
KG-RAG:知识图谱增强的检索增强生成技术
近年来,大型语言模型(LLM)如GPT-4和Claude 2在自然语言处理领域取得了突破性进展,极大地改变了我们获取和处理信息的方式。然而,这些模型在处理需要专业知识的复杂查询时仍面临一些挑战。为了解决这个问题,研究人员提出了一种创新的方法 - KG-RAG(Knowledge Graph-based Retrieval Augmented Generation),即基于知识图谱的检索增强生成技术。
KG-RAG的核心理念
KG-RAG是一个任务无关的框架,旨在将知识图谱(KG)的显式知识与大型语言模型(LLM)的隐式知识相结合。这种方法的核心在于从知识图谱中提取'提示感知上下文',即:
足以回应用户提示的最小上下文。
通过这种方式,KG-RAG为通用LLM注入了优化的领域特定知识,从而显著提高了其在专业领域的表现。
KG-RAG的工作原理
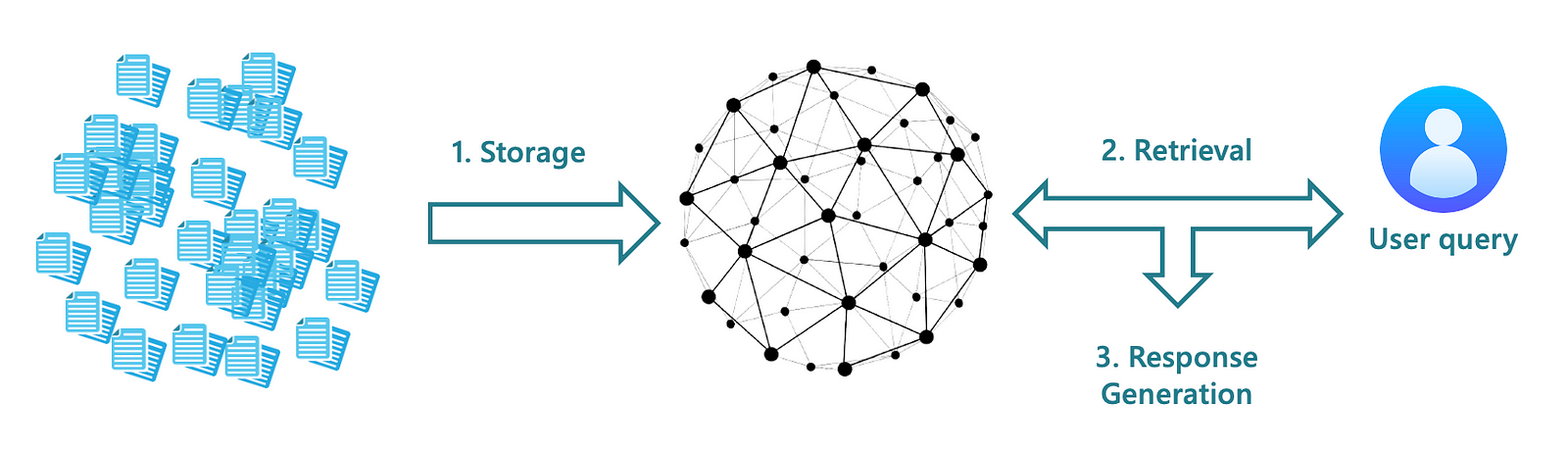
KG-RAG主要包含三个关键阶段:
-
知识图谱构建: 将非结构化文本转换为结构化的知识图谱。这一步骤对于保持信息质量至关重要,如果处理不当可能会影响后续阶段。
-
检索: 通过一种名为'探索链'(Chain of Explorations, CoE)的新型检索算法来完成。CoE利用LLM的推理能力在知识图谱中探索节点和关系,确保检索过程既相关又准确。
-
响应生成: 生成连贯且符合上下文的回答。
KG-RAG的优势
-
提高准确性: 通过结合知识图谱的结构化信息,KG-RAG能够显著减少LLM的幻觉问题,提供更加准确和可靠的回答。
-
增强上下文理解: KG-RAG能够更好地理解查询的意图和上下文,从而提供更加相关和深入的回答。
-
动态知识融合: KG-RAG允许实时更新知识库,确保LLM能够访问最新的信息。
-
领域适应性: 通过使用特定领域的知识图谱,KG-RAG可以轻松适应不同的专业领域,如生物医学、金融或法律等。
实际应用案例
以生物医学领域为例,KG-RAG利用名为SPOKE的大型生物医学知识图谱作为背景知识提供者。SPOKE整合了来自40多个生物医学知识库的信息,涵盖了基因、蛋白质、药物、化合物、疾病等生物医学概念及其关系。它包含超过2700万个节点和5300万条边,为KG-RAG提供了丰富的领域知识。
在一个具体的测试中,研究人员比较了使用和不使用KG-RAG的GPT-4在回答关于FDA批准药物的问题时的表现。结果显示,使用KG-RAG的GPT-4能够提供更加准确和详细的信息,而没有使用KG-RAG的GPT-4则可能给出不完整或过时的答案。
KG-RAG的未来发展
KG-RAG代表了AI系统向更智能、更可靠方向发展的重要一步。随着技术的不断完善,我们可以期待:
-
跨领域应用: 虽然目前KG-RAG主要应用于生物医学领域,但这一框架有潜力扩展到其他专业领域。
-
多模态集成: 未来的KG-RAG可能会整合文本、图像、音频等多种数据类型,提供更全面的知识表示。
-
实时学习与更新: 开发能够实时学习和更新知识图谱的系统,使AI助手始终掌握最新信息。
-
提高可解释性: 通过可视化知识图谱的检索路径,提高AI决策过程的透明度和可解释性。
总的来说,KG-RAG为解决大型语言模型在专业领域应用中面临的挑战提供了一个有前景的解决方案。通过将结构化知识与先进的语言理解能力相结合,KG-RAG正在推动AI系统向更智能、更可靠的方向发展,为未来的人工智能应用开辟了新的可能性。










