fast项目使用的是相同的内核,根据基准测试,目前是最快的可用内核。此外,HQQ还支持Marlin内核,并致力于与torch.compile完全兼容,以进一步提高训练和推理速度。
量化设置建议
对于初次使用HQQ的用户,建议从以下设置开始:
nbits=4, group_size=64, axis=1
这些设置在质量、VRAM使用和速度之间提供了良好的平衡。如果希望在相同VRAM使用下获得更好的结果,可以切换到axis=0并使用ATEN后端。对于更低比特(如nbits=2)的量化,应使用axis=0和较小的group-size,通过HQQ+添加低秩适配器,并使用小数据集进行微调。
安装与基本使用
HQQ的安装非常简单,首先确保您有与CUDA版本匹配的PyTorch 2版本,然后可以通过pip安装:
pip install hqq
要使用HQQ进行量化,只需替换线性层(torch.nn.Linear)即可:
from hqq.core.quantize import *
# 量化设置
quant_config = BaseQuantizeConfig(nbits=4, group_size=64)
# 替换线性层
hqq_layer = HQQLinear(your_linear_layer,
quant_config=quant_config,
compute_dtype=torch.float16,
device='cuda',
initialize=True,
del_orig=True)
与Transformers的集成
HQQ可以与Hugging Face的Transformers库无缝集成。以下是一个简单的示例:
from transformers import AutoModelForCausalLM, HqqConfig
# 所有线性层将使用相同的量化配置
quant_config = HqqConfig(nbits=4, group_size=64)
# 加载并量化模型
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="cuda",
quantization_config=quant_config
)
自定义量化配置
HQQ允许为不同的层设置不同的量化配置,这为模型优化提供了更大的灵活性:
q4_config = {'nbits':4, 'group_size':64}
q3_config = {'nbits':3, 'group_size':32}
quant_config = HqqConfig(dynamic_config={
'self_attn.q_proj':q4_config,
'self_attn.k_proj':q4_config,
'self_attn.v_proj':q4_config,
'self_attn.o_proj':q4_config,
'mlp.gate_proj':q3_config,
'mlp.up_proj' :q3_config,
'mlp.down_proj':q3_config,
})
PEFT训练支持
HQQ还支持参数高效微调(PEFT)训练。用户可以直接使用Hugging Face的peft库,或者使用HQQ提供的PEFT工具:
from hqq.core.peft import PeftUtils
base_lora_params = {'lora_type':'default', 'r':32, 'lora_alpha':64, 'dropout':0.05, 'train_dtype':torch.float32}
lora_params = {'self_attn.q_proj': base_lora_params,
'self_attn.k_proj': base_lora_params,
'self_attn.v_proj': base_lora_params,
'self_attn.o_proj': base_lora_params,
'mlp.gate_proj' : None,
'mlp.up_proj' : None,
'mlp.down_proj' : None}
# 添加LoRA到线性/HQQ模块
PeftUtils.add_lora(model, lora_params)
结论
HQQ为大型机器学习模型的量化提供了一个强大而灵活的解决方案。它不仅能显著减少模型的存储和计算需求,还能保持模型的性能。对于研究人员和工程师来说,HQQ提供了一种高效部署大型模型的新方法,有望推动AI技术在更多领域的应用和发展。
随着AI模型规模的不断增长,像HQQ这样的技术将在未来扮演越来越重要的角色。它不仅能够使更多人有机会使用和研究大型模型,还能推动AI技术向更节能、更环保的方向发展。我们期待看到HQQ在未来的进一步发展,以及它在各种应用场景中的表现。












