
KANbeFair项目简介
KANbeFair是一个旨在对KAN(Kernel Adaptive Network)和MLP(多层感知机)进行更加公平和全面比较的研究项目。该项目由研究人员Runpeng Yu、Weihao Yu和Xinchao Wang发起,目的是通过严格控制参数数量和计算量,在多种任务上系统地比较这两种神经网络模型的性能。
KAN是近年来提出的一种新型神经网络架构,声称在某些任务上性能优于传统的MLP。然而,之前的比较研究往往存在不公平或不全面的问题。KANbeFair项目正是为了解决这一问题而生,致力于提供一个更加客观和深入的比较基准。
研究方法与实验设置
KANbeFair项目采用了以下几个关键策略来确保比较的公平性和全面性:
-
严格控制参数数量和FLOPs(浮点运算次数),确保KAN和MLP模型在计算资源上处于同等水平。
-
涵盖多个应用领域的任务,包括:
- 机器学习基准任务
- 计算机视觉任务
- 自然语言处理任务
- 音频处理任务
- 符号公式表示任务
-
使用统一的训练和评估流程,包括相同的优化器、学习率策略等。
-
进行详细的消融实验,分析不同组件对模型性能的影响。
研究团队开发了一个灵活的实验框架,可以方便地配置和运行各种比较实验。所有代码和数据集都已在GitHub上开源,以便其他研究者复现结果和进行进一步的探索。
主要研究发现
通过大量的实验和分析,KANbeFair项目得出了以下几个重要发现:
-
MLP在大多数任务中表现优于KAN
除了符号公式表示任务外,MLP在机器学习、计算机视觉、自然语言处理和音频处理等领域的任务中,普遍表现优于KAN。这一发现与之前一些研究的结论有所不同,凸显了公平比较的重要性。
-
KAN的主要优势在于B样条激活函数
通过对网络架构进行消融实验,研究发现KAN的主要优势来源于其使用的B样条激活函数。当将B样条激活函数应用到MLP中时,MLP的性能可以显著提升,在某些任务上甚至超过了KAN。
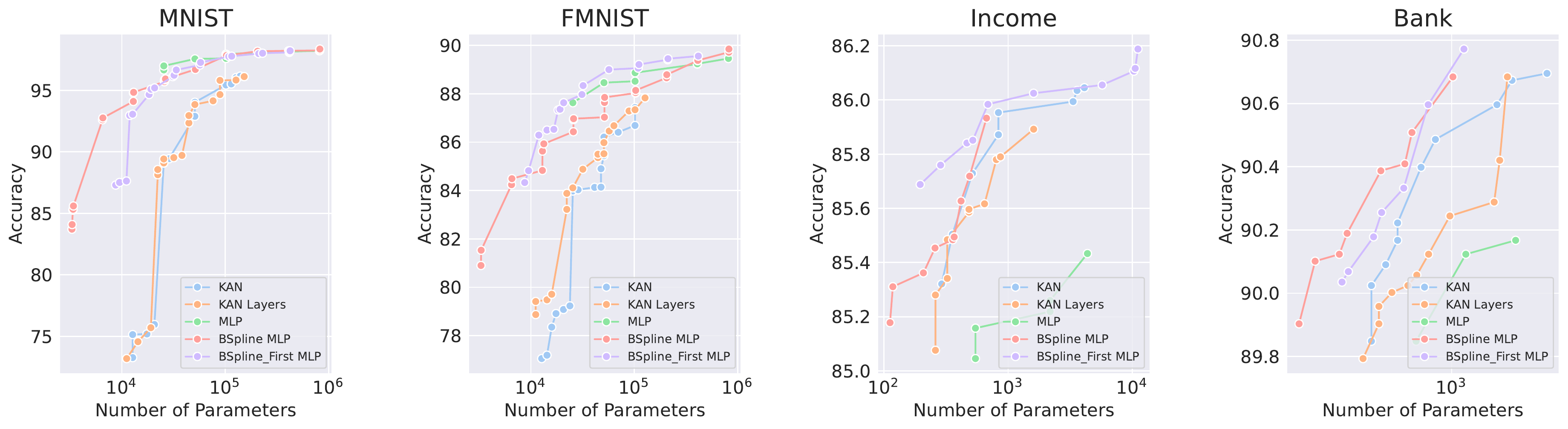
-
B样条激活函数对符号公式表示任务特别有效
在符号公式表示任务中,使用B样条激活函数的MLP能够达到或超过KAN的性能。这表明B样条函数在捕捉复杂的数学关系方面具有独特优势。
-
KAN在持续学习场景中的遗忘问题更为严重
在标准的类增量持续学习设置下,KAN表现出比MLP更严重的遗忘问题。这一发现与KAN原始论文中的结论不同,需要进一步研究。
技术实现细节
KANbeFair项目提供了详细的代码实现和实验复现指南。以下是一些关键的技术细节:
-
环境配置
项目使用CUDA 12.2进行GPU加速,可通过提供的
environment.yml文件快速搭建实验环境:cd KANbeFair conda env create -f environment.yml -
运行实验
使用以下命令可以运行各种比较实验:
cd src python train.py \ --model KAN \ # 或MLP,指定模型架构 --layers_width 10 10 \ --dataset MNIST \ --batch-size 128 \ --epochs 20 \ --lr 0.001 \ --seed 1314 \ --activation_name gelu \ # 仅对MLP有效 --kan_bspline_grid 20 \ # 仅对KAN有效 --kan_bspline_order 5 \ # 仅对KAN有效 --kan_grid_range -4 4 \ # 仅对KAN有效 -
参数和FLOPs计算
项目提供了方便的方法来计算模型的参数数量和FLOPs:
import torch from argparse import Namespace from models.mlp import * from models.kanbefair import * from models.bspline_mlp import * # 实例化KANbeFair网络 args_KAN = Namespace(**{ "input_size":28*28, "layers_width":[10,10], "output_size":10, "kan_bspline_grid":20, "kan_bspline_order":5, "kan_shortcut_function":torch.nn.SiLU(), "kan_grid_range":[-1,1] }) model_KAN = KANbeFair(args_KAN) # 计算KAN的参数数量和FLOPs num_parameters_KAN = model_KAN.total_parameters() flops_KAN = model_KAN.total_flops() print(f"KAN: Number of parameters: {num_parameters_KAN:,}; Number of FLOPs: {flops_KAN:,}") # 类似地可以计算MLP的参数数量和FLOPs
研究意义与未来展望
KANbeFair项目的研究结果对神经网络架构的选择和设计提供了重要的参考价值:
-
模型选择指南: 研究结果为不同任务场景下的模型选择提供了明确指导。对于大多数机器学习、计算机视觉、自然语言处理和音频处理任务,MLP仍然是一个强有力的基线模型。而对于涉及复杂数学关系的符号公式表示任务,KAN或配备B样条激活函数的MLP可能更为适合。
-
激活函数的重要性: 研究凸显了激活函数在神经网络性能中的关键作用。B样条函数的成功应用为设计新型激活函数开辟了新的思路。
-
公平比较的重要性: KANbeFair项目展示了在神经网络研究中进行公平和全面比较的重要性。这种方法有助于避免对新提出模型的过度乐观估计,为整个领域的健康发展提供了借鉴。
-
持续学习的挑战: 关于KAN在持续学习中表现不佳的发现,揭示了这一领域仍存在的挑战,需要进一步的研究和改进。
未来的研究方向可能包括:
- 探索将B样条激活函数应用于其他神经网络架构的可能性
- 深入研究KAN在持续学习中的问题,并寻求改进方案
- 在更广泛的任务和数据集上扩展比较研究
- 结合KAN和MLP的优势,设计新的混合架构
结论
KANbeFair项目通过严谨的方法学和全面的实验,为KAN和MLP的性能比较提供了新的视角。研究结果不仅有助于实践者在不同场景下做出更明智的模型选择,也为神经网络架构的未来发展指明了方向。随着人工智能技术的不断进步,类似KANbeFair这样的公平比较研究将继续发挥重要作用,推动整个领域的创新和进步.









