Index-1.9B模型介绍
Index-1.9B是由哔哩哔哩(B站)自主研发并开源的一个轻量级多语言大模型系列,包括以下几个版本:
- Index-1.9B base: 基础模型,具有19亿非嵌入参数,在2.8T主要中英文语料上预训练。
- Index-1.9B pure: 基础模型的对照版本,过滤掉了所有指令相关数据。
- Index-1.9B chat: 基于base模型进行SFT和DPO对齐的对话模型。
- Index-1.9B character: 在SFT和DPO基础上引入RAG,实现少样本角色扮演定制。
该模型在多个评测基准上表现优异,与同等规模模型相比处于领先地位。
模型下载
Index-1.9B系列模型可在以下平台下载:
-
HuggingFace:
-
ModelScope:
使用教程
环境配置
- 克隆代码仓库:
git clone https://github.com/bilibili/Index-1.9B
cd Index-1.9B
- 安装依赖:
pip install -r requirements.txt
使用Transformers加载模型
可以使用以下代码加载Index-1.9B-Chat模型进行对话:
import argparse
from transformers import AutoTokenizer, pipeline
parser = argparse.ArgumentParser()
parser.add_argument('--model_path', default="./IndexTeam/Index-1.9B-Chat/", type=str, help="")
parser.add_argument('--device', default="cpu", type=str, help="") # 也可以是"cuda"或苹果芯片的"mps"
args = parser.parse_args()
tokenizer = AutoTokenizer.from_pretrained(args.model_path, trust_remote_code=True)
generator = pipeline("text-generation",
model=args.model_path,
tokenizer=tokenizer, trust_remote_code=True,
device=args.device)
system_message = "你是由哔哩哔哩自主研发的大语言模型,名为"Index"。你能够根据用户传入的信息,帮助用户完成指定的任务,并生成恰当的、符合要求的回复。"
query = "续写 天不生我金坷垃"
model_input = []
model_input.append({"role": "system", "content": system_message})
model_input.append({"role": "user", "content": query})
model_output = generator(model_input, max_new_tokens=300, top_k=5, top_p=0.8, temperature=0.3, repetition_penalty=1.1, do_sample=True)
print('User:', query)
print('Model:', model_output)
Web演示
依赖Gradio,安装命令:
pip install gradio==4.29.0
运行以下代码启动Web服务器:
python demo/web_demo.py --port='port' --model_path='/path/to/model/'
命令行演示
运行以下代码启动命令行演示:
python demo/cli_demo.py --model_path='/path/to/model/'
OpenAI API演示
依赖Flask,启动Flask API:
python demo/openai_demo.py --model_path='/path/to/model/'
可以通过命令行进行对话:
curl http://127.0.0.1:8010/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [
{"role": "system", "content": "你是由哔哩哔哩自主研发的大语言模型,名为"Index"。你能够根据用户传入的信息,帮助用户完成指定的任务,并生成恰当的、符合要求的回复。"},
{"role": "user", "content": "花儿为什么这么红?"}
]
}'
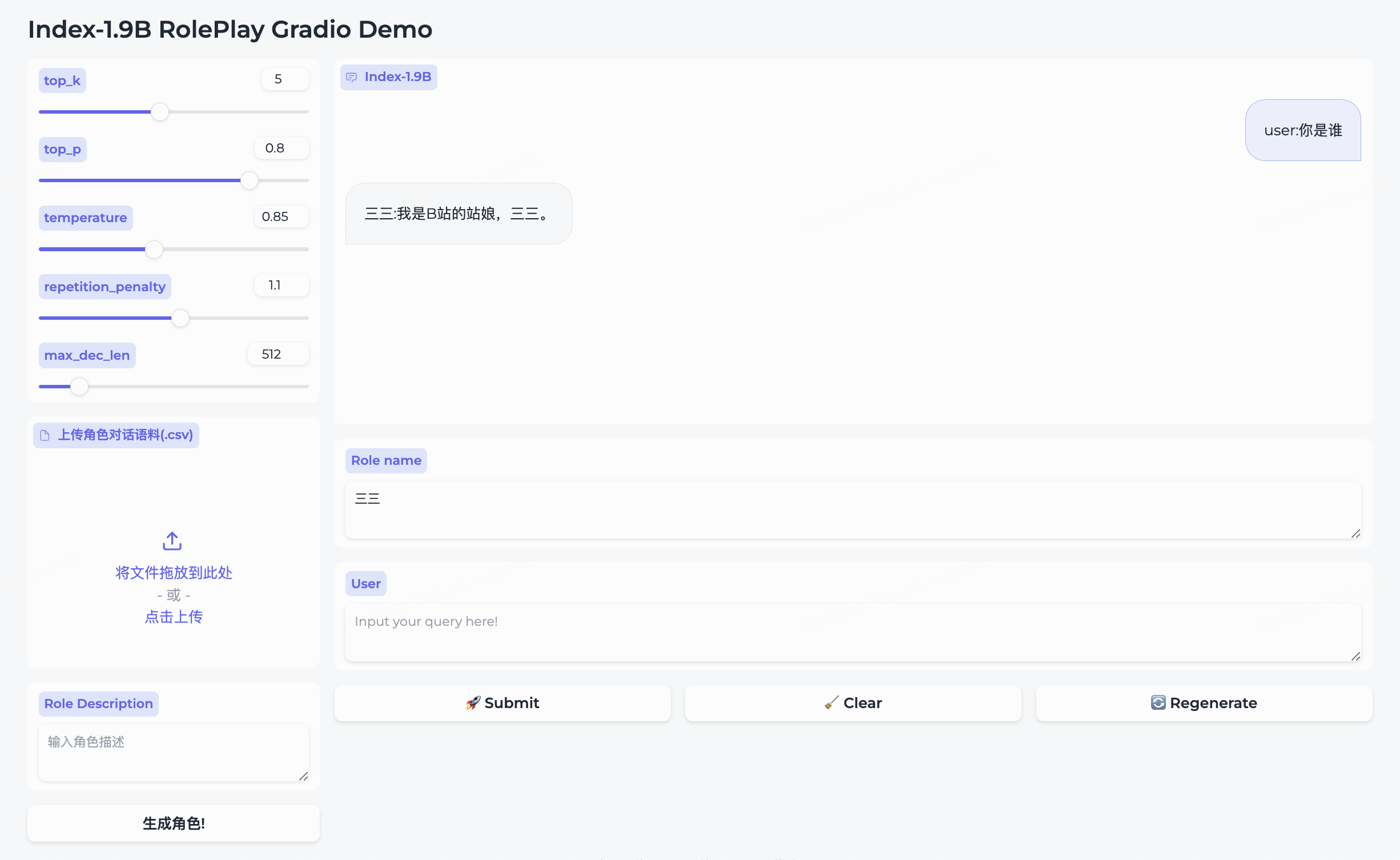
角色扮演
Index-1.9B-Character模型支持少样本角色扮演定制。使用方法如下:
- 准备类似roleplay/character/三三.csv的对话语料(文件名需要与想要创建的角色名称一致)。
- 准备相应的角色描述。
- 点击
生成角色完成创建。 - 在
Role name字段输入想要对话的角色,输入query,点击submit开始对话。
详细用法请参考roleplay文件夹。
量化
依赖bitsandbytes,安装命令:
pip install bitsandbytes==0.43.0
可以使用以下脚本进行int4量化,以减少性能损失并进一步节省显存:
import torch
import argparse
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
TextIteratorStreamer,
GenerationConfig,
BitsAndBytesConfig
)
parser = argparse.ArgumentParser()
parser.add_argument('--model_path', default="", type=str, help="")
parser.add_argument('--save_model_path', default="", type=str, help="")
args = parser.parse_args()
tokenizer = AutoTokenizer.from_pretrained(args.model_path, trust_remote_code=True)
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
)
model = AutoModelForCausalLM.from_pretrained(args.model_path,
device_map="auto",
torch_dtype=torch.float16,
quantization_config=quantization_config,
trust_remote_code=True)
model.save_pretrained(args.save_model_path)
tokenizer.save_pretrained(args.save_model_path)
微调
请参考微调教程快速微调Index-1.9B-Chat模型,定制专属的Index模型。
扩展工作
- libllm: run_bilibili_index.py
- chatllm.cpp: role-play-with-rag
- ollama: bilibili-index
- self llm: Index-1.9B-Chat Lora 微调
Index-1.9B是一个功能强大的轻量级多语言模型,希望本文的资料汇总能够帮助大家更好地了解和使用这一模型。如有任何问题,欢迎在GitHub Issues中讨论。










