
Llama-2-JAX项目简介
Llama-2-JAX是一个使用JAX框架实现Llama 2大型语言模型的开源项目。该项目由GitHub用户ayaka14732发起,旨在通过JAX实现Llama 2模型,以实现在Google Cloud TPU上的高效训练和推理。
项目的主要目标包括:
- 使用JAX实现Llama 2模型,以在Google Cloud TPU上实现高效的训练和推理;
- 开发高质量的代码库,作为使用JAX实现Transformer模型的范例;
- 通过高质量代码库的实现,帮助识别各种transformer模型中的常见错误和不一致性,为NLP社区提供有价值的见解。
该项目得到了Google TPU Research Cloud (TRC)提供的Cloud TPUs的支持。
项目特性
Llama-2-JAX项目实现了Llama 2模型的多个关键特性,包括:
- 参数转换:支持Hugging Face格式和JAX格式之间的参数转换。
- 数据加载:实现了高效的数据加载机制。
- 模型架构:包括dropout、RMS归一化、嵌入、旋转位置编码、注意力机制等核心组件。
- 交叉熵损失:实现了用于训练的交叉熵损失函数。
- 训练:支持数据并行和模型并行等并行化方案。
- 生成:实现了KV缓存、左侧填充、存在惩罚等生成策略。
- 文档:提供了详细的项目文档。
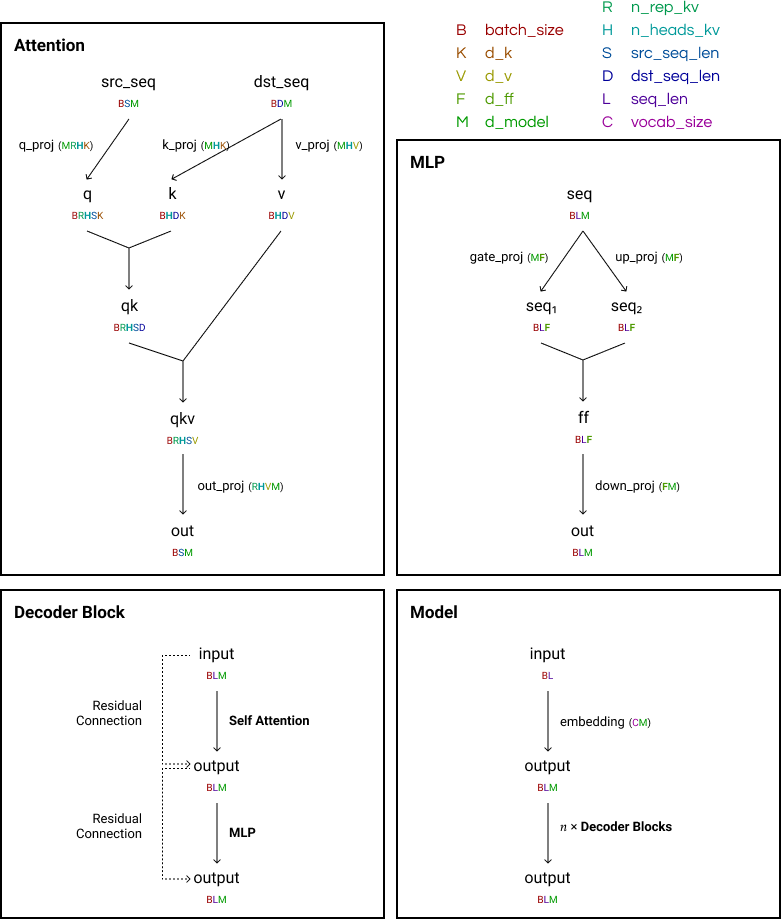
图1: Llama模型架构图
环境配置
Llama-2-JAX项目对环境有一些特定要求:
- Python 3.11或更高版本
- JAX 0.4.19
- PyTorch 2.1.0
- Optax 0.1.8.dev0
- Transformers 4.35.0.dev0
项目提供了详细的环境配置指南,包括安装Python、创建虚拟环境、安装JAX和PyTorch等步骤。对于在TPU pods上运行的用户,还提供了特殊的配置说明。
模型配置
Llama-2-JAX支持多种Llama模型配置,包括:
- LLaMA 1 7B
- Llama 2 7B
- LLaMA 1 13B
- Llama 2 13B
- LLaMA 1 33B
- LLaMA 1 65B
- Llama 2 70B
每种配置都有其特定的参数设置,如词汇表大小、层数、注意力头数等。项目文档中提供了详细的配置表格,方便用户选择和使用不同规模的模型。
模型架构
Llama-2-JAX项目实现了Llama模型的完整架构。以Llama 2 (70B)为例,其Hugging Face格式的架构如下:
LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(32000, 8192, padding_idx=0)
(layers): ModuleList(
(0-79): 80 x LlamaDecoderLayer(
(self_attn): LlamaAttention(
(q_proj): Linear(in_features=8192, out_features=8192, bias=False)
(k_proj): Linear(in_features=8192, out_features=1024, bias=False)
(v_proj): Linear(in_features=8192, out_features=1024, bias=False)
(o_proj): Linear(in_features=8192, out_features=8192, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=8192, out_features=28672, bias=False)
(up_proj): Linear(in_features=8192, out_features=28672, bias=False)
(down_proj): Linear(in_features=28672, out_features=8192, bias=False)
(act_fn): SiLUActivation()
)
(input_layernorm): LlamaRMSNorm()
(post_attention_layernorm): LlamaRMSNorm()
)
)
(norm): LlamaRMSNorm()
)
(lm_head): Linear(in_features=8192, out_features=32000, bias=False)
)
Llama-2-JAX项目使用了稍微不同的格式来实现这一架构,以更好地适应JAX框架的特性。
研究发现
通过实现Llama-2-JAX项目,研究者们得出了一些关于Llama模型的有趣发现:
- Llama使用旋转位置编码(rotary positional embeddings)。
- 在Q、K、V矩阵和前馈网络的线性投影中没有偏置项,这与原始Transformer相同,但与BERT和BART不同。
- Llama模型中的每个前馈网络有3个线性投影,而BART只有2个。
- 原始Llama实现中没有dropout。
- 原始实现中没有左侧填充。
- Llama 2 70B模型使用了分组查询注意力(Grouped-Query Attention, GQA)机制。
- 许多研究者在16位精度(float16或bfloat16)下微调Lama,但这可能会影响性能,与32位精度训练的其他模型相比可能不公平。值得注意的是,旋转嵌入的参数应始终保持32位精度,以避免碰撞。
这些发现为理解和改进Llama模型提供了宝贵的洞察。
结论
Llama-2-JAX项目为NLP研究社区提供了一个宝贵的资源,展示了如何使用JAX框架高效实现和训练大型语言模型。通过提供详细的文档、环境配置指南和模型实现,该项目不仅有助于推动Llama 2模型的研究和应用,还为使用JAX开发其他大型语言模型提供了有价值的参考。
研究者和开发者可以利用Llama-2-JAX项目来深入理解Llama 2模型的内部工作原理,进行性能优化实验,或者将其作为基础来开发新的模型架构。随着大型语言模型在各种应用中的重要性日益增加,像Llama-2-JAX这样的开源项目将继续在推动自然语言处理技术进步中发挥关键作用。

















