
LLM-Blender:通过配对排序和生成式融合集成大语言模型
近年来,随着大语言模型(Large Language Models, LLMs)的快速发展,各种开源LLMs如雨后春笋般涌现。这些模型在不同任务和场景下展现出各自的优势和特点。然而,如何有效地利用多个LLMs的优势,实现性能的进一步提升,成为了一个重要的研究课题。针对这一挑战,来自南加州大学和Allen人工智能研究所的研究团队提出了一个创新的框架——LLM-Blender。
LLM-Blender框架概述
LLM-Blender是一个旨在通过利用多个开源大语言模型的多样化优势来实现持续卓越性能的创新集成框架。该框架通过排序削弱模型的缺点,并通过融合生成来整合模型的优势,从而增强LLMs的整体能力。
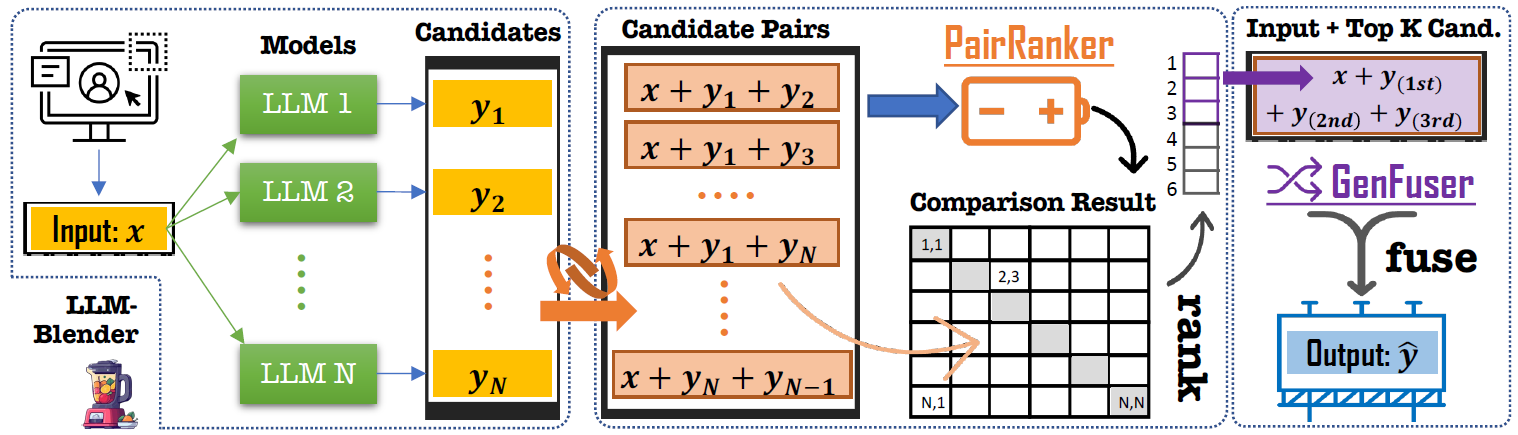
LLM-Blender框架主要由两个互补的模块组成:PairRanker和GenFuser。这两个模块共同解决了不同示例的最佳LLMs可能存在显著差异的问题。
PairRanker模块
PairRanker模块采用了一种专门的配对比较方法,用于区分候选输出之间的细微差异。它通过注意力机制,以配对的方式对DeBERTa-V3-Large (304m)检查点进行微调。PairRanker使用单个编码器对输入文本和两个候选进行编码,并分别为这两个候选输出两个预测分数。预期更好的候选会获得更高的分数。
与之前使用单独评分的方法不同,PairRanker可以通过双向注意力机制捕捉候选之间的细微差异,因此对候选的质量更加稳健。研究结果表明,PairRanker与基于ChatGPT的排名展现出最高的相关性。
GenFuser模块
GenFuser模块是一个transformer编码器-解码器结构,在Flan-T5-xl (3b)检查点上使用来自ChatGPT、GPT-4和人类的真实输出作为标签进行微调。它使用单个编码器对输入文本和几个候选进行编码,然后使用单个解码器解码融合后的输出。
GenFuser的目标是将PairRanker配对比较聚合后的顶级候选合并,通过利用它们的优势并减轻它们的弱点,生成一个改进的输出。与简单地将所有候选放入编码器不同,GenFuser只将排名靠前的候选放入编码器,以避免来自不良候选的不必要噪音,这是LLM-Blender成功的关键。
LLM-Blender的优势
-
配对比较的优势:通过PairRanker模块,LLM-Blender能够更精确地捕捉候选输出之间的细微差异,这在处理高质量LLM输出时尤为重要。
-
自适应融合:GenFuser模块能够根据不同输入和任务的需求,自适应地融合多个模型的优势,生成更优质的输出。
-
性能提升:实验结果表明,LLM-Blender在各种评估指标上显著优于单个LLMs和基线集成方法,建立了实质性的性能差距。
-
灵活性:LLM-Blender框架可以轻松集成新的LLMs,适应不断发展的AI生态系统。
MixInstruct:大规模评估数据集
为了便于进行大规模评估,研究团队还引入了一个基准数据集——MixInstruct。这是一个混合了多个指令数据集的数据集,具有用于测试目的的oracle配对比较。
MixInstruct的主要特点包括:
- 首个大规模数据集,包含11个流行开源LLMs在指令跟随数据集上的响应。
- 训练/验证/测试集分别包含100k/5k/5k个示例。
- 从4个著名的指令数据集收集而来:Alpaca-GPT4、Dolly-15k、GPT4All-LAION和ShareGPT。
- 真实输出来自ChatGPT、GPT-4或人工注释。
- 通过自动指标(如BLEURT、BARTScore、BERTScore等)和ChatGPT进行评估。
- 测试集中提供4771个由ChatGPT通过配对比较评估的示例。
LLM-Blender的应用场景
-
提高生成质量:通过集成多个LLMs的优势,LLM-Blender可以生成更高质量、更连贯的文本。
-
任务适应:不同的LLMs在不同类型的任务上可能表现各异,LLM-Blender可以根据具体任务选择最适合的模型组合。
-
减少偏见:通过融合多个模型的输出,可以在一定程度上减少单个模型可能存在的偏见。
-
增强鲁棒性:集成多个模型可以提高系统对异常输入或边缘情况的鲁棒性。
-
个性化服务:可以根据用户偏好或特定领域需求,调整LLM-Blender的权重,提供更个性化的服务。
LLM-Blender的使用方法
LLM-Blender提供了简单易用的API,使研究人员和开发者能够轻松地将其集成到现有项目中。以下是一些基本用法示例:
- 安装LLM-Blender:
pip install llm-blender
- 使用PairRanker进行模型输出排序:
import llm_blender
blender = llm_blender.Blender()
blender.loadranker("llm-blender/PairRM") # 加载ranker检查点
inputs = ["hello, how are you!", "I love you!"]
candidates_texts = [["get out!", "hi! I am fine, thanks!", "bye!"],
["I love you too!", "I hate you!", "Thanks! You're a good guy!"]]
ranks = blender.rank(inputs, candidates_texts, return_scores=False, batch_size=1)
- 使用GenFuser融合top-k候选:
blender.loadfuser("llm-blender/gen_fuser_3b") # 加载fuser检查点
from llm_blender.blender.blender_utils import get_topk_candidates_from_ranks
topk_candidates = get_topk_candidates_from_ranks(ranks, candidates_texts, top_k=3)
fuse_generations = blender.fuse(inputs, topk_candidates, batch_size=2)
- 一步完成排序和融合:
fuse_generations, ranks = blender.rank_and_fuse(inputs, candidates_texts, return_scores=False, batch_size=2, top_k=3)
LLM-Blender的未来发展
尽管LLM-Blender已经展现出了优秀的性能,但仍有许多潜在的改进和扩展方向:
-
动态权重调整:开发更智能的算法,根据输入和任务类型动态调整不同LLMs的权重。
-
多模态集成:扩展框架以支持多模态LLMs的集成,如视觉-语言模型。
-
效率优化:改进PairRanker和GenFuser的计算效率,使其能够处理更大规模的数据和模型。
-
可解释性:增强框架的可解释性,使用户能够理解为什么某个输出被选中或如何被融合。
-
在线学习:实现在线学习机制,使LLM-Blender能够从用户反馈中不断学习和改进。
-
领域适应:开发针对特定领域(如医疗、法律、金融等)的专门版本的LLM-Blender。
结论
LLM-Blender为大语言模型的集成提供了一个强大而灵活的框架。通过创新的配对排序和生成式融合技术,它成功地利用了多个开源LLMs的优势,实现了持续优越的性能表现。随着更多研究者和开发者加入LLM-Blender社区,我们有理由期待这个框架在未来会得到进一步的改进和应用,为自然语言处理领域带来更多突破性的进展。
LLM-Blender不仅是一个技术创新,更代表了一种新的思路——通过智能集成来超越单个模型的局限。这种方法为解决AI系统中的偏见、鲁棒性和通用性等问题提供了新的可能性。随着AI技术不断发展,像LLM-Blender这样的集成框架将在推动整个领域向前发展中发挥越来越重要的作用。










