
KVQuant: 突破大规模语言模型推理的长度限制
KVQuant是由SqueezeAILab开发的一种创新方法,旨在解决大规模语言模型(LLM)推理时的内存瓶颈问题。通过高效的KV缓存量化技术,KVQuant能够实现超长上下文长度的模型推理,为LLM的应用开辟了新的可能性。
核心技术亮点
KVQuant主要包含以下几项创新:
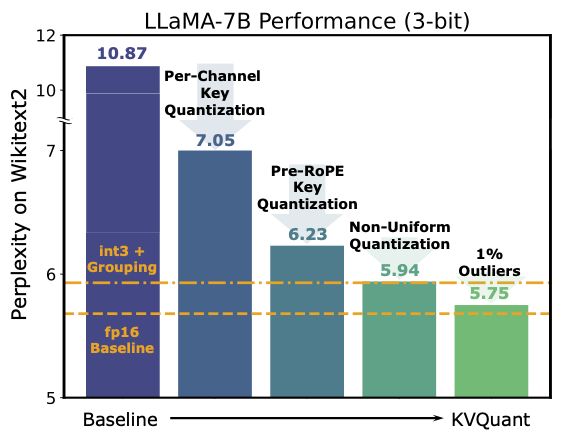
- 按通道预RoPE键量化: 更好地匹配Key中的离群通道
- 非均匀量化(NUQ): 更好地表示非均匀分布的激活值
- 稠密稀疏量化: 缓解数值离群值对量化难度的影响
通过这些技术,KVQuant实现了以下突破性成果:
- 在单个A100-80GB GPU上运行具有100万上下文长度的LLaMA-7B模型
- 在8个GPU系统上运行具有1000万上下文长度的LLaMA-7B模型 🚀
这些成果大大扩展了LLM的应用场景,特别是在需要处理长文档的任务中。
学习资源
想要深入了解KVQuant,可以参考以下资源:
- 官方论文: KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization
- GitHub仓库: SqueezeAILab/KVQuant
- Twitter解读线程: Coleman Hooper的解读
实践指南
KVQuant的代码库包含多个子文件夹,每个都有独立的README文件,提供了详细的环境配置和使用说明。以下是主要模块的简介:
gradients: 用于计算Fisher信息quant: 用于运行模拟量化和评估实验deployment: 用于运行压缩向量的高效推理lwm: 用于运行和评估量化后的Large World Modelbenchmarking: 用于基准测试内核性能
要复现论文中报告的困惑度数据,需要先运行gradients模块,然后运行quant模块。
最新改进
KVQuant团队持续优化该方法,最近的改进包括:
- 并行topK GPU支持
- Key离群值上限设置
- 注意力汇聚感知量化
这些改进进一步提升了KVQuant的性能和实用性。
总结
KVQuant代表了LLM推理技术的重要突破,通过创新的量化方法,大大扩展了模型的上下文处理能力。无论是研究人员还是实践者,了解和掌握KVQuant都将有助于推动LLM技术的进一步发展和应用。
随着KVQuant的不断完善,我们期待看到更多基于超长上下文的LLM应用出现,为自然语言处理领域带来新的可能性。
相关链接
如果您在研究或工作中使用了KVQuant,请引用以下论文:
@article{hooper2024kvquant,
title={KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization},
author={Hooper, Coleman and Kim, Sehoon and Mohammadzadeh, Hiva and Mahoney, Michael W and Shao, Yakun Sophia and Keutzer, Kurt and Gholami, Amir},
journal={arXiv preprint arXiv:2401.18079},
year={2024}
}
通过本文的介绍,希望读者能够对KVQuant有一个全面的了解,并能够利用这些资源开始自己的探索之旅。KVQuant作为一项突破性技术,必将在未来的LLM发展中发挥重要作用。










