
LanguageBind:以语言为中心的多模态对齐新范式
在人工智能和机器学习领域,多模态学习一直是一个充满挑战且极具潜力的研究方向。如何有效地将视觉、音频、文本等不同模态的信息进行融合和对齐,是实现真正的人工智能的关键一步。近期,北京大学袁路教授团队提出了一种名为LanguageBind的创新方法,为多模态对齐开辟了一条新的道路。本文将深入介绍LanguageBind的核心思想、主要贡献及最新研究进展。
LanguageBind的核心思想
LanguageBind的核心思想是以语言为中心,将其他模态与语言进行对齐。与传统的多模态预训练方法不同,LanguageBind不需要使用中间模态作为桥梁,而是直接将各个模态映射到语言空间中。这种方法的优势在于:
- 语言模态已经被充分探索,包含丰富的语义信息。
- 以语言为中心可以轻松扩展到更多模态,理论上可以处理无限多的模态。
- 避免了中间模态可能引入的噪声和信息损失。
具体来说,LanguageBind首先使用视频-语言预训练得到一个固定的语言编码器,然后训练其他模态的编码器,使它们的输出与相应的语言描述在特征空间中对齐。这种方法实现了多模态之间的语义对齐,为后续的跨模态任务奠定了基础。
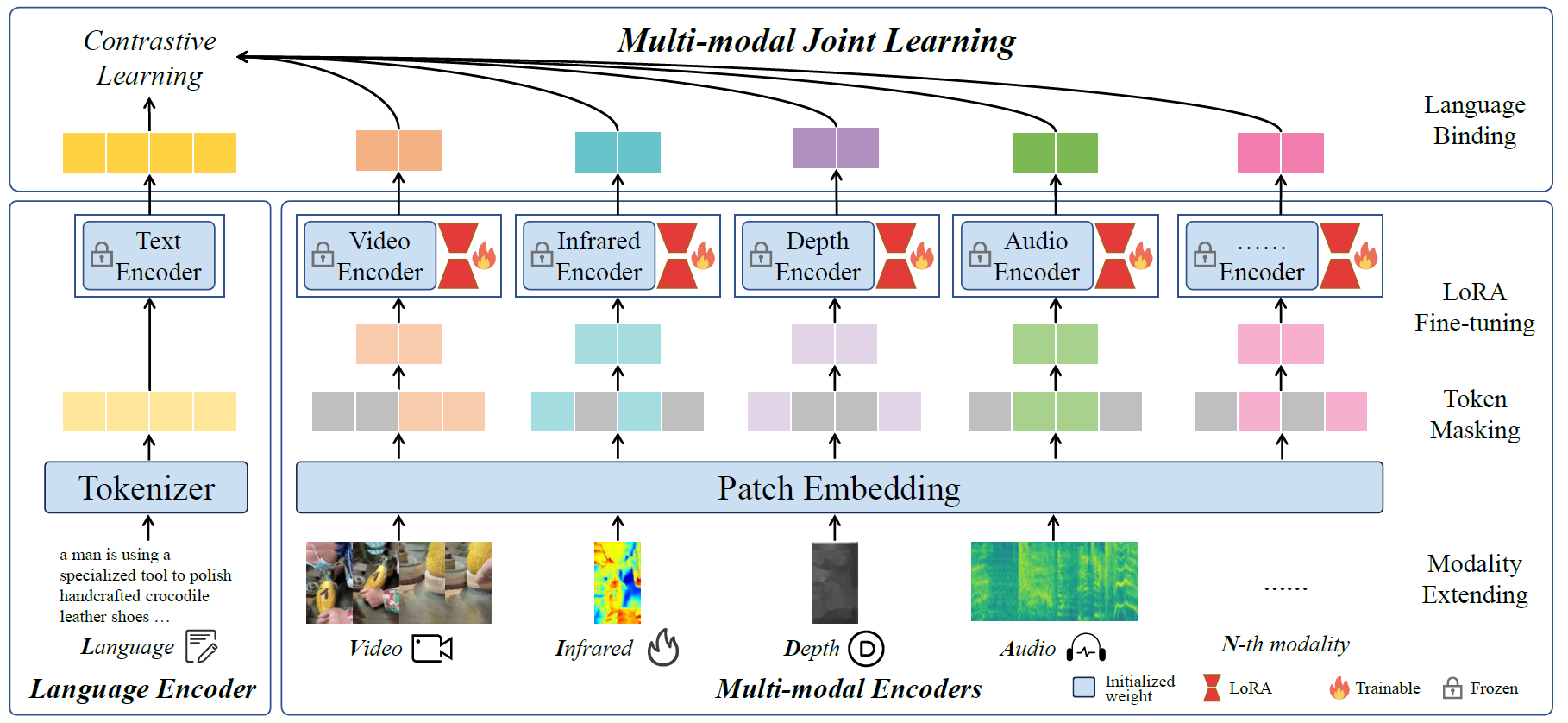
LanguageBind的主要贡献
- 高性能且无需中间模态
LanguageBind在多个跨模态任务上取得了优异的性能,甚至超越了一些专门为单一模态设计的模型。例如,在视频-语言检索、音频-语言分类等任务上,LanguageBind都达到了当前最好的水平。这证明了以语言为中心的对齐方法的有效性。
- VIDAL-10M:大规模多模态数据集
为了支持LanguageBind的训练,研究团队构建了一个名为VIDAL-10M的大规模多模态数据集。该数据集包含了1000万条视频(V)、红外(I)、深度(D)、**音频(A)以及对应的语言(L)**描述数据。这个数据集的特点是:
- 所有视频都来自短视频平台,具有完整的语义内容。
- 视频、深度、红外和音频模态都与文本描述对齐。
- 数据规模大,覆盖面广,有助于模型学习到丰富的跨模态语义关系。

- 多视角增强的语言描述
LanguageBind在训练时采用了多视角增强的语言描述方法。具体来说:
- 结合了元数据、空间和时间信息,生成多视角的描述。
- 使用ChatGPT进一步增强语言描述,创造出更丰富的语义空间。
这种方法极大地提升了语言描述的质量和信息量,有助于模型学习到更加精细和全面的跨模态语义关系。
最新研究进展
自LanguageBind提出以来,研究团队持续对其进行改进和扩展。以下是一些最新的研究进展:
-
LanguageBind已被ICLR 2024接收,获得了6(3)8(6)6(6)6(6)的高分。这证明了该工作在学术界获得了广泛认可。
-
VIDAL数据集扩展:研究团队将VIDAL数据集扩展到了1000万条视频-文本对,并推出了LanguageBind_Video 1.5版本,进一步提升了模型性能。
-
紧急零样本学习:由于LanguageBind将各个模态绑定在一起,研究人员发现它还具有紧急零样本学习的能力。例如,模型可以直接进行视频-音频、图像-深度图等跨模态匹配,而无需专门为这些任务进行训练。
-
Video-LLaVA:基于LanguageBind的编码器,研究团队开发了Video-LLaVA,一个大型视觉-语言模型,在多个基准测试中达到了最先进的性能。
-
MoE-LLaVA:研究团队还提出了MoE-LLaVA,一个基于混合专家的大型视觉-语言模型。该模型仅使用3B参数就超越了7B参数的密集模型,展示了LanguageBind在模型压缩和效率提升方面的潜力。
LanguageBind的应用前景
LanguageBind为多模态AI开辟了广阔的应用前景:
-
跨模态检索:可以实现文本到视频、音频到图像等各种跨模态检索任务,极大地提升信息检索的效率和准确性。
-
多模态理解:在安防、医疗等领域,可以综合分析视频、红外、深度等多种传感器数据,提供更全面的场景理解。
-
辅助诊断:在医疗领域,可以结合患者的影像学数据(如X光、CT等)和临床描述,辅助医生进行更准确的诊断。
-
智能家居:可以整合视觉、语音等多种交互方式,提供更自然、智能的人机交互体验。
-
自动驾驶:结合视觉、雷达、语音等多模态数据,提高自动驾驶系统的感知和决策能力。
未来展望
尽管LanguageBind取得了令人瞩目的成果,但多模态AI仍然存在许多挑战和机遇:
-
模态扩展:如何将LanguageBind扩展到更多的模态,例如触觉、嗅觉等,是一个值得探索的方向。
-
效率优化:随着模态和数据规模的增加,如何提高模型的训练和推理效率是一个重要问题。
-
解释性:提高模型的可解释性,理解多模态融合的内部机制,对于构建可信赖的AI系统至关重要。
-
低资源场景:研究如何在低资源条件下实现高效的多模态学习,以适应更广泛的应用场景。
-
伦理和隐私:在利用多模态数据的同时,如何保护用户隐私,避免模型偏见,是需要认真考虑的问题。
LanguageBind的提出为多模态AI领域注入了新的活力。它不仅在技术上实现了突破,还为未来的研究指明了方向。我们可以期待,随着LanguageBind及其衍生技术的不断发展,人工智能将更加接近人类的认知能力,为我们的生活带来更多便利和可能。
在人工智能的发展历程中,LanguageBind无疑是一个重要的里程碑。它展示了语言作为核心纽带的强大潜力,为构建真正的通用人工智能铺平了道路。随着研究的深入和技术的成熟,我们有理由相信,LanguageBind将在更多领域发挥重要作用,推动人工智能向着更高层次迈进。










