
Lion项目:从专有大模型中提取精华的对抗性蒸馏框架
在人工智能和自然语言处理领域,大型语言模型(LLM)的发展日新月异。然而,许多顶尖的LLM都是封闭源代码的专有模型,这在一定程度上限制了学术界和开源社区的创新。针对这一挑战,来自多所高校的研究人员提出了一个名为"Lion"的创新项目,旨在通过对抗性蒸馏的方法,从专有的大型语言模型中提取知识,训练出一个小型但高性能的开源语言模型。
Lion项目概述
Lion项目的核心是一个新颖的对抗性蒸馏框架,该框架巧妙地利用了一个封闭源的大型语言模型来同时扮演教师、裁判和生成器三种角色,从而训练出一个更小巧但性能出色的学生模型。这个过程分为三个主要阶段:
- 模仿阶段:让学生模型的输出与教师模型对齐
- 鉴别阶段:识别出具有挑战性的样本
- 生成阶段:产生新的难样本以提高学生模型的能力
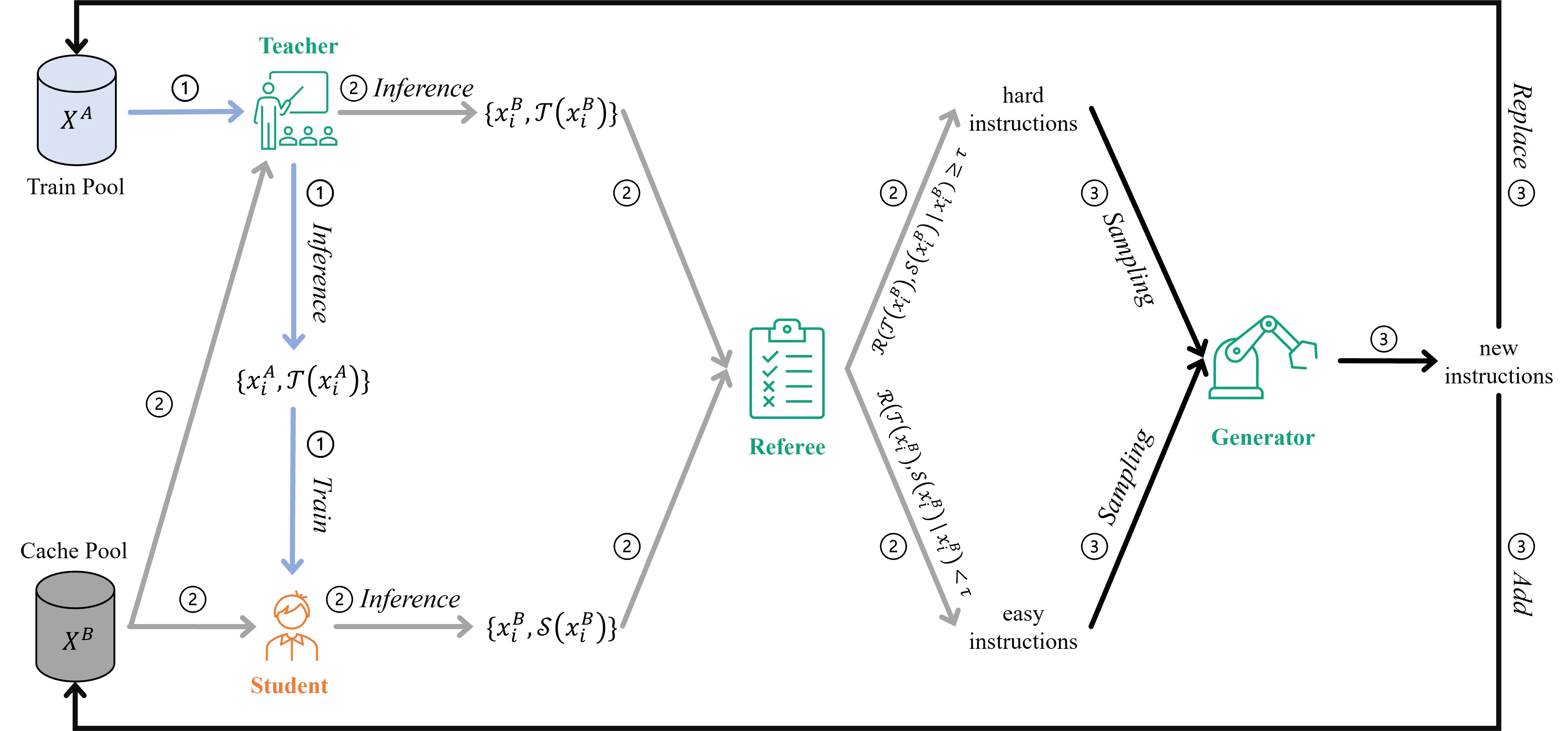
这种创新的方法使得Lion能够在保持较小模型规模的同时,达到接近大型专有模型的性能。
Lion模型的特点与优势
-
开源性: Lion模型是完全开源的,这使得研究人员和开发者可以自由地使用、研究和改进该模型。
-
高效性: 通过对抗性蒸馏,Lion在保持较小模型规模的同时,能够获得接近大型专有模型的性能。
-
灵活性: Lion框架可以适用于各种规模的语言模型,为不同应用场景提供了灵活的选择。
-
创新性: 项目提出的对抗性蒸馏框架是一种新颖的方法,为语言模型的知识提取和压缩开辟了新的研究方向。
Lion模型的训练过程
Lion模型的训练过程是一个迭代的过程,每次迭代包含了前面提到的三个主要阶段。以下是对这个过程的详细解析:
1. 模仿阶段
在这个阶段,学生模型(Lion)会学习模仿教师模型(专有大型语言模型)的输出。具体步骤包括:
- 获取教师模型对训练池中样本的响应
- 基于教师模型的响应对学生模型进行指令微调
这个过程使用了分布式训练技术,以提高训练效率:
torchrun --nproc_per_node=8 --master_port=<your_random_port> src/train.py \
--model_name_or_path <path_to_hf_converted_ckpt_and_tokenizer> \
--data_path <path_to_chatgpt_inference_for_the_Train_Pool> \
--bf16 True \
--output_dir result \
--num_train_epochs 3 \
--model_max_length 1024 \
--per_device_train_batch_size 2 \
--per_device_eval_batch_size 2 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 600 \
--save_total_limit 1 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--fsdp "full_shard auto_wrap" \
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer' \
--tf32 True
2. 鉴别阶段
在鉴别阶段,系统会识别出对学生模型具有挑战性的样本。这个过程包括:
- 获取教师模型和学生模型对缓存池中样本的响应
- 使用裁判模型(同样是专有大型语言模型)评估两个模型的响应质量
- 根据评分结果,区分出难样本和易样本
这个阶段的关键在于利用专有模型的判断能力,找出学生模型需要改进的方面。
3. 生成阶段
生成阶段旨在创造新的难样本,以进一步挑战和改进学生模型。这个阶段包括:
- 基于已识别的难样本,生成新的难指令
- 同时也生成一些新的易指令,以保持数据的平衡
通过这种方式,Lion模型能够不断地接受新的挑战,持续提升其性能。
Lion模型的评估结果
Lion模型在多个任务上展现出了优秀的性能,特别是在开放式生成和推理任务中。
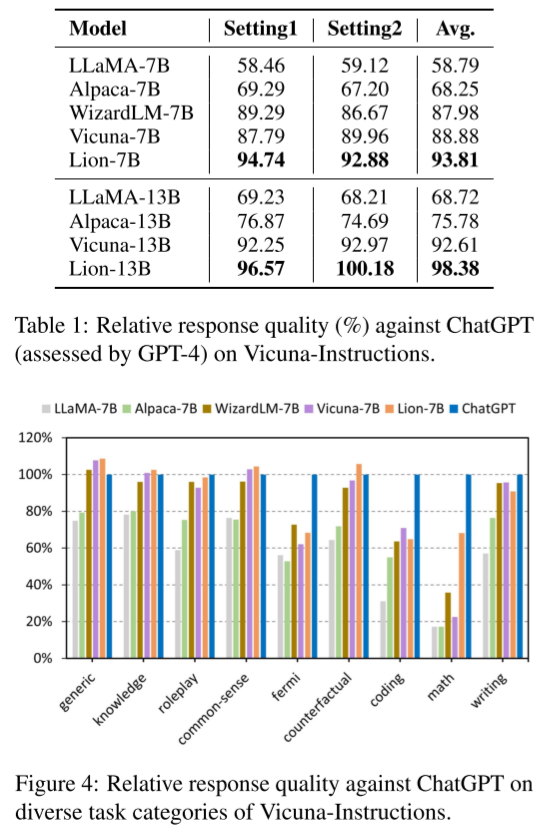
开放式生成任务
在开放式生成任务中,Lion模型的表现接近于ChatGPT,显示出其强大的生成能力。评估方法使用GPT-4自动评估模型响应的质量(1-10分制),并将候选模型的得分与参考模型(ChatGPT)进行比较。
推理任务
在各种推理任务中,Lion模型也展现出了不俗的表现,在某些任务上甚至超越了一些知名的大型语言模型。
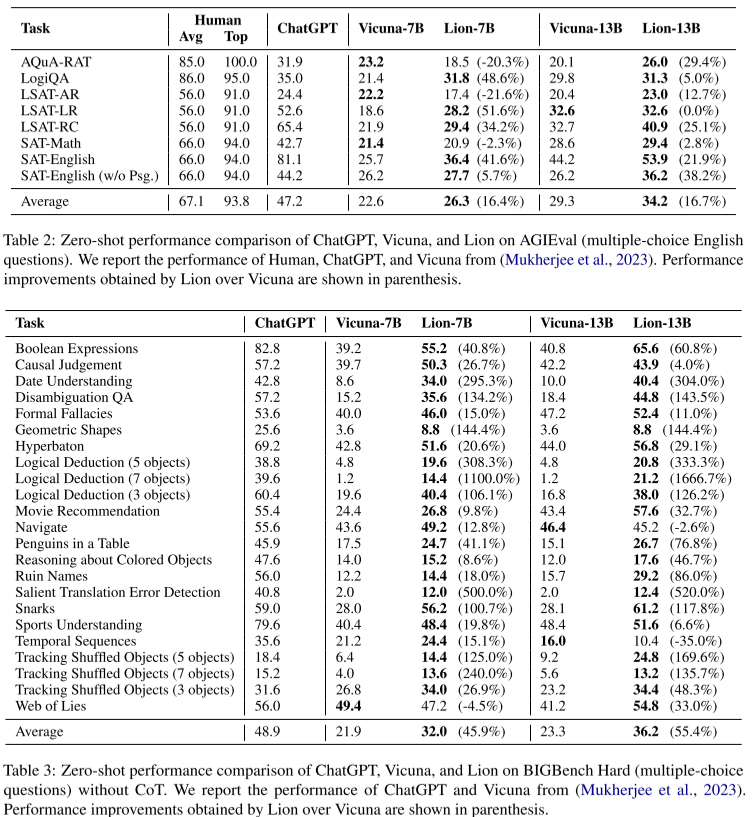
这些评估结果充分证明了Lion模型的有效性,展示了对抗性蒸馏框架在提取大型专有模型知识方面的潜力。
Lion项目的影响与未来展望
Lion项目为解决大型语言模型封闭源的问题提供了一个创新的解决方案。通过这种方法,研究人员和开发者可以在不直接访问专有模型的情况下,获得接近其性能的开源模型。这不仅推动了自然语言处理技术的民主化,也为未来的研究和应用开辟了新的可能性。
未来,Lion项目可能会在以下几个方面继续发展:
- 扩展模型规模: 探索在更大规模的模型上应用对抗性蒸馏技术。
- 多语言支持: 扩展Lion模型以支持更多语言,增强其全球应用潜力。
- 特定领域优化: 针对特定领域(如医疗、法律等)优化Lion模型,提高其在专业领域的应用价值。
- 持续学习: 研究如何使Lion模型能够持续学习和更新,以适应不断变化的语言环境和知识体系。
结语
Lion项目代表了语言模型研究的一个重要方向,即如何在保护知识产权的同时,促进技术的开放和创新。通过创新的对抗性蒸馏框架,Lion成功地从封闭源大型语言模型中提取了知识,创造出了一个性能优秀的开源模型。这不仅为自然语言处理领域提供了宝贵的资源,也为未来的研究和应用奠定了基础。
随着项目的不断发展和完善,我们可以期待看到更多基于Lion的创新应用,以及这种方法在其他领域的潜在应用。Lion项目的成功,无疑将推动整个人工智能和自然语言处理社区向着更开放、更创新的方向前进。
注意:Lion模型仅供研究使用,严禁商业用途。使用Lion生成的内容可能受到不可控变量的影响,accuracy无法保证。项目方不承担任何法律责任。










