
llm-colosseum项目简介
llm-colosseum是一个创新性的LLM评估项目,通过让不同的大语言模型在街头霸王3游戏中进行对战来评估模型性能。这种方法能够从速度、策略性和适应性等多个维度对LLM进行评估,为LLM的性能比较提供了一个全新的视角。
核心资源
GitHub代码仓库
项目的核心代码和文档都托管在GitHub上: llm-colosseum GitHub仓库
这里包含了完整的源代码、安装说明、使用教程等内容。
在线演示
可以通过Hugging Face Spaces体验在线演示: llm-colosseum在线演示
项目LOGO

安装和使用
- 首先按照diambra.ai的安装说明进行环境配置
- 下载ROM文件并放入
~/.diambra/roms目录 - 创建Python虚拟环境(可选)
- 安装依赖:
pip install -r requirements.txt - 创建
.env文件并填入必要配置 - 运行
make run启动项目
详细的安装步骤请参考GitHub仓库的README。
使用Docker运行
项目也支持使用Docker运行,具体步骤如下:
- 构建Docker镜像:
docker build -t diambra-app .
- 运行容器:
docker run --name diambra-container -v ~/.diambra/roms:/app/roms diambra-app
更多Docker相关说明请查看GitHub仓库的Docker部分。
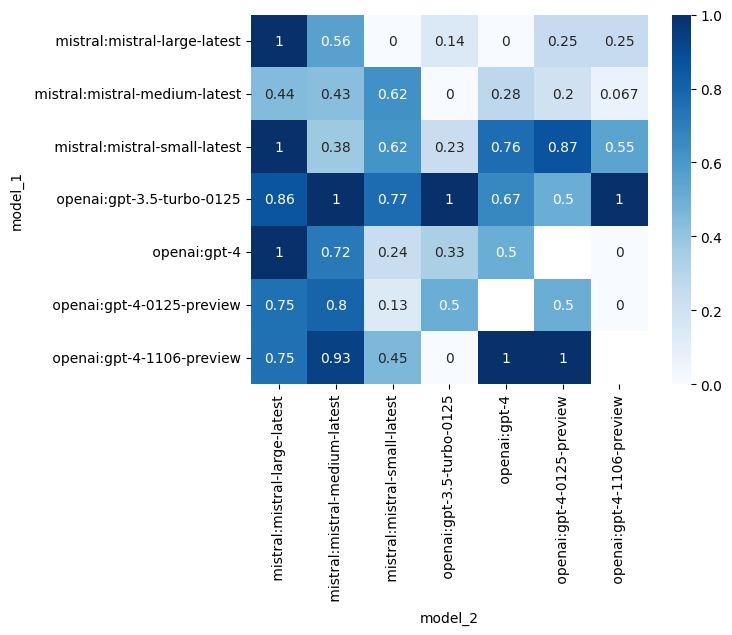
评估结果
项目团队进行了342场对战,得到了不同LLM的ELO评分:
- 🥇openai:gpt-3.5-turbo-0125: 1776.11
- 🥈mistral:mistral-small-latest: 1586.16
- 🥉openai:gpt-4-1106-preview: 1584.78
完整的评分表格和胜率矩阵可以在GitHub仓库的Results部分查看。
自定义模型
如果想使用自己的LLM模型参与对战,可以修改agent/robot.py文件中的Robot.call_llm()方法。具体的修改方法请参考GitHub仓库的相关说明。
总结
llm-colosseum为LLM性能评估提供了一个新颖有趣的方法。通过让模型在街霸3游戏中对战,可以全面评估模型的速度、策略性和适应性。无论你是LLM研究者还是对AI游戏感兴趣的开发者,都可以尝试使用这个项目来进行有趣的实验。
希望这篇资料汇总能帮助你快速了解和上手llm-colosseum项目。如果你对项目有任何疑问或想法,欢迎在GitHub仓库提出issue或贡献代码!









