LITv2: 快速视觉Transformer与HiLo注意力机制
 Ray
RayLITv2: 快速视觉Transformer的新突破
在计算机视觉领域,Transformer模型凭借其强大的特征提取和建模能力,正在逐步取代传统的卷积神经网络。然而,标准Transformer模型计算复杂度高、推理速度慢的问题一直是其广泛应用的瓶颈。为了解决这一问题,来自澳大利亚莫纳什大学的研究团队提出了LITv2(Less is More Transformer v2)模型,通过创新的HiLo注意力机制,在保持高精度的同时大幅提升了模型的推理速度。
HiLo注意力机制: LITv2的核心创新
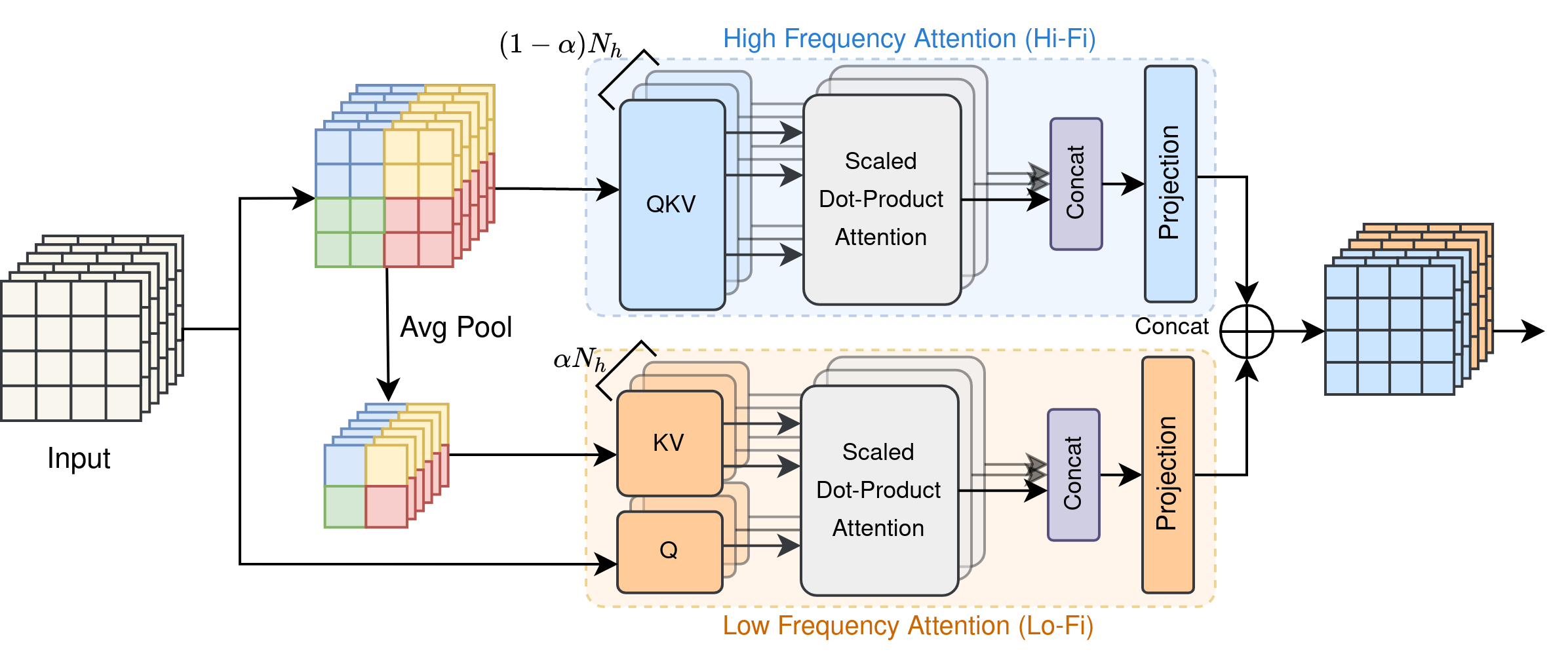
LITv2的核心创新在于其提出的HiLo(High-Low)注意力机制。这一机制的设计灵感来自于图像中高频和低频信息的不同特性:
- 高频信息捕捉局部细节
- 低频信息关注全局结构
传统的多头自注意力机制忽略了不同频率特征的这一特性。因此,HiLo注意力将注意力头分为两组:
- 高频组: 在每个局部窗口内进行自注意力计算,编码高频局部细节。
- 低频组: 对每个窗口的平均池化低频键进行注意力计算,建模全局关系。
通过这种设计,LITv2能够更有效地处理不同尺度的图像信息,在提高精度的同时降低计算复杂度。
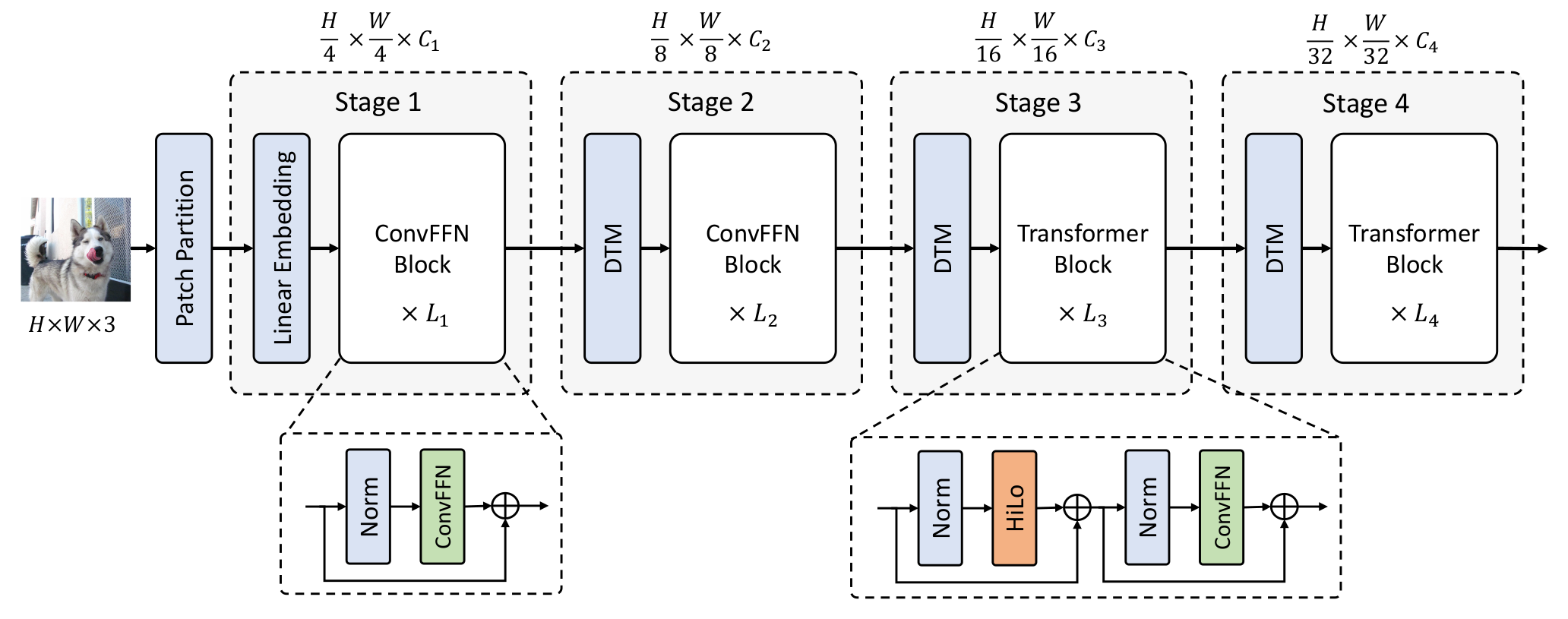
LITv2的模型架构
LITv2采用了类似ViT(Vision Transformer)的整体架构,但在每个Transformer块中使用HiLo注意力代替了标准的多头自注意力。具体来说,LITv2的架构包括:
- Patch Embedding: 将输入图像划分为固定大小的patch并进行线性投影
- 多个Transformer块:
- HiLo注意力层
- 前馈神经网络(FFN)层
- Layer Normalization
- 分类头: 用于最终的预测输出
这种设计使得LITv2能够在保持Transformer强大建模能力的同时,显�著提高计算效率。
在多项视觉任务上的卓越表现
研究团队在多个主流视觉任务上评估了LITv2的性能,包括图像分类、目标检测和语义分割。结果表明,LITv2在各种模型规模下都能实现优于现有最先进方法的性能,同时具有更快的推理速度。
图像分类
在ImageNet-1K数据集上,LITv2展现了出色的分类性能:
| 模型 | 参数量(M) | FLOPs(G) | 吞吐量(imgs/s) | Top-1准确率(%) |
|---|---|---|---|---|
| LITv2-S | 28 | 3.7 | 1,471 | 82.0 |
| LITv2-M | 49 | 7.5 | 812 | 83.3 |
| LITv2-B | 87 | 13.2 | 602 | 83.6 |
值得注意的是,LITv2-S模型在仅有28M参数的情况下,就达到了82.0%的Top-1准确率,展现了极高的参数效率。
目标检测
研究团队还在COCO 2017数据集上评估了LITv2在目标检测任务上的性能。以RetinaNet为检测器,LITv2作为骨干网络,在1x训练调度(12个epoch)下取得了如下结果:
| 骨干网络 | 窗口大小 | 参数量(M) | FLOPs(G) | FPS | box AP |
|---|---|---|---|---|---|
| LITv2-S | 2 | 38 | 242 | 18.7 | 44.0 |
| LITv2-M | 2 | 59 | 348 | 12.2 | 46.0 |
| LITv2-B | 2 | 97 | 481 | 9.5 | 46.7 |
这些结果表明,LITv2不仅在分类任务上表现出色,在目标检测这样的下游任务中同样能够取得competitive的性能。
语义分割
在ADE20K数据集上的语义分割任务中,LITv2同样展现了强大的性能:
| 骨干网络 | 参数量(M) | FLOPs(G) | FPS | mIoU |
|---|---|---|---|---|
| LITv2-S | 31 | 41 | 42.6 | 44.3 |
| LITv2-M | 52 | 63 | 28.5 | 45.7 |
| LITv2-B | 90 | 93 | 27.5 | 47.2 |
这进一步证明了LITv2作为通用视觉骨干网络的潜力,能够在多种视觉任务中提供出色的特征表示。
与其他模型的性能对比
为了更全面地评估LITv2的性能,研究团队将其与多个主流的视觉Transformer和CNN模型进行了对比。在相似的参数量和计算复杂度下,LITv2-S模型展现出了最佳的性能-效率权衡:
| 模型 | 参数量(M) | FLOPs(G) | RTX 3090吞吐量(imgs/s) | Top-1准确率(%) |
|---|---|---|---|---|
| ResNet-50 | 26 | 4.1 | 1,279 | 80.4 |
| Swin-Ti | 28 | 4.5 | 961 | 81.3 |
| ConvNext-Ti | 28 | 4.5 | 1,079 | 82.1 |
| LITv2-S | 28 | 3.7 | 1,471 | 82.0 |
可以看到,LITv2-S在参数量和计算量都较低的情况下,实现了最快的推理速度和competitive的分类准确率。这充分证明了HiLo注意力机制在提升模型效率方面的有效性。
LITv2的实际应用与部署
得益于其出色的性能和效率,LITv2在多个实际应用场景中展现了巨大潜力:
-
移动设备上的视觉应用: LITv2-S模型小巧高效,非常适合部署在计算资源有限的移动设备上。
-
大规模视频分析: 在视频监控、自动驾驶等需要实时处理大量视频流的场景中,LITv2的高效率可以显著提升系统的整体性能。
-
医学图像分析: LITv2在语义分割任务上的出色表现,使其成为医学图像分割(如器官分割、肿瘤检测)的理想选择。
-
工业视觉检测: 在工业生产线上的实时缺陷检测等应用中,LITv2可以提供快速准确的视觉分析能力。
为了便于研究者和开发者使用LITv2,项目团队提供了完整的PyTorch实现和预训练模型。此外,他们还支持将LITv2模型转换为ONNX和TensorRT格式,以实现更高效的推理部署。
未来研究方向
尽管LITv2已经在多个方面展现出了优秀的性能,但研究团队认为仍有进一步改进的空间:
-
探索更优的α值: α参数控制着高频和低频注意力头的比例,进一步研究最佳的α值可能带来性能的提升。
-
动态窗口大小: 目前LITv2使用固定的窗口大小,未来可以探索根据输入动态调整窗口大小的方法。
-
跨模态应用: 将HiLo注意力机制扩展到视觉-语言等跨模态任务中,可能带来新的突破。
-
硬件加速优化: 针对HiLo注意力机制设计专门的硬件加速方案,进一步提升推理速度。
结论
LITv2通过创新的HiLo注意力机制,成功地在视觉Transformer的精度和效率之间取得了优秀的平衡。它不仅在多个视觉任务上达到了state-of-the-art的性能,还展现出了卓越的推理速度和资源效率。这使得LITv2成为一个非常有前景的通用视觉骨干网络,有望在学术研究和工业应用中发挥重要作用。
随着深度学习技术不断发展,像LITv2这样兼顾性能和效率的模型将会越来越受到关注。我们期待看到更多基于LITv2的创新应用,以及它在推动计算机视觉技术进步方面的贡献。
编辑推荐精选


讯飞智文
一键生成PPT和Word,让学习生活更轻松
讯飞智文是一个利用 AI 技术的项目,能够帮助用户生成 PPT 以及各类文档。无论是商业领域的市场分析报告、年度目标制定,还是学生群体的职业生涯规划、实习避坑指南,亦或是活动策划、旅游攻略等内容,它都能提供支持,帮助用户精准表达,轻松呈现各种信息。


讯飞星火
深度推理能力全新升级,全面对标OpenAI o1
科大讯飞的星火大模型,支持语言理解、知识问答和文本创作等多功能,适用于多种文件和业务场景,提升办公和日常生活的效率。讯飞星火是一个提供丰富智能服务的平台,涵盖科技资讯、图像创作、写作辅助、编程解答、科研文献解读等功能,能为不同需求的用户提供便捷高效的帮助,助力用户轻松获取信息、解决问题,满足多样化使用场景。


Spark-TTS
一种基于大语言模型的高效单流解耦语音令牌文本到语音合成模型
Spark-TTS 是一个基于 PyTorch 的开源文本到语音合成项目,由多个知名机构联合参与。该项目提供了高效的 LLM(大语言模型)驱动的语音合成方案,支持语音克隆和语音创建功能,可通过命令行界面(CLI)和 Web UI 两种方式使用。用户可以根据需求调整语音的性别、音高、速度等参数,生成高质量的语音。该项目适用于多种场景,如有声读物制作、智能语音助手开发等。


Trae
字节跳动发布的AI编程神器IDE
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上��下文感知和代码自动完成功能,是提升开发效率的理想工具。


咔片PPT
AI助力,做PPT更简单!
咔片是一款轻量化在线演示设计工具,借助 AI 技术,实现从内容生成到智能设计的一�站式 PPT 制作服务。支持多种文档格式导入生成 PPT,提供海量模板、智能美化、素材替换等功能,适用于销售、教师、学生等各类人群,能高效制作出高品质 PPT,满足不同场景演示需求。


讯飞绘文
选题、配图、成文,一站式创作,让内容运营更高效
讯飞绘文,一个AI集成平台,支持写作、选题、配图、排版和发布。高效生成适用于各类媒体的定制内容,加速品牌传播,提升内容营销效果。


材料星
专业的AI公文写作平台,公文写作神器
AI 材料星,专业的 AI 公文写作辅助平台,为体制内工作人员提供高效的公文写作解决方案。拥有海量公文文库、9 大核心 AI 功能,支持 30 + 文稿类型生成,助力快速完成领导讲话、工作总结、述职报告等材料,提升办公效率,是体制打工人的得力写作神器。


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的��分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号