Imagen-PyTorch:开启文本到图像生成的新纪元
在人工智能和计算机视觉领域,文本到图像生成一直是一个充满挑战和机遇的研究方向。随着Google推出Imagen模型,这一领域迎来了新的突破。本文将深入介绍Imagen-PyTorch项目,这是一个在PyTorch框架下实现Imagen模型的开源项目,为研究人员和开发者提供了探索和应用这一前沿技术的平台。
Imagen模型简介
Imagen是由Google研究团队开发的文本到图像生成模型,它在图像质量和文本对齐方面都取得了显著的进步,超越了此前的DALL-E2模型。Imagen的核心是一个级联的扩散模型(cascading diffusion model),它由多个U-Net网络组成,每个网络负责不同分辨率的图像生成。
Imagen的架构相对简单,主要包含以下几个关键组件:
- 文本编码器:使用预训练的T5模型将输入文本转换为嵌入向量。
- 条件扩散模型:一系列U-Net网络,逐步从噪声中生成越来越高分辨率的图像。
- 动态裁剪:用于改善分类器自由引导(classifier-free guidance)的效果。
- 噪声级别条件:提高模型对不同噪声水平的适应能力。
- 内存高效的U-Net设计:优化模型的内存使用。
Imagen-PyTorch项目概览
Imagen-PyTorch项目由Phil Wang (@lucidrains) 开发,旨在提供Imagen模型的PyTorch实现。该项目不仅复现了原始Imagen模型的核心功能,还引入了一些创新和改进,使其更易于使用和扩展。
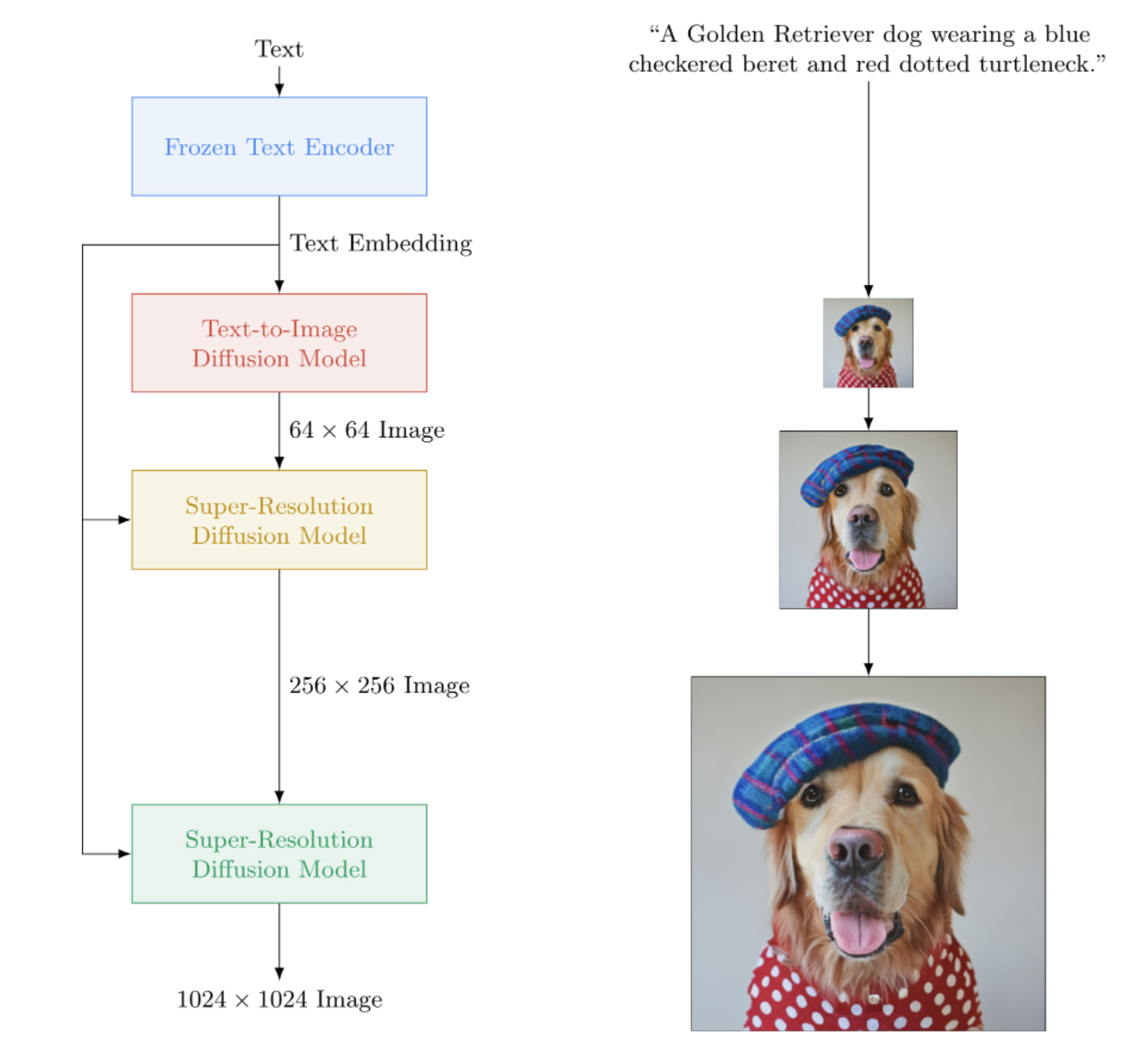
项目的主要特点包括:
- 完整的Imagen模型实现
- 灵活的配置选项
- 多GPU训练支持
- 命令行界面(CLI)工具
- 实验性功能,如Elucidated Imagen和文本到视频生成
使用Imagen-PyTorch
要开始使用Imagen-PyTorch,首先需要安装该库:
pip install imagen-pytorch
接下来,我们可以通过以下代码示例来创建和使用Imagen模型:
import torch
from imagen_pytorch import Unet, Imagen
# 创建U-Net模型
unet1 = Unet(
dim = 32,
cond_dim = 512,
dim_mults = (1, 2, 4, 8),
num_resnet_blocks = 3,
layer_attns = (False, True, True, True),
layer_cross_attns = (False, True, True, True)
)
unet2 = Unet(
dim = 32,
cond_dim = 512,
dim_mults = (1, 2, 4, 8),
num_resnet_blocks = (2, 4, 8, 8),
layer_attns = (False, False, False, True),
layer_cross_attns = (False, False, False, True)
)
# 创建Imagen模型
imagen = Imagen(
unets = (unet1, unet2),
image_sizes = (64, 256),
timesteps = 1000,
cond_drop_prob = 0.1
).cuda()
# 模拟文本嵌入和图像数据
text_embeds = torch.randn(4, 256, 768).cuda()
images = torch.randn(4, 3, 256, 256).cuda()
# 训练模型
for i in (1, 2):
loss = imagen(images, text_embeds = text_embeds, unet_number = i)
loss.backward()
# 生成图像
generated_images = imagen.sample(texts = [
'a whale breaching from afar',
'young girl blowing out candles on her birthday cake',
'fireworks with blue and green sparkles'
], cond_scale = 3.)
高级功能和技巧
- 多GPU训练
Imagen-PyTorch利用🤗 Accelerate库实现了简单的多GPU训练。只需在训练脚本所在目录运行accelerate config,然后使用accelerate launch train.py启动训练。
- 命令行界面
项目提供了命令行工具,方便进行配置、训练和采样:
# 配置
imagen config --path ./configs/config.json
# 训练
imagen train --unet 2 --epoches 10
# 采样
imagen sample --model ./path/to/model/checkpoint.pt "a squirrel raiding the birdfeeder"
- Inpainting功能
Imagen-PyTorch实现了基于Repaint论文的图像修复功能:
inpaint_images = torch.randn(4, 3, 512, 512).cuda()
inpaint_masks = torch.ones((4, 512, 512)).bool().cuda()
inpainted_images = trainer.sample(texts = [
'a whale breaching from afar',
'young girl blowing out candles on her birthday cake',
'fireworks with blue and green sparkles',
'dust motes swirling in the morning sunshine on the windowsill'
], inpaint_images = inpaint_images, inpaint_masks = inpaint_masks, cond_scale = 5.)
- Elucidated Imagen
项目引入了基于Tero Karras的新论文的Elucidated Imagen,提供了一种新的扩散模型变体:
from imagen_pytorch import ElucidatedImagen
imagen = ElucidatedImagen(
unets = (unet1, unet2),
image_sizes = (64, 128),
cond_drop_prob = 0.1,
num_sample_steps = (64, 32),
sigma_min = 0.002,
sigma_max = (80, 160),
sigma_data = 0.5,
rho = 7,
P_mean = -1.2,
P_std = 1.2,
S_churn = 80,
S_tmin = 0.05,
S_tmax = 50,
S_noise = 1.003,
).cuda()
- 文本到视频生成
Imagen-PyTorch还在探索文本引导的视频合成,采用了Jonathan Ho在Video Diffusion Models中描述的3D U-Net架构:
from imagen_pytorch import Unet3D, ElucidatedImagen, ImagenTrainer
unet1 = Unet3D(dim = 64, dim_mults = (1, 2, 4, 8)).cuda()
unet2 = Unet3D(dim = 64, dim_mults = (1, 2, 4, 8)).cuda()
imagen = ElucidatedImagen(
unets = (unet1, unet2),
image_sizes = (16, 32),
random_crop_sizes = (None, 16),
temporal_downsample_factor = (2, 1),
num_sample_steps = 10,
# ... 其他参数
).cuda()
trainer = ImagenTrainer(imagen)
# 训练
trainer(videos, texts = texts, unet_number = 1, ignore_time = False)
trainer.update(unet_number = 1)
# 生成视频
videos = trainer.sample(texts = texts, video_frames = 20)
研究进展和应用
Imagen-PyTorch项目不仅是一个技术实现,还是一个活跃的研究平台。社区成员正在探索各种应用和改进,包括:
- 超声心动图合成
- 高分辨率Hi-C接触矩阵合成
- 平面图生成
- 超高分辨率组织病理学切片
- 合成腹腔镜图像
- 设计超材料
这些应用展示了Imagen模型在医学影像、建筑设计、材料科学等领域的潜力。
未来展望
Imagen-PyTorch项目仍在不断发展,未来计划包括:
- 改进文本编码器,支持更多预训练模型
- 优化动态阈值技术
- 扩展到更多模态,如音频生成
- 改进训练效率和内存使用
- 探索自监督学习技术
结语
Imagen-PyTorch项目为研究人员和开发者提供了一个强大的工具,用于探索和应用最先进的文本到图像生成技术。通过开源社区的努力,我们期待看到更多创新应用和技术突破,推动人工智能创造力的边界不断扩展。
无论您是对计算机视觉感兴趣的研究人员,还是寻求创新解决方案的企业开发者,Imagen-PyTorch都为您提供了一个绝佳的起点。我们鼓励您深入探索这个项目,贡献您的想法,共同推动这一激动人心的技术领域向前发展。
🔗 项目链接: Imagen-PyTorch on GitHub
📚 参考资料:
- Imagen: Unprecedented photorealism × deep level of language understanding
- Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
- Video Diffusion Models
让我们一起期待Imagen-PyTorch项目的未来发展,见证人工智能创造力的无限可能! 🚀🎨











