
JARVIS简介
JARVIS是微软开发的一个创新性人工智能协作系统,旨在探索通用人工智能(AGI)并为整个AI社区提供前沿研究成果。该系统由一个大型语言模型(LLM)作为控制器,以及众多来自Hugging Face的专家模型作为协作执行器组成。JARVIS的核心理念是利用语言作为接口,将LLM与各种AI模型连接起来,以解决复杂的AI任务。
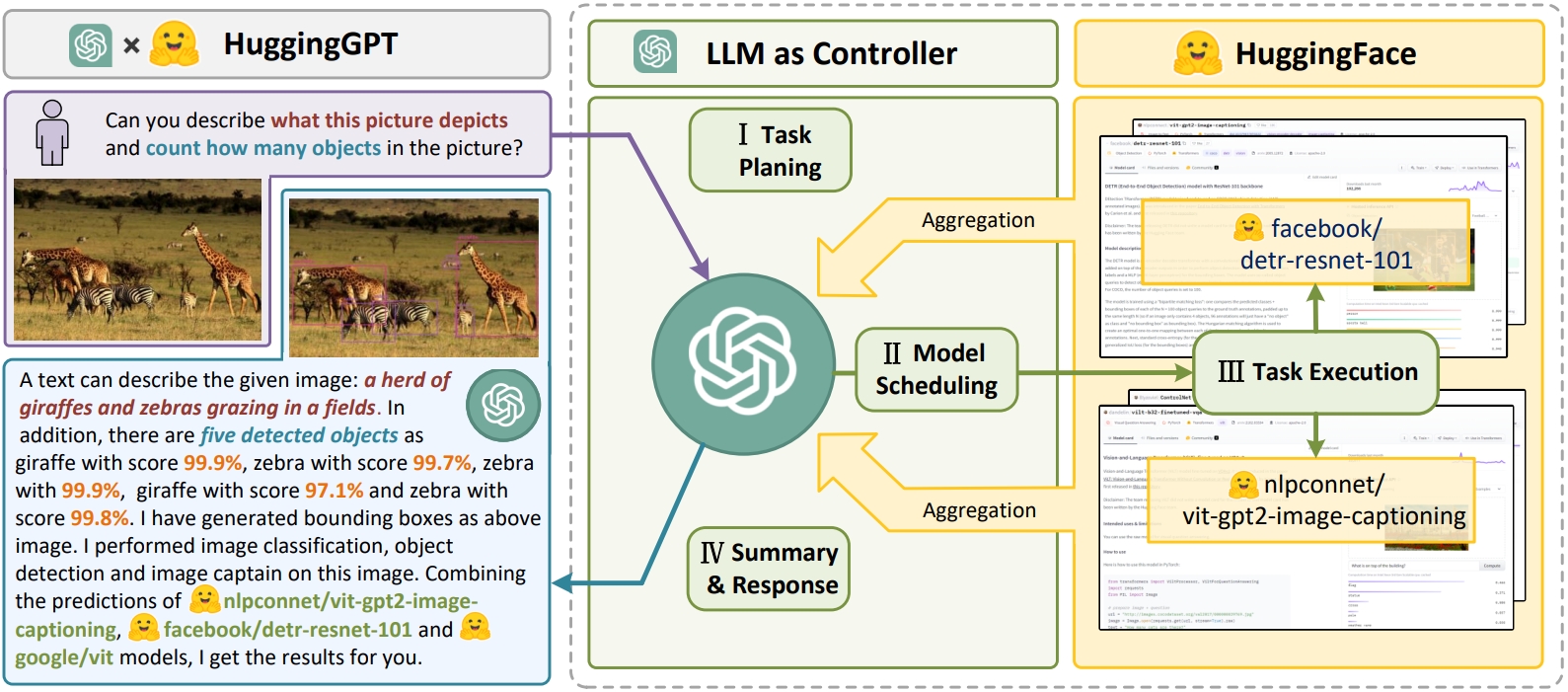
工作流程
JARVIS的工作流程包括四个主要阶段:
-
任务规划:使用ChatGPT分析用户请求,理解其意图,并将其分解为可解决的子任务。
-
模型选择:ChatGPT根据任务需求和模型描述,从Hugging Face上选择合适的专家模型。
-
任务执行:调用并执行每个选定的模型,将结果返回给ChatGPT。
-
响应生成:ChatGPT整合所有模型的预测结果,生成最终响应。

系统要求
JARVIS提供了不同配置选项,以适应不同的硬件环境:
默认配置(推荐)
- Ubuntu 16.04 LTS
- VRAM ≥ 24GB
- RAM > 12GB (最小), 16GB (标准), 80GB (完整)
- 磁盘空间 > 284GB
最小配置(Lite版)
- Ubuntu 16.04 LTS
- 无其他特殊要求
最小配置使用configs/config.lite.yaml,不需要在本地下载和部署专家模型,但会限制JARVIS只能使用Hugging Face推理端点上稳定运行的模型。
快速上手指南
要开始使用JARVIS,请按照以下步骤操作:
-
替换配置文件中的API密钥: 在
server/configs/config.default.yaml中替换openai.key和huggingface.token为您的个人OpenAI密钥和Hugging Face令牌。或者,将它们设置为环境变量OPENAI_API_KEY和HUGGINGFACE_ACCESS_TOKEN。 -
设置环境:
cd server conda create -n jarvis python=3.8 conda activate jarvis conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia pip install -r requirements.txt -
下载模型(如果使用本地或混合推理模式):
cd models bash download.sh -
运行服务器:
cd .. python models_server.py --config configs/config.default.yaml python awesome_chat.py --config configs/config.default.yaml --mode server
现在,您可以通过Web API访问JARVIS的服务:
/hugginggpt: POST方法,访问完整服务/tasks: POST方法,访问第1阶段的中间结果/results: POST方法,访问第1-3阶段的中间结果
Web界面
JARVIS还提供了一个用户友好的Web界面。在服务器模式下启动awesome_chat.py后,您可以运行以下命令在浏览器中与JARVIS交互:
cd web
npm install
npm run dev
注意:
- 如果在另一台机器上运行Web客户端,需要在
web/src/config/index.ts中设置HUGGINGGPT_BASE_URL为服务器的LAN IP地址和端口。 - 如果要使用视频生成功能,需要手动编译支持H.264的ffmpeg。
- 双击设置图标可切换到ChatGPT模式。
Gradio演示
JARVIS的Gradio演示现已在Hugging Face Space上托管。您也可以通过以下命令在本地运行演示:
python models_server.py --config configs/config.gradio.yaml
python run_gradio_demo.py --config configs/config.gradio.yaml
命令行界面(CLI)模式
JARVIS还支持CLI模式,使用更加简便:
cd server
python awesome_chat.py --config configs/config.default.yaml --mode cli
配置选项
JARVIS的服务器端配置文件为server/configs/config.default.yaml,主要参数包括:
model: LLM模型,目前支持text-davinci-003inference_mode: 推理端点模式local: 仅使用本地推理端点huggingface: 仅使用Hugging Face推理端点(无需本地推理端点)hybrid: 同时使用本地和Hugging Face推理端点
local_deployment: 本地部署模型的规模minimal: RAM>12GB,仅ControlNetstandard: RAM>16GB,ControlNet + 标准管道full: RAM>42GB,所有注册模型
对于个人笔记本电脑,推荐配置为inference_mode: hybrid和local_deployment: minimal。
NVIDIA Jetson嵌入式设备支持
JARVIS还提供了对NVIDIA Jetson嵌入式设备的实验性支持。项目中包含了一个Dockerfile,提供了加速的ffmpeg、pytorch、torchaudio和torchvision依赖。
要在Jetson AGX Orin系列设备上运行JARVIS,建议使用以下配置:
inference_mode: locallocal_deployment: standard
最新进展
JARVIS团队持续推进项目的发展,近期的重要更新包括:
-
发布Easytool工具,简化工具使用:
-
发布TaskBench,用于评估LLM的任务自动化能力:
-
支持Azure平台上的OpenAI服务和GPT-4模型
-
添加Gradio演示和Web API,提供更丰富的交互方式
-
增加CLI模式,提供轻量级体验
这些更新体现了JARVIS项目在提升系统功能、扩展应用场景和优化用户体验方面的持续努力。
结语
JARVIS项目展示了通过语言模型作为控制器,结合专业AI模型作为执行器的创新方法,为解决复杂AI任务提供了新的思路。它不仅是一个强大的AI协作系统,也是探索通用人工智能的重要平台。随着项目的不断发展和完善,JARVIS有望为AI研究社区带来更多突破性的成果,推动人工智能技术向更高水平迈进。
如果您对JARVIS项目感兴趣,欢迎访问GitHub仓库了解更多详情,参与项目开发,或者尝试使用JARVIS解决您的AI任务。让我们一起探索AI的无限可能!











