
InternVL: 开创性的开源多模态大模型家族
InternVL是由上海人工智能实验室(Shanghai AI Lab)开发的一个开创性的开源多模态大模型家族。该项目旨在打造一套强大的开源多模态AI系统,以缩小与商业闭源模型如GPT-4V之间的能力差距。
InternVL2: 更强大的新一代模型
最新发布的InternVL2系列包括从1B到108B参数的多个模型,适用于从边缘设备到大规模服务器的不同场景。其中最强大的InternVL2-Pro模型在多个基准测试中展现出与GPT-4V、Gemini Pro等顶级商业模型相当的性能。
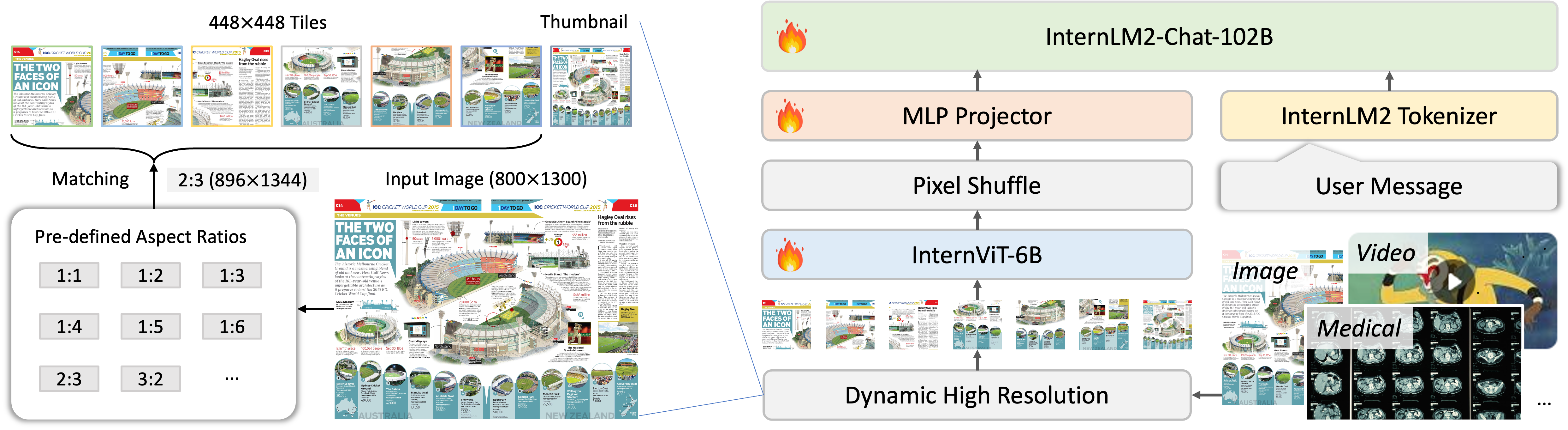
InternVL2的主要特点包括:
-
渐进式训练策略:从小到大逐步扩展模型规模,同时数据从粗到精逐步精炼,实现了大模型的高效训练。
-
多模态输入:支持文本、图像、视频、医疗数据等多种输入模态。
-
多任务输出:基于VisionLLMv2技术,支持图像、边界框、掩码等多种输出格式,可泛化到数百种视觉-语言任务。
强大的视觉基础模型
InternVL的视觉基础模型InternViT-6B在多项视觉任务上展现出卓越性能:
-
在ImageNet等图像分类数据集上,InternViT-6B的线性探测准确率超过了ViT-22B等更大的模型。
-
在语义分割任务上,InternViT-6B冻结特征+UperNet解码器的mIoU达到54.9,超过了ViT-22B的52.7。
-
在零样本图像分类上,InternVL-C模型在多个数据集上接近或超过了ViT-22B的表现。
出色的跨模态检索能力
InternVL在图像-文本检索任务上也表现优异:
-
在英文Flickr30K和COCO数据集上,InternVL-G模型的平均召回率达到88.8%,超过了EVA-CLIP-8B等强大基线。
-
在中文图文检索任务上,InternVL-C模型大幅领先于其他开源中文多模态模型。
多语言和视频理解能力
InternVL还展现出强大的多语言和视频理解能力:
-
在多语言零样本图像分类任务上,InternVL-C模型在英语、中文、日语、阿拉伯语、意大利语等多种语言上均取得了最佳性能。
-
在零样本视频分类任务上,InternVL-C模型在Kinetics-400/600/700等数据集上大幅超越了现有最佳模型。
开放获取与应用
InternVL系列模型已在Hugging Face和ModelScope等平台开放下载,研究者可以方便地获取和使用这些模型。此外,项目还提供了在线演示、本地部署等多种使用方式,方便用户体验和应用这些强大的多模态模型。
总的来说,InternVL项目为开源社区带来了一套强大的多模态AI模型,在缩小与商业闭源模型的差距方面迈出了重要一步。随着持续的迭代和改进,InternVL有望在未来为更多AI应用场景提供强大的开源解决方案。











