LLMGA: 多模态大语言模型助力图像生成与编辑的新突破
 Ray
RayLLMGA:多模态大语言模型赋能的图像生成助手
在人工智能快速发展的今天,图像生成和编辑技术正在经历一场革命性的变革。由香港中文大学和商汤科技联合推出的LLMGA(Multimodal Large Language Model based Generation Assistant)项目,为这一领域带来了令人瞩目的创新。LLMGA巧妙地将大语言模型(LLM)的强大知识储备和推理能力与图像生成技术相结合,开创了一种全新的图像创作范式。
LLMGA的核心理念与技术创新
LLMGA的核心思想是利用多模态大语言模型(MLLM)作为图像生成和编辑的"大脑"。与传统方法不同,LLMGA不是简单地生成固定大小的嵌入向量来控制Stable Diffusion(SD)模型,而是提供详细的语言生成提示,从而实现对SD的精确控制。这种方法不仅增强了LLM对上下文的理解,还减少了生成提示中的噪声,使得生成的图像内容更加精细和准确,同时提高了整个网络的可解释性。
为了实现这一目标,研究团队精心策划了一个综合数据集,包括提示词优化、相似图像生成、图像修复与扩展,以及基于指令的编辑等任务。此外,他们提出了一个创新的两阶段训练方案:
- 第一阶段训练MLLM掌握图像生成和编辑的属性,使其能够生成详细的提示。
- 第二阶段优化SD模型,使其与MLLM的生成提示保持一致。
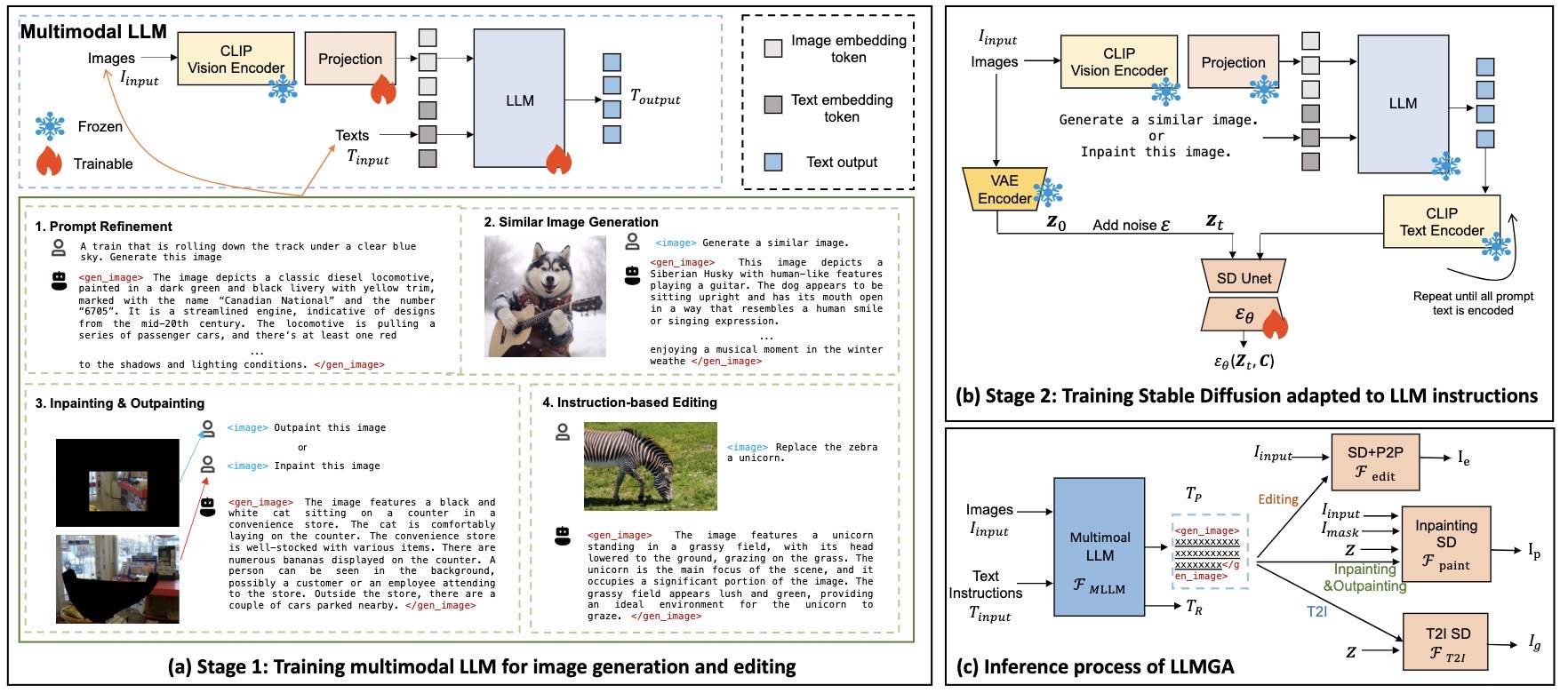
LLMGA的主要功能与应用场景
LLMGA作为一个统一的系统,通过与用户的对话交互,可以实现多种图像生成和编辑功能:
-
文本到图像(T2I)生成: 用户只需提供文本描述,LLMGA就能生成相应的高质量图像。
-
图像修复(Inpainting): 对于局部受损或需要修改的图像,LLMGA可以智能地填充或替换指定�区域。
-
图像扩展(Outpainting): LLMGA能够基于现有图像,向外扩展并生成合理的背景或场景。
-
基于指令的编辑: 用户可以通过自然语言指令来修改或优化现有图像。
这些功能使LLMGA成为一个强大的设计助手,适用于多个领域:
-
通用设计专家: LLMGA集成了大量图像设计数据,可为logo创作、游戏角色设计、海报设计、T恤设计、信息图表设计等多种任务提供深入见解。
-
插图生成: 能够根据用户输入的故事片段交互式地生成故事插图。
-
绘本生成: 只需一条用户指令,LLMGA就能生成一本文字与插图交织的完整绘本。
-
多语言支持: 通过多语言适配,LLMGA的T2I和编辑模型可以使用中文指令生成内容,极大地扩展了其应用范围。
-
灵活扩展: LLMGA可以与外部插件(如ControlNet)集成,进一步拓展其功能。

LLMGA的技术细节与实现
LLMGA的强大功能背后是一系列精心设计的技术细节:
-
模型架构:
- MLLM模型: 支持多种基础模型,包括Vicuna 7B、Mistral 7B、LLama3 8B、Qwen2系列(0.5B/1.5B/7B)、Phi3 3B和Gemma 2B等。
- SD模型: 支持SD1.5和SDXL,分别用于T2I生成和图像修复任务。
-
训练过程:
- 预训练阶段: 使用大规模图文数据进行初步训练。
- 第一阶段微调: 针对特定任务(如T2I、修复等)对MLLM进行微调。
- 第二阶段训练: 优化SD模型以配合MLLM的输出。
-
数据集:
- 使用LLMGA专有数据集和LLaVA预训练数据集。
- 包含COCO、GQA、OCR-VQA、TextVQA和VisualGenome等多个公开数据集。
-
推理优化:
- 支持多GPU推理、4位和8位量化推理,提高效率。
- 提供CLI和Gradio界面两种推理方式,满足不同使用需求。
-
创新点:
- 提出参考图像修复网络,解决修复和扩展过程中生成区域与保留区域之间的纹理、亮度和对比度差异问题。
- 实现了中英双语支持,大大提升了模型的实用性。
LLMGA的未来展望
LLMGA项目展现了多模态大语言模型在图像生成和编辑领域的巨大潜力。随着技术的不断进步,我们可以期待LLMGA在以下方面取得更多突破:
-
模型效率优化: 进一步提高推理速度和降低资源需求,使LLMGA能够在更广泛的设备上运行。
-
跨模态理解增强: 深化MLLM对文本和图像的联合理解,实现更精准的图像生成和编辑。
-
交互体验提升: 开发更直观、更智能的用户界面,让非专业用户也能轻松使用LLMGA创作高质量图像。
-
应用场景拓展: 探索LLMGA在虚拟现实、增强现实、视频生成等新兴领域的应用潜力。
-
伦理和安全考量: 加强对生成内容的审核机制,确保LLMGA的使用符合道德和法律标准。
结语
LLMGA项目代表了图像生成和编辑技术的一个重要里程碑。通过将大语言模型的智慧与计算机视觉技术相结合,LLMGA为创意工作者和普通用户alike带来了前所未有的图像创作体验。随着技术的不断发展和完善,我们有理由相信,LLMGA将在未来的数字创意领域发挥越来越重要的作用,推动人工智能辅助创作的新时�代到来。
如果您对LLMGA项目感兴趣,欢迎访问其GitHub仓库了解更多详情,或者尝试使用在线演示体验LLMGA的强大功能。让我们共同期待LLMGA为图像创作带来的无限可能!
编辑推荐精选


AEE
AI Excel全自动制表工具
AEE 在线 AI 全自动 Excel 编辑器,提供智能录入、自动公式、数据整理、图表生成等功能,高效处理 Excel 任务,提升办公效率。支持自动高亮数据、批量计算、不规则数据录入,适用于企业��、教育、金融等多场景。


UI-TARS-desktop
基于 UI-TARS 视觉语言模型的桌面应用,可通过自然语言控制计算机进行多模态操作。
UI-TARS-desktop 是一款功能强大的桌面应用,基于 UI-TARS(视觉语言模型)构建。它具备自然语言控制、截图与视觉识别、精确的鼠标键盘控制等功能,支持跨平台使用(Windows/MacOS),能提供实时反馈和状态显示,且数据完全本地处理,保障隐私安全。该应用集成了多种大语言模型和搜索方式,还可进行文件系统操作。适用于需要智能交互和自动化任务的场景,如信息检索、文件管理等。其提供了详细的文档,包括快速启动、部署、贡献指南和 SDK 使用说明等,方便开发者使用和扩展。


Wan2.1
开源且先进的大规模视频生成模型项目
Wan2.1 是一个开源且先进的大规模视频生成模型项目,支持文本到图像、文本到视频、图像到视频等多种生成任务。它具备丰富的配置选项,可调整分辨率、扩散步数等参数,还能对提示词进行增强。使用了多种先进技术和工具,在视频和图像生成领域具有广泛应用前景,适合研究人员和开发者使用。


爱图表
全流程 AI 驱动的数据可视化工具,助力用户轻松创作高颜值图表
爱图表(aitubiao.com)就是AI图表,是由镝数科技推出的一款创新型智能数据可视化平台,专注于为用户提供便捷的图表生成、数据分析和报告撰写服务。爱图表是中国首个在图表场景接入DeepSeek的产品。通过接入前沿的DeepSeek系列AI模型,爱图表结合强大的数据处理能力与智能化功能,致力于帮助职场人士高效处理和表达数据,提升工作效率和报告质量。


Qwen2.5-VL
一款强大的视觉语言模型,支持图像和视频输入
Qwen2.5-VL 是一款强大的视觉语言模型,支持图像和视频输入,可用于多种场景,如商品特点总结、图像文字识别等。项目提供了 OpenAI API 服务、Web UI 示例等部署方式,还包含了视觉处理工具,有助于开发者快速集成和使用,提升工作效率。


HunyuanVideo
HunyuanVideo 是一个可基于文本生成高质量图像和视频的项目。
HunyuanVideo 是一个专注于文本到图像及视频生成的项目。它具备强大的视频生成能力,支持多种分辨率和视频长度选择,能根据用户输入的文本生成逼真的图像和视频。使用先进的技术架构和算法,可灵活调整生成参数,满足不同场景的需求,是文本�生成图像视频领域的优质工具。


WebUI for Browser Use
一个基于 Gradio 构建的 WebUI,支持与浏览器智能体进行便捷交互。
WebUI for Browser Use 是一个强大的项目,它集成了多种大型语言模型,支持自定义浏览器使用,具备持久化浏览器会话等功能。用户可以通过简洁友好的界面轻松控制浏览器智能体完成各类任务,无论是数据提取、网页导航还是表单填写等操作都能高效实现,有利于提高工作效率和获取信息的便捷性。该项目适合开发者、研究人员以及需要自动化浏览器操作的人群使用,在 SEO 优化方面,其关键词涵盖浏览器使用、WebUI、大型语言模型集成等,有助于提高网页在搜索引擎中的曝光度。


xiaozhi-esp32
基于 ESP32 的小智 AI 开发项目,支持多种网络连接与协议,实现语音交互等功能。
xiaozhi-esp32 是一个极具创新性的基于 ESP32 的开发项目,专注于人工智能语音交互领域。项目涵盖了丰富的功能,如网络连接、OTA 升级、设备激活等,同时支持多种语言。无论是开发爱好者还是专业开发者,都能借助该项目快速搭建起高效的 AI 语音交互系统,为智能设备开发提供强大助力。


olmocr
一个用于 OCR 的项目,支持多种模型和服务器进行 PDF 到 Markdown 的转换,并提供测试和报告功能。
olmocr 是一个专注于光学字符识别(OCR)的 Python 项目,由 Allen Institute for Artificial Intelligence 开发。它支持多种模型和服务器,如 vllm、sglang、OpenAI 等,可将 PDF 文件的页面转换为 Markdown 格式。项目还提供了测试框架和 HTML 报告生成功能,方便用户对 OCR 结果进行评估和分析。适用于科研、文档处理等领域,有助于提高工作效率和准确性。


飞书多维表格
飞书多维表格 ×DeepSeek R1 满血版
飞书多维表格联合 DeepSeek R1 模型,提供 AI 自动化解决方案,支持批量写作、数据分析、跨模态处理等功能,适用于电商、短视频、影视创作等场景,提升企业生产力与创作效率。关键词:飞书多维表格、DeepSeek R1、AI 自动化、批量处理、企业协同工具。
推荐工具精选







AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号