
Lightwood 简介
Lightwood 是一个创新的 AutoML 框架,其目标是简化数据科学和机器学习(DS/ML)的生命周期。它通过允许用户专注于他们想要对数据做什么,而无需编写重复的机器学习和数据准备样板代码,从而使 DS/ML 流程变得更加简单。Lightwood 的核心理念是让用户能够专注于模型中真正独特和定制的部分。
多样化的数据类型支持
Lightwood 支持多种数据类型,包括:
- 数字
- 日期
- 类别
- 标签
- 文本
- 数组
- 各种多媒体格式
这些数据类型可以组合在一起解决复杂的问题。此外,Lightwood 还支持时间序列模式,用于处理行间依赖性的问题。
JSON-AI 语法
Lightwood 引入了一种称为 JSON-AI 的声明式语法。这种语法允许用户更改 Lightwood 自动生成的模型的任何部分。它概述了建模管道每个步骤的具体细节。用户可以:
- 覆盖默认值(例如,更改列的类型)
- 完全替换步骤,使用自己的方法(例如,为预测器使用随机森林模型)
Lightwood 从这种语法创建一个 "JSON-AI" 对象,然后可以用它自动生成 Python 代码来表示你的管道。
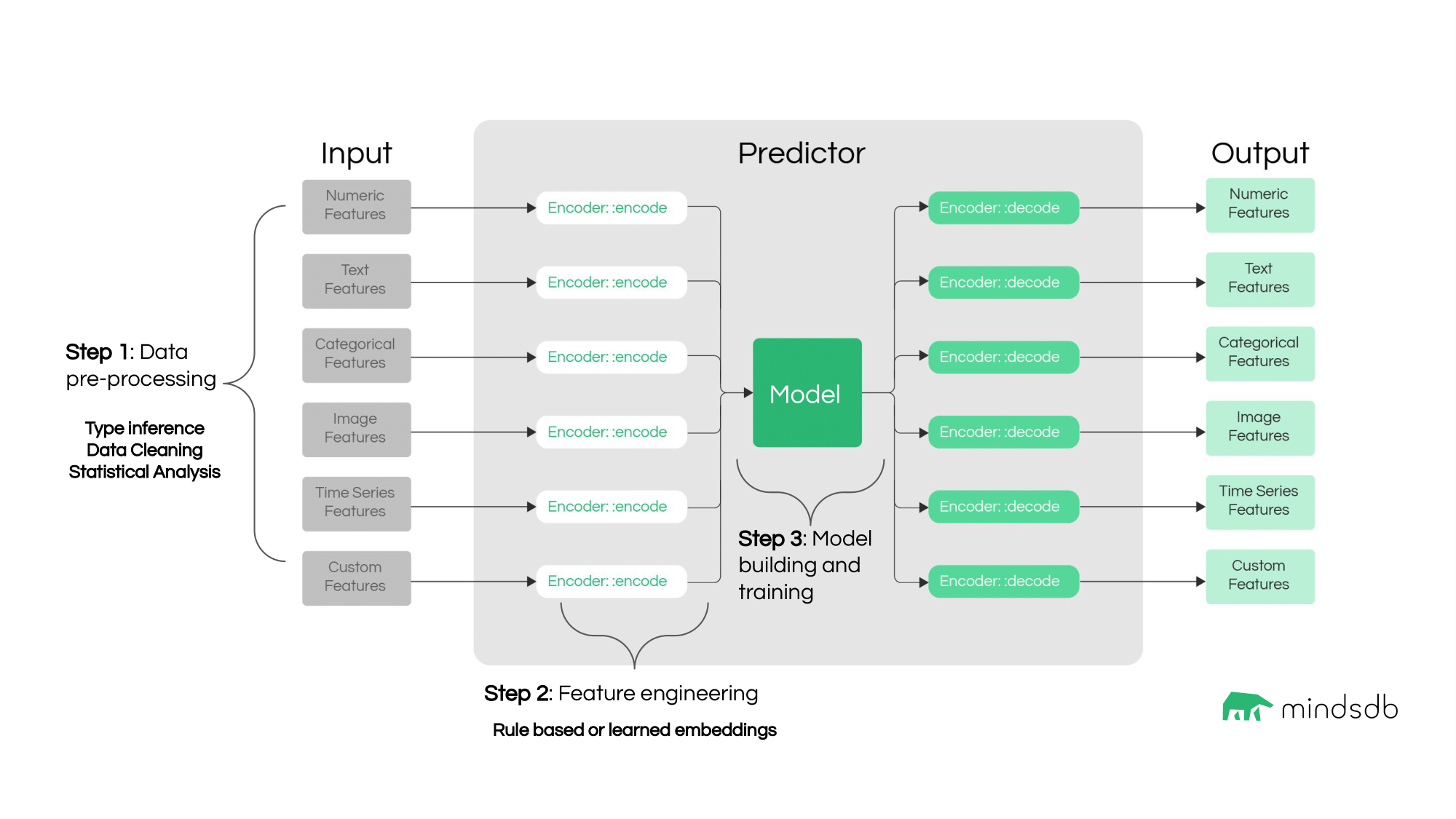
Lightwood 的核心组成
Lightwood 将 ML 管道抽象为 3 个核心步骤:
1. 预处理和数据清理
对于数据集中的每一列,Lightwood 会通过简短的统计分析来识别疑似的数据类型(数字、类别等)。从这里,它将生成一个 JSON-AI 语法。
如果用户保持默认行为,Lightwood 将根据识别的数据类型对每一列执行简短的预处理方法来清理数据。之后,它将数据分为训练/开发/测试集。
cleaner 和 splitter 对象分别指预处理和数据分割函数。
2. 特征工程
数据可以通过 "编码器" 转换为特征。编码器代表将预处理数据转换为模型可用的数值表示的规则。
编码器可以是基于规则的或学习型的:
- 基于规则的编码器根据特定的指令集转换数据(例如:归一化数值数据)
- 学习型编码器在训练后产生数据的表示(例如:语言模型中的 "[CLS]" 标记)
编码器根据数据类型分配给每列数据;用户可以在列级别或数据类型级别覆盖此分配。编码器继承自 BaseEncoder 类。
3. 模型构建和训练
Lightwood 将接收编码特征数据并输出目标预测的预测模型称为 mixer 模型。用户可以使用 Lightwood 的默认混合器,也可以创建自己的方法,继承自 BaseMixer 类。
Lightwood 主要使用基于 PyTorch 的方法,但也支持其他模型。
使用 Lightwood
Lightwood 的使用非常直观。以下是一个快速使用案例:
-
首先,Lightwood 使用
pandas.DataFrames工作。加载数据帧后,通过字典定义 "ProblemDefinition"。用户只需指定要预测的列名(通过target键)。 -
使用
json_ai_from_problem命令创建 JSON-AI 语法。 -
Lightwood 可以使用这个对象通过
code_from_json_ai自动生成填充 ML 管道步骤的 Python 代码。 -
可以通过
predictor_from_code使用该代码实例化Predictor对象。 -
要从未处理的数据开始端到端训练
Predictor,用户可以使用带有数据的predictor.learn()命令。
以下是一个具体的代码示例:
import pandas as pd
from lightwood.api.high_level import (
ProblemDefinition,
json_ai_from_problem,
code_from_json_ai,
predictor_from_code,
)
if __name__ == '__main__':
# 加载 pandas 数据集
df = pd.read_csv("https://raw.githubusercontent.com/mindsdb/benchmarks/main/benchmarks/datasets/hdi/data.csv")
# 通过命名目标列来定义预测任务
pdef = ProblemDefinition.from_dict(
{
"target": "Development Index", # 你想要预测的列
}
)
# 生成 JSON-AI 代码来建模问题
json_ai = json_ai_from_problem(df, problem_definition=pdef)
# 生成 Python 代码
code = code_from_json_ai(json_ai)
# 从 Python 代码创建预测器
predictor = predictor_from_code(code)
# 从原始数据到最终预测器的端到端训练模型
predictor.learn(df)
# 进行训练/测试分割并显示几个示例的预测
test_df = predictor.split(predictor.preprocess(df))["test"]
preds = predictor.predict(test_df).iloc[:10]
print(preds)
自定义和扩展
Lightwood 的一大特色是其灵活性和可扩展性。它支持用户架构/方法,只要你遵循每个步骤中提供的抽象。
BYOM: 引入自己的模型
Lightwood 的教程提供了如何在管道中引入自定义功能的具体用例。你可以查看 "自定义清洁器"、"自定义分割器"、"自定义解释器" 和 "自定义混合器" 等教程,了解如何根据自己的需求定制 Lightwood。
安装和设置
安装 Lightwood 非常简单,你可以通过以下命令进行安装:
pip3 install lightwood
注意:根据你的环境,你可能需要使用 pip 而不是 pip3。
对于开发环境的设置,Lightwood 建议:
- Python 版本应在 >=3.8, < 3.11 范围内
- 克隆 Lightwood 仓库
- 执行
cd lightwood && pip install -r requirements.txt && pip install -r requirements_image.txt - 将其添加到 Python 路径中
社区和贡献
Lightwood 是一个开源项目,欢迎社区贡献。如果你有兴趣为 Lightwood 做出贡献,可以通过以下方式参与:
- 报告 bug
- 改进文档
- 解决问题
- 提出新功能
- 讨论功能实现
- 提交 bug 修复
- 使用自己的数据测试 Lightwood 并告诉我们结果如何
贡献代码时,Lightwood 遵循 "fork-and-pull" Git 工作流程。
结语
Lightwood 作为一个强大而灵活的 AutoML 框架,正在为机器学习的民主化做出重要贡献。通过简化 ML 流程,让更多开发者能够成为数据科学家,Lightwood 正在推动 AI 技术的普及和创新。无论你是经验丰富的数据科学家还是刚刚开始探索 ML 领域的新手,Lightwood 都为你提供了一个强大的工具,帮助你更快、更高效地构建和部署机器学习模型。
加入 Lightwood 社区,开始你的机器学习之旅吧!🚀 Together, let's build the future of AI! 💡









