LLaMA-VID:革命性的长视频理解技术
在人工智能和计算机视觉的快速发展中,视觉语言模型(VLMs)在图像理解和短视频分析方面取得了巨大进展。然而,当面对长视频时,这些模型往往会遇到巨大的计算挑战。近日,来自香港中文大学的研究团队提出了一种突破性的方法 - LLaMA-VID,为长视频理解开辟了新的可能性。
创新的双令牌机制
LLaMA-VID的核心创新在于其独特的双令牌表示方法。与传统模型不同,LLaMA-VID为每一帧视频分配两个不同的令牌:
- 上下文令牌(Context Token):捕捉整体图像背景,基于用户输入进行编码。
- 内容令牌(Content Token):概括每一帧的视觉信息。
这种双令牌策略大大减少了处理长视频时的计算负担,同时保留了关键信息。这使得LLaMA-VID能够高效地处理长达数小时的视频内容,突破了现有视觉语言模型的局限性。
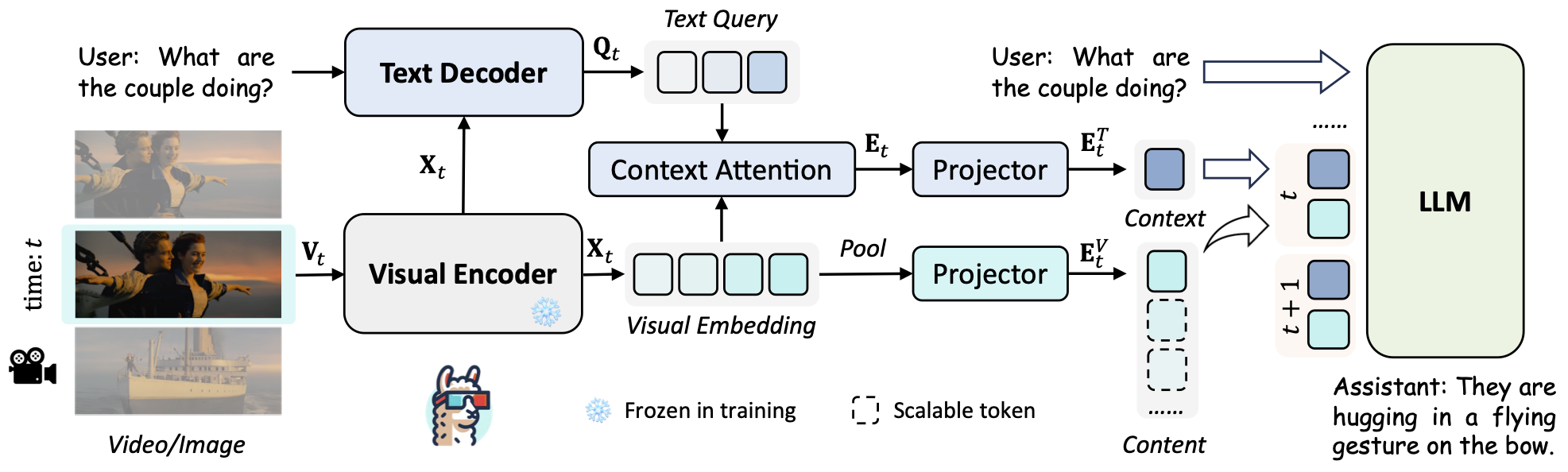
模型架构与训练
LLaMA-VID的架构主要包含三个部分:
- 编码器和解码器:分别用于生成视觉嵌入和文本引导特征。
- 令牌生成策略:将上下文令牌和内容令牌转换为模型可理解的形式。
- 指令微调:释放大型语言模型在图像和视频理解方面的潜力。
研究团队采用了多阶段的训练策略:
- 特征对齐阶段:桥接视觉和语言令牌。
- 指令微调阶段:教导模型遵循多模态指令。
- 长视频微调阶段:扩展位置嵌入,使模型能够处理长达数小时的视频指令。
卓越的性能表现
LLaMA-VID在多个图像和视频理解基准测试中展现出优异的性能:
-
图像理解任务:
- GQA: 65.0
- MME: 1542.3
- VQA v2: 80.0
-
视频理解任务:
- MSVD-QA: 70.0
- MSRVTT-QA: 58.9
- ActivityNet-QA: 47.5
这些结果表明,LLaMA-VID不仅在长视频处理方面取得突破,在各类视觉理解任务中也具有强大的通用能力。
广泛的应用前景
LLaMA-VID的突破性进展为长视频理解和分析开辟了广阔的应用前景:
- 电影分析:能够理解和分析长达数小时的电影内容,为影视行业提供深入洞察。
- 在线教育:处理长时间的教学视频,提供智能摘要和问答服务。
- 安防监控:长时间监控视频的自动分析和异常检测。
- 直播内容分析:实时理解和分类长时间的直播内容。
开源与社区贡献
研究团队秉持开放科学的精神,将LLaMA-VID的代码、模型和数据集开源,鼓励学术界和工业界的进一步探索和创新。感兴趣的研究者和开发者可以通过以下方式访问相关资源:
未来展望
LLaMA-VID的出现为视觉语言模型处理长视频开辟了新的研究方向。未来,我们可以期待:
- 模型效率的进一步提升,使其能在更低计算资源下运行。
- 跨模态理解能力的增强,结合音频等其他模态信息。
- 在更多垂直领域的应用和优化,如医疗影像分析、体育赛事回放等。
LLaMA-VID的创新为人工智能理解和分析长视频内容铺平了道路,相信在不久的将来,我们将看到更多基于此技术的突破性应用出现在我们的日常生活中。









