
Intel® Extension for PyTorch 简介
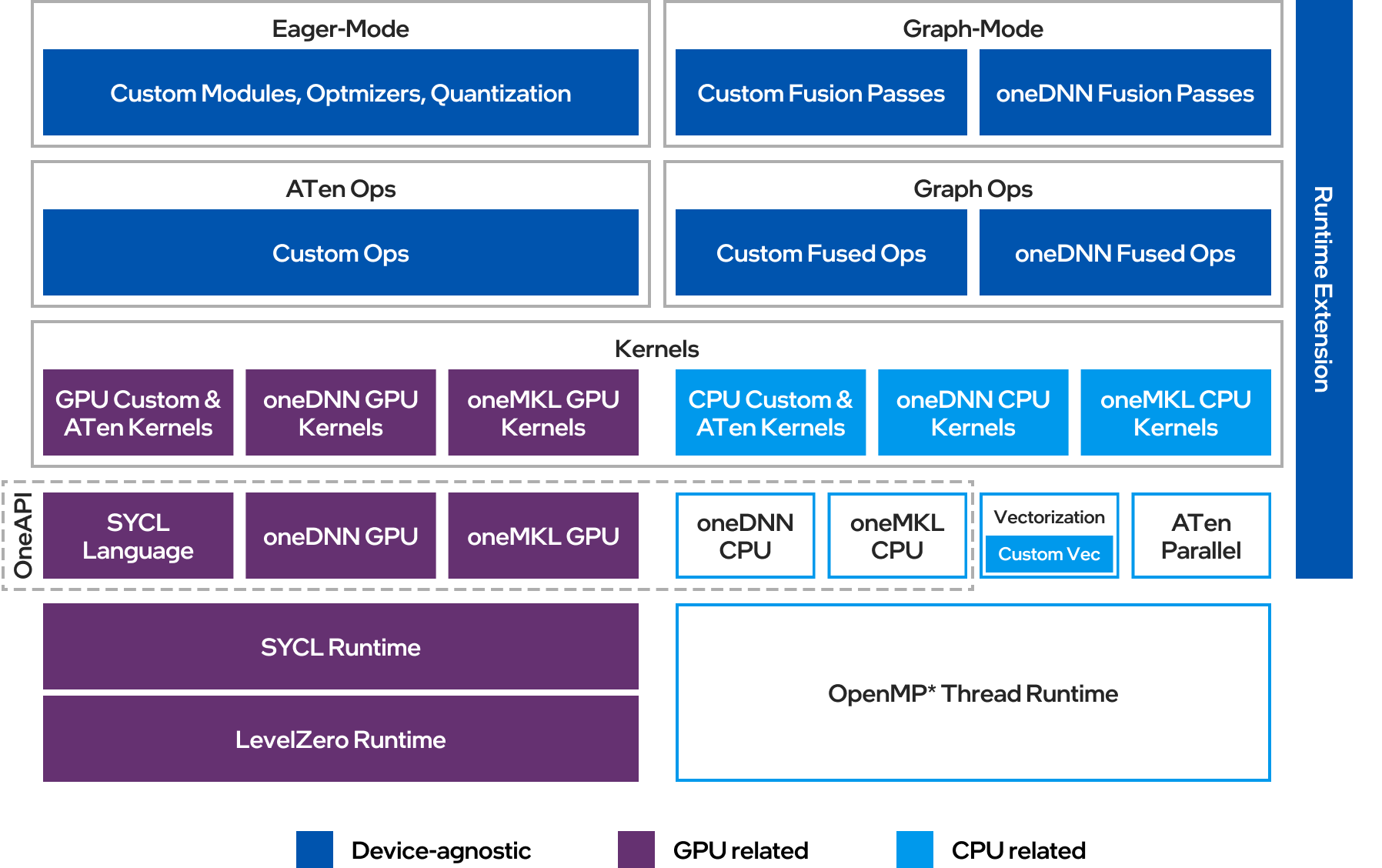
Intel® Extension for PyTorch 是 Intel 公司为 PyTorch 深度学习框架开发的高性能扩展库。它的主要目标是充分发挥 Intel 硬件平台的性能潜力,为 PyTorch 用户提供卓越的计算加速能力。该扩展库支持 Intel CPU 和离散 GPU,可以无缝集成到现有的 PyTorch 项目中,只需少量代码修改即可获得显著的性能提升。
核心特性与优化
Intel® Extension for PyTorch 通过以下几个方面实现了全面的性能优化:
-
硬件加速指令集支持
- 充分利用 Intel AVX-512 向量神经网络指令(VNNI)
- 支持 Intel 高级矩阵扩展(AMX)技术
- 针对 Intel 离散 GPU 的 Xe 矩阵扩展(XMX)AI 引擎优化
-
内存布局优化
- 采用"channels last"内存格式,提高数据访问效率
- 权重预打包技术,减少运行时内存转换开销
-
算子融合与图优化
- 基于 TorchScript IR 的算子融合
- 常量折叠等图优化技术
- 卷积+BatchNorm 融合等专用优化
-
定制化算子实现
- 针对推荐系统等场景的融合交互、合并嵌入包等算子
- 面向目标检测任务的 ROIAlign、FrozenBatchNorm 等算子
-
优化器改进
- 提供高度调优的融合优化器和分割优化器
- 支持 Lamb、Adagrad、SGD 等常用优化器的融合实现
-
低精度计算支持
- BF16 混合精度训练
- INT8 量化推理
-
运行时优化
- 细粒度线程运行时控制
- 权重共享机制提升效率
-
GPU 加速支持
- 通过 PyTorch
xpu设备提供 Intel 离散 GPU 加速
- 通过 PyTorch
使用方法
Intel® Extension for PyTorch 的使用非常简单,只需要在现有的 PyTorch 代码中添加几行代码即可启用优化:
- 安装扩展库:
python -m pip install intel_extension_for_pytorch
- 在代码中导入并应用优化:
import torch
import intel_extension_for_pytorch as ipex
# 优化模型
model = ipex.optimize(model)
# 对于训练任务,还需要优化优化器
optimizer = ipex.optimize(optimizer)
# 使用 channels last 内存格式
model = model.to(memory_format=torch.channels_last)
input_tensor = input_tensor.to(memory_format=torch.channels_last)
# 启用 BF16 混合精度(可选)
with torch.cpu.amp.autocast():
output = model(input_tensor)
对于 GPU 加速,只需将模型和数据移动到 'xpu' 设备即可:
model = model.to('xpu')
input_tensor = input_tensor.to('xpu')
性能提升
根据 Intel 的基准测试,Intel® Extension for PyTorch 可以为各种深度学习模型带来显著的性能提升:
- 在离线推理场景下,ResNet-50、BERT-Large 等模型可获得 1.5-3 倍的性能提升
- 在实时推理场景中,多个模型的性能提升幅度达到 1.2-2.5 倍
- BF16 混合精度训练可进一步将性能提升 1.5-2 倍
这些性能数据充分展示了 Intel® Extension for PyTorch 在 Intel 硬件平台上的优化效果。
未来发展
Intel® Extension for PyTorch 作为一个开源项目,将持续为 PyTorch 社区带来最新的优化技术。未来的发展重点包括:
- 支持更多的 Intel 硬件平台,如新一代 Xeon 处理器和 Arc 系列 GPU
- 进一步提升大语言模型(LLM)等生成式 AI 工作负载的性能
- 增强与 PyTorch 2.0 等新版本的兼容性
- 提供更多针对特定领域和模型的优化
- 改进开发者体验,简化使用流程
结论
Intel® Extension for PyTorch 为 AI 开发者和研究人员提供了一个强大的工具,可以轻松地在 Intel 硬件平台上获得卓越的深度学习性能。通过全面的优化技术和简单的使用方式,它大大提升了 PyTorch 的效率,加速了 AI 创新的进程。无论是在训练还是推理阶段,Intel® Extension for PyTorch 都是提升深度学习工作负载性能的理想选择。
作为一个活跃的开源项目,Intel® Extension for PyTorch 欢迎社区的贡献和反馈。开发者可以通过 GitHub 仓库参与项目开发,提出建议或报告问题,共同推动这一强大工具的持续进步。
通过采用 Intel® Extension for PyTorch,AI 从业者可以充分发挥 Intel 硬件的潜力,在保持模型精度的同时显著提升计算效率,从而更快地将创新理念转化为现实应用。在 AI 技术日新月异的今天,这种性能优势将为个人和组织带来巨大的竞争力。









