
大型语言模型幻觉排行榜:评估AI模型的事实一致性
随着人工智能技术的快速发展,大型语言模型(LLM)在自然语言处理领域展现出了惊人的能力。然而,这些模型也存在一个普遍的问题 - 幻觉(Hallucination)。所谓幻觉,是指模型生成的内容与事实或给定的上下文不一致。为了系统地评估和比较不同LLM产生幻觉的倾向,Vectara公司推出了一个开放的幻觉排行榜(Hallucination Leaderboard)。
排行榜的意义
这个排行榜的推出具有重要意义:
- 提供客观评估标准:通过统一的评估方法,为比较不同LLM的事实一致性提供了一个客观标准。
- 推动模型改进:通过量化幻觉问题,有助于研究人员和开发者针对性地改进模型。
- 增强用户信任:对于需要使用LLM的用户来说,这个排行榜可以帮助他们选择更可靠的模型。
- 促进行业发展:通过公开透明的评估,推动整个AI行业在减少幻觉方面的努力和进步。
评估方法
排行榜使用Vectara公司开发的Hughes幻觉评估模型(HHEM)来进行评估。具体步骤如下:
- 数据集:使用1000篇来自CNN/Daily Mail语料库的短文档。
- 任务:要求每个LLM对这些文档进行摘要。
- 评估:使用HHEM模型评估摘要的事实一致性,计算幻觉率。
- 指标:主要包括幻觉率、事实一致性率、回答率和平均摘要长度。
排行榜结果
根据最新的排行榜(截至2024年8月23日),部分主要模型的表现如下:
- Zhipu AI GLM-4-9B-Chat: 幻觉率1.3%,事实一致性率98.7%
- GPT-4: 幻觉率1.8%,事实一致性率98.2%
- GPT-3.5-Turbo: 幻觉率1.9%,事实一致性率98.1%
- Mistral-Large2: 幻觉率4.1%,事实一致性率95.9%
- Google Gemini-Pro: 幻觉率7.7%,事实一致性率92.3%
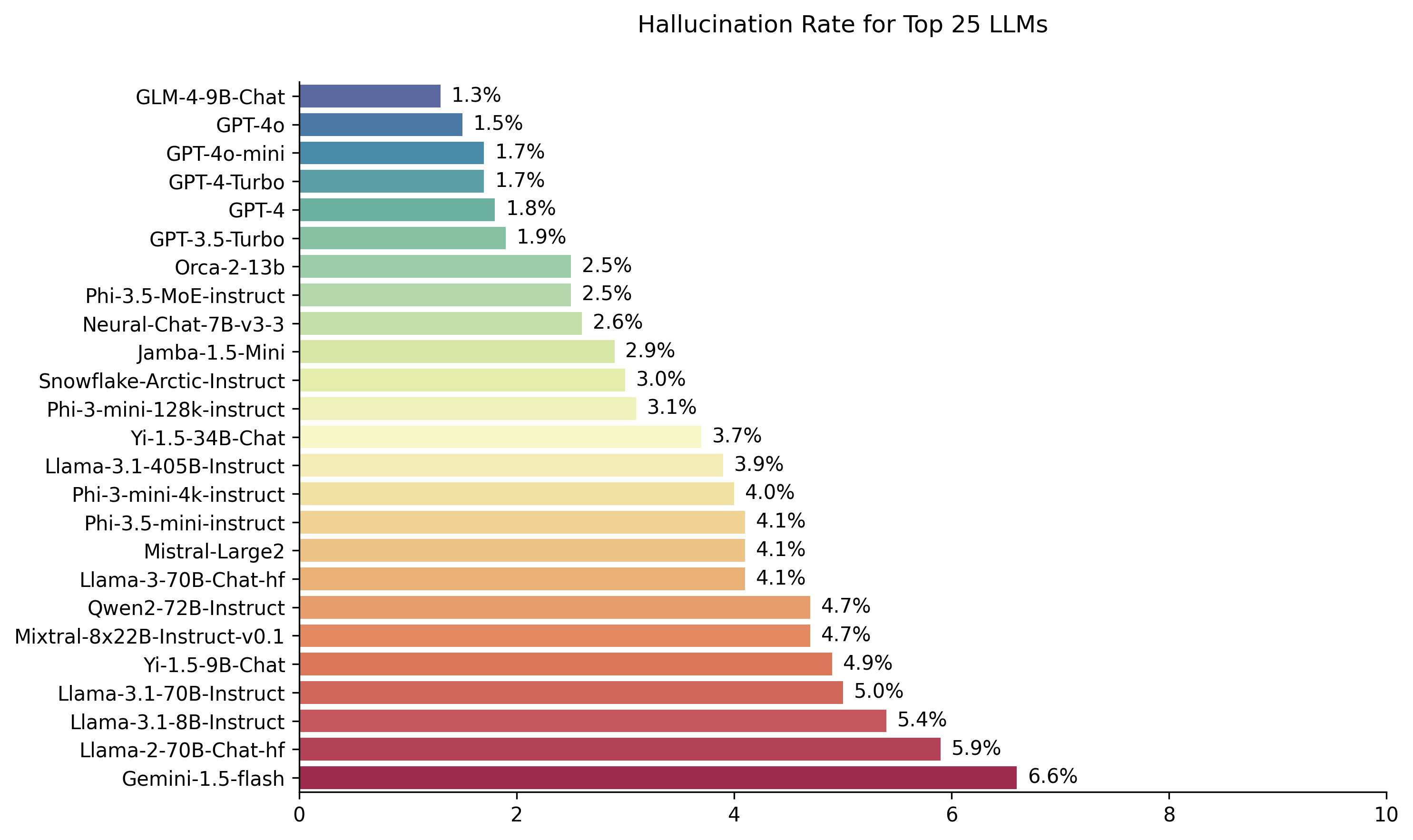
从结果可以看出,不同模型在幻觉控制方面存在显著差异。一些较新的模型如Zhipu AI GLM-4和GPT-4表现出色,而一些较早的模型则幻觉率相对较高。
排行榜的局限性
尽管这个排行榜为评估LLM的事实一致性提供了有价值的参考,但也存在一些局限性:
- 仅针对摘要任务:评估仅基于文档摘要任务,可能无法完全反映模型在其他任务中的表现。
- 评估模型本身的局限性:使用模型评估模型可能存在偏差。
- 可能被"游戏化":模型可能通过简单复制原文等方式获得高分,而非真正提高事实一致性。
- 语言限制:目前主要针对英语,尚未覆盖其他语言。
未来展望
Vectara公司表示,他们计划在未来进一步完善和扩展这个排行榜:
- 添加引用准确性评估:衡量模型在基于搜索结果回答问题时的引用准确性。
- 扩展到其他RAG(检索增强生成)任务:如多文档摘要等。
- 增加多语言支持:计划开发覆盖100多种语言的幻觉检测器。
- 持续更新:随着新模型的发布和现有模型的更新,排行榜将不断更新。
结语
大型语言模型幻觉排行榜的推出,为AI领域解决幻觉问题提供了一个重要的评估工具和参考标准。尽管还存在一些局限性,但它无疑推动了整个行业在提高模型事实一致性方面的努力。随着评估方法的不断完善和覆盖范围的扩大,我们有理由期待未来的LLM在可靠性和准确性方面会有更大的突破。
对于研究人员、开发者和用户来说,关注这个排行榜可以帮助我们更好地理解和选择适合特定任务的LLM。同时,它也提醒我们在使用这些强大的AI工具时,始终保持批判性思维,不盲目相信模型输出的每一个细节。
随着技术的进步,减少AI幻觉将继续成为一个重要的研究方向。通过开放、透明的评估和持续的改进,我们有望在未来看到更加可靠、更值得信赖的人工智能系统。









