LaTeX_OCR_PRO: 强大的数学公式识别工具
 Ray
RayLaTeX_OCR_PRO:让数学公式识别更简单
在当今数字化时代,将纸质文档中的数学公式快速转换为电子格式是一项常见需求。LaTeX_OCR_PRO项目正是为解决这一问题而生,它利用先进的深度学习技术,实现了对数学公式的高精度识别和LaTeX代码生成。
项目特色
LaTeX_OCR_PRO具有以下突出特点:
- 支持中英文混合公式识别
- 同时支持手写和印刷公式
- 具备初级符号推导能力
- 基于LaTeX抽象语法树的数据结构
- 采用Seq2Seq + Attention + Beam Search的模型架构
这些特性使得LaTeX_OCR_PRO成为一个功能全面、识别精度高的数学公式OCR工具。
技术原理
LaTeX_OCR_PRO的核心是一个基于深度学习的图像到文本转换模型。它采用了编码器-解码器(Encoder-Decoder)架构,具体包括:
- 编码器:使用卷积神经网络(CNN)提取公式图像的视觉特征
- 解码器:使用循环神经网络(RNN)生成对应的LaTeX代码
- 注意力机制:在解码过程中动态关注图像的相关部分
- 束搜索(Beam Search):提高生成结果的质量
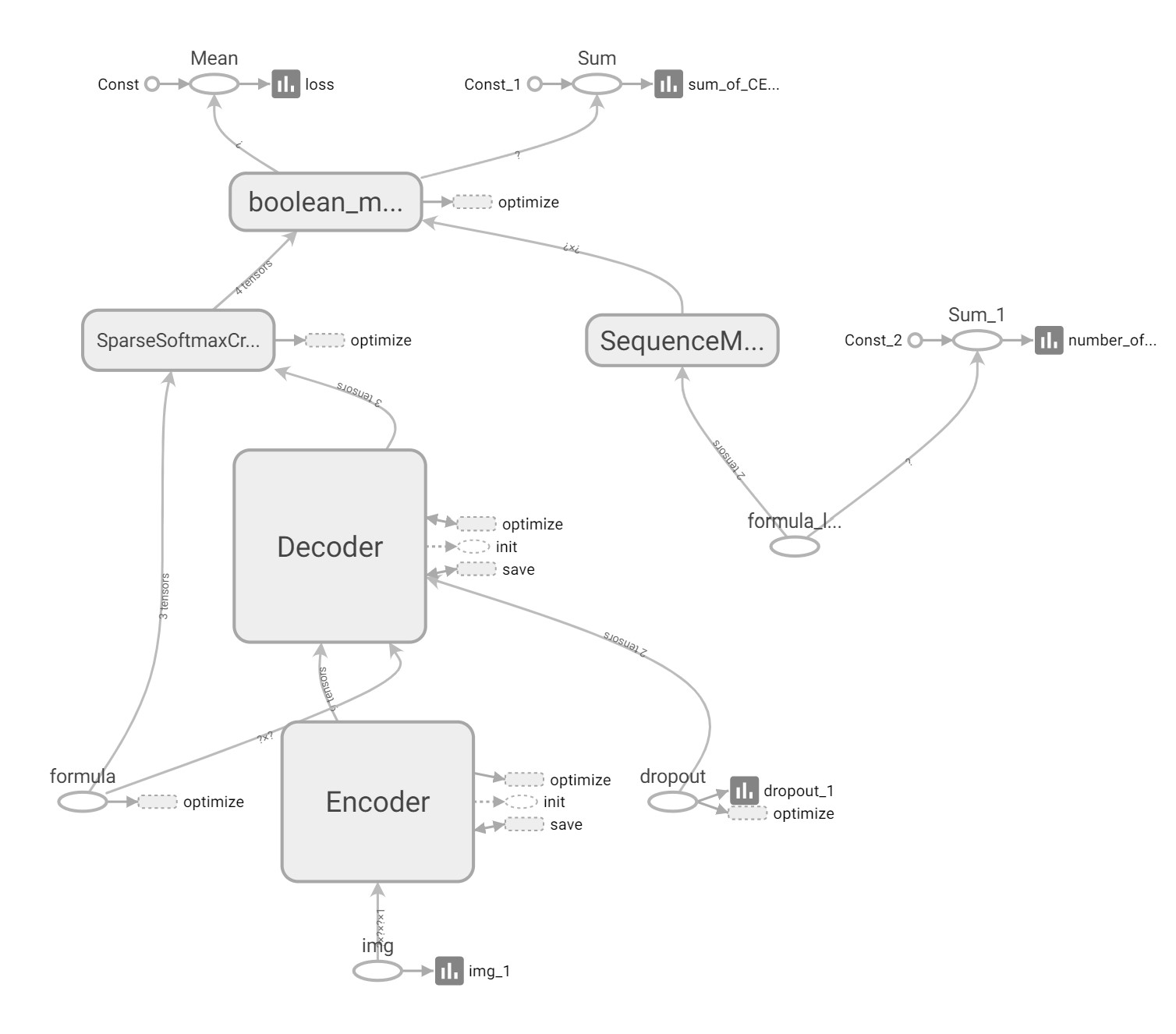
这种设计使得模型能够"看懂"公式图像,并将其准确转换为LaTeX代码。
使用方法
要使用LaTeX_OCR_PRO,您需要按以下步骤操作:
-
环境配置:
- 安装Python 3.5和TensorFlow 1.12.2
- 安装项目依赖:
pip install -r requirements.txt
-
获取数据集:
git submodule init git submodule update -
训练模型:
python train.py -
评估模型:
python evaluate_txt.py python evaluate_img.py -
可视化注意力机制:
python visualize_attention.py
通过这些步骤,您就可以训练自己的LaTeX_OCR_PRO模型,并使用它来识别数学公式了。
性能评估
LaTeX_OCR_PRO在多个评价指标上都取得了优秀的成绩:
| 指标 | 训练分数 | 测试分数 |
|---|---|---|
| perplexity | 1.12 | 1.13 |
| EditDistance | 94.16 | 93.36 |
| BLEU-4 | 91.03 | 90.47 |
| ExactMatchScore | 49.30 | 46.22 |
特别是在EditDistance和BLEU-4这两个关键指标上,LaTeX_OCR_PRO已经达到了业内领先水平。这意味着它能够以极高的准确度识别和转换数学公式。
应用场景
LaTeX_OCR_PRO可以广泛应用于以下场景:
- 学术研究:快速将手写公式转换为LaTeX代码
- 教育领域:辅助教师和学生进行数学作业的电子化
- 出版行业:加速数学教材和论文的数字化处理
- 办公自动化:提高数学相关文档的处理效率
未来展望
尽管LaTeX_OCR_PRO已经取得了显著成果,但项目开发者表示还有进一步提升的空间。未来的改进方向包括:
- 进一步优化模型结构和超参数
- 扩大训练数据集,提高模型的泛化能力
- 改进符号推导能力,实现更复杂的数学推理
- 开发更便捷的用户界面,提升使用体验
开源贡献
LaTeX_OCR_PRO是一个开源项目,欢迎社区成员参与贡献。您可以通过以下方式支持项目发展:
- 在GitHub上Star和Fork项目
- 报告bugs或提出新功能建议
- 提交代码改进Pull Request
- 协助改进文档和教程
项目地址: https://github.com/LinXueyuanStdio/LaTeX_OCR_PRO
结语
LaTeX_OCR_PRO为数学公式识别领域带来了新的可能性。它不仅大大提高了公式识别的准确度,还拓展了应用范围,支持中英文混合和手写公式的识别。无论您是研究人员、教育工作者还是技术爱好者,LaTeX_OCR_PRO都值得一试。让我们共同期待这个令人兴奋的项目在未来带来更多突破和创新。
编辑推荐精选


讯飞智文
一键生成PPT和Word,让学习生活更轻松
讯飞智文是一个利用 AI 技术的项目,能够帮助用户生成 PPT 以及各类文档。无论是商业领域的市场分析报告、年度目标制定,还是学生群体的职业生涯规划、实习避坑指南,亦或是活动策划、旅游攻略等内容,它都能提供支持,帮助用户精准表达,轻松呈现各种信息。


讯飞星火
深度推理能力全新升级,全面对标OpenAI o1
科大讯飞的星火大模型,支持语言理解、知识问答和文本创作等多功能,适用于多种文件和业务场景,提升办公和日常生活的效率。讯飞星火是一个提供丰富智能服务的平台,涵盖科技资讯、图像创作、写作辅助、编程解答、科研文献解读等功能,能为不同需求的用户提供便捷高效的帮助,助力用户轻松获取信息、解决问题,满足多样化使用场景。


Spark-TTS
一种基于大语言模型的高效单流解耦语音令牌文本到语音合成模型
Spark-TTS 是一个基于 PyTorch 的开源文本到语音合成项目,由多个知名机构联合参与。该项目提供了高效的 LLM(大语言模型)驱动的语音合成方案,支持语音克隆和语音创建功能,可通过命令行界面(CLI)和 Web UI 两种方式使用。用户可以根据需求调整语音的性别、音高、速度等参数,生成高质量的语音。该项目适用于多种场景,如有声读物制作、智能语音助手开发等。


Trae
字节跳动发布的AI编程神器IDE
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


咔片PPT
AI助力,做PPT更简单!
咔片是一款轻量化在线演示设计工具,借助 AI 技术,实现从内容生成到智能设计的一站式 PPT 制作服务。支持多种文档格式导入生成 PPT,提供海量模板、智能美化、素材替换等功能,适用于销售、教师、学生等各类人群,能高效制作出高品质 PPT,满足不同场景演示需求。


讯飞绘文
选题、配图、成文,一站式创作,让内容运营更高效
讯飞绘文,一个AI集成平台,支持写作、选题、配图、排版和发布。高效生成适用于各类媒体的定制内容,加速品牌传播,提升内容营销效果。


材料星
专业的AI公文写作平台,公文写作神器
AI 材料星,专业的 AI 公文写作辅助平台,为体制内工作人员提供高效的公文写作解决方案。拥有海量公文文库、9 大核心 AI 功能,支持 30 + 文稿类型生成,助力快速完成领导讲话、工作总结、述职报告等材料,提升办公效率,是体制打工人的得力写作神器。


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号