低光照图像和视频增强技术综述:从传统方法到深度学习
 Ray
Ray引言
低光照图像和视频增强(Low-Light Image and Video Enhancement, LLIE)是计算机视觉领域的一个重要研究方向。在日常生活和专业应用中,我们经常会遇到在弱光环境下拍摄的图像和视频,这些低光照数据往往存在可见度低、细节丢失、噪声严重等问题,严重影响了后续的视觉分析和处理。因此,如何有效地增强低光照图像和视频的质量,提升其可见度和可用性,成为了一个备受关注的研究课题。
近年来,随着深度学习技术的快速发展,LLIE领域取得了长足的进步。本文旨在对LLIE领域进行全面的综述,梳理该领域的发展脉络,总结主要的技术方法,并展望未来的研究方向。
LLIE的发展历程
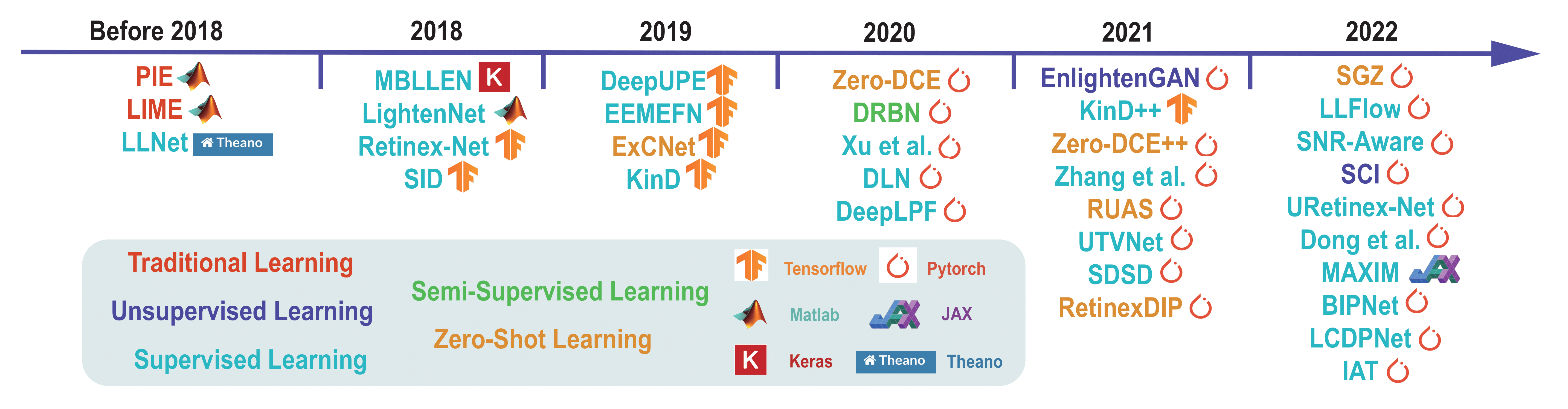
LLIE的研究可以追溯到20世纪70年代,最初主要基于图像处理的传统方法。随着计算机视觉和机器学习技术的发展,LLIE的方法逐渐向数据驱动和学习式方法转变。我们可以将LLIE的发展大致分为以下几个阶段:
-
传统图像处理阶段(1970s-2000s):主要包括直方图均衡化、Retinex理论等基于图像处理的方法。
-
机器学习阶段(2000s-2015):开始引入机器学习技术,如稀疏编码、字典学习等方法。
-
深度学习初期(2015-2018):CNN等深度学习模型被引入LLIE领域,但主要是端到端的直接映射。
-
深度学习快速发展期(2018至今):各种先进的深度学习模型被提出,如GAN、Transformer等,LLIE的性能得到显著提升。
LLIE方法分类
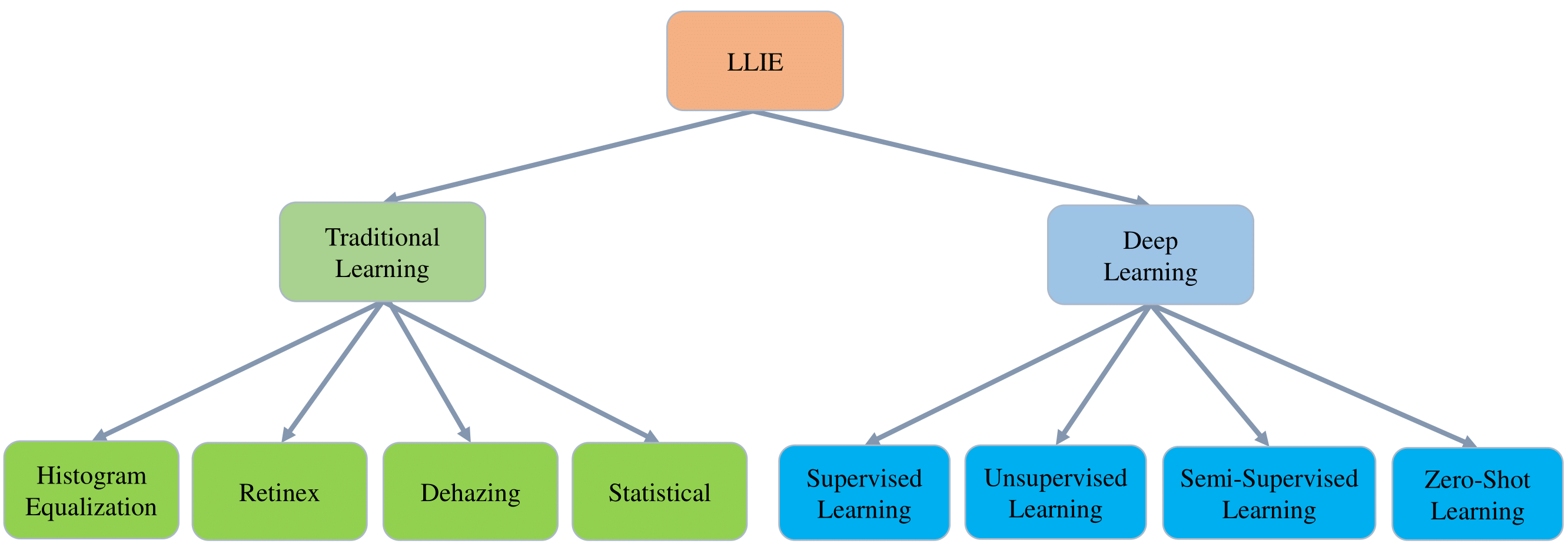
根据处理原理和模型结构,我们可以将LLIE方法大致分为以下几类:
- 基于Retinex理论的方法
- 基于直方图调整的方法
- 基于图像分解的方法
- 基于深度学习的直接映射方法
- 基于生成对抗网络(GAN)的方法
- 基于强化学习的方法
- 基于Transformer的方法
其中,深度学习方法又可以根据是否需要配对数据进行监督学习,分为有监督、半监督和无监督方法。
代表性算法
本节将介绍LLIE领域一些具有代表性的算法,按照发表时间顺序进行梳理。
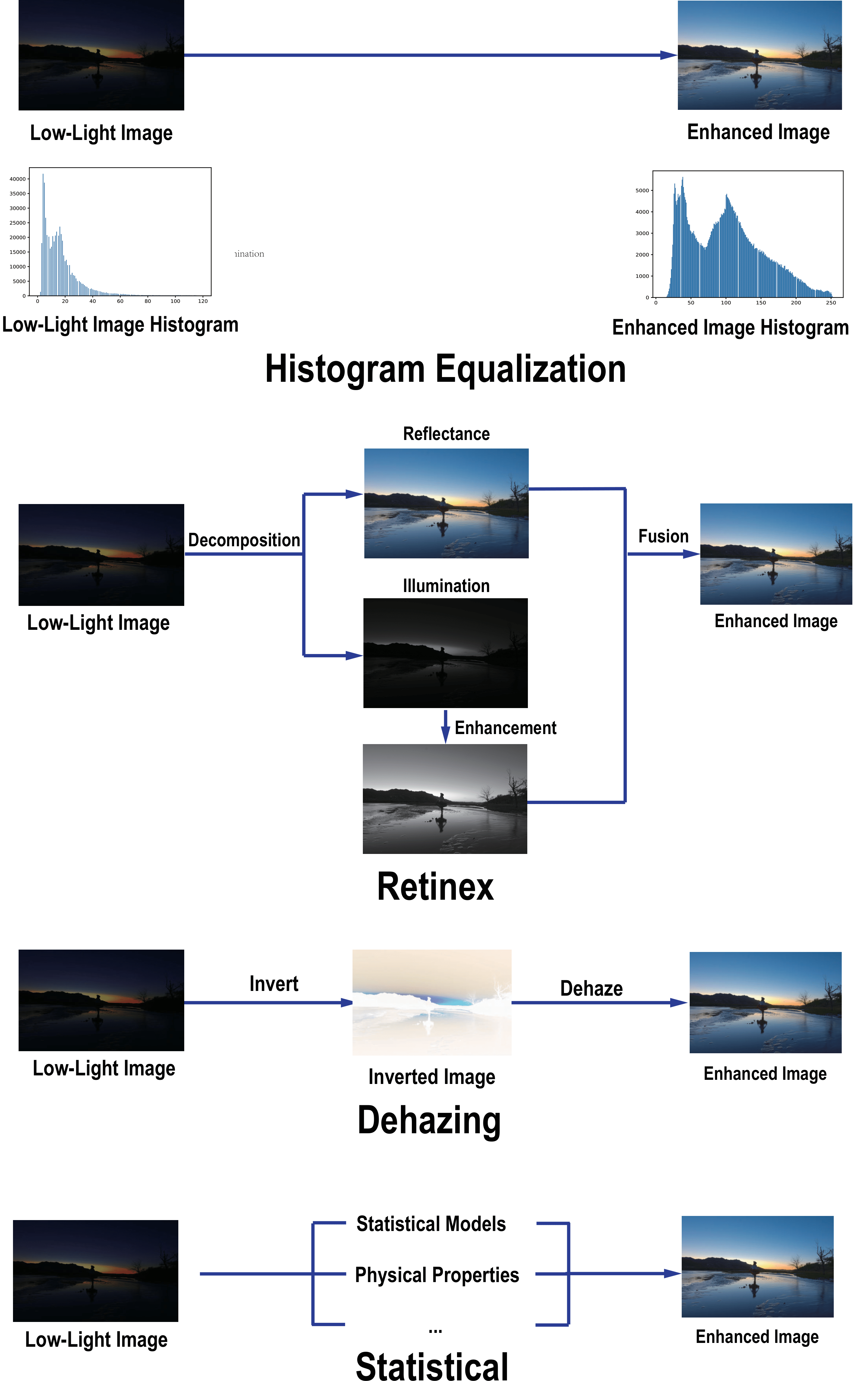
传统方法
-
LIME (TIP 2016): LIME提出了一种基于illumination map估计的低光照图像增强方法。该方法首先估计输入图像的illumination map,然后根据估计的illumination map对原始图像进行增强。LIME方法简单有效,在当时取得了不错的效果。
-
LightenNet (PRL 2018): LightenNet是一种基于卷积神经网络的弱光照图像增强方法。该网络采用了一种轻量级的结构,通过学习图像的明暗对比关系来实现增强效果。LightenNet在计算效率和增强效果之间取得了较好的平衡。
深度学习方法
-
Retinex-Net (BMVC 2018): Retinex-Net将传统的Retinex理论与深度学习相结合,提出了一种端到端的低光照图像增强网络。该网络包含了反射分量估计、照明分量估计和重建三个子网络,能够有效地处理不同程度的低光照图像。
-
EnlightenGAN (TIP 2021): EnlightenGAN是一种基于生成对抗网络(GAN)的无监督低光照图像增强方法。该方法不需要配对的低光照-正常光照图像对进行训练,而是通过对抗学习来生成增强后的图像。EnlightenGAN在真实场景的低光照图像增强任务中表现出色。
-
Zero-DCE (CVPR 2020): Zero-DCE提出了一种零参考的深度曲线估计方法,用于低光照图像增强。该方法通过学习一组像素级��的曲线来调整图像的亮度,不需要配对数据或参考图像,具有很强的实用性和泛化能力。
-
KinD++ (IJCV 2021): KinD++是一种基于图像分解的低光照图像增强方法。该方法将输入图像分解为反射分量和照明分量,分别对两个分量进行增强,然后重新组合得到最终的增强结果。KinD++在保持图像细节和颜色保真度方面表现优异。
-
LLFlow (AAAI 2022): LLFlow引入了标准化流(Normalizing Flow)的概念,提出了一种基于可逆网络的低光照图像增强方法。该方法能够学习低光照图像到正常光照图像的概率分布映射,在增强效果和计算效率方面都取得了不错的效果。
数据集
高质量的数据集对于LLIE研究至关重要。以下是一些常用的LLIE数据集:
-
LOL (Low-Light Dataset):包含500对低光照-正常光照图像对,是最常用的LLIE数据集之一。
-
SICE (Scene Illumination and Capture Expert Dataset):包含来自589个场景的多曝光序列图像,适用于多曝光融合和HDR重建任务。
-
ExDark:一个专门用于低光照目标检测的数据集,包含7363张图像,涵盖12个目标类别。
-
ACDC (Adverse Conditions Dataset with Correspondences):一个包含4006张图像的自动驾驶场景数据集,涵盖了不同天气和光照条件。
-
Night Wenzhou:本文作者提出的一个新的低光照视频数据集,包含了快速移动的航拍场景和具有不同光照和退化的街景。
研究人员还提出了一些合成数据集,如SICE_Grad和SICE_Mix,用于模拟复杂的混合过曝光/欠曝光场景。

评价指标
LLIE方法的评价通常包括定量指标和定性评估两个方面。
定量指标
-
全参考指标:
- PSNR (Peak Signal-to-Noise Ratio)
- SSIM (Structural Similarity Index)
- LPIPS (Learned Perceptual Image Patch Similarity)
-
无参考指标:
- NIQE (Natural Image Quality Evaluator)
- BRISQUE (Blind/Referenceless Image Spatial Quality Evaluator)
- SPAQ (Smartphone Photography Attribute and Quality)
定性评估
除了客观的定量指标,主观的定性评估也是非常重要的。这通常包括:
- 视觉比较:直接比较不同方法增强后的图像效果。
- 用户研究:让人类观察者对增强结果进行评分或排序。
- 下游任务性能:评估增强后的图像在目标检测、分割等下游任务中的性能。
挑战与未来方向
尽管LLIE领域取得了显著进展,但仍然面临一些挑战和有待探索的方向:
-
真实场景的鲁棒性:如何提高LLIE方法在复杂、多变的真实场景中的鲁棒性和泛化能力。
-
计算效率:在保证增强效果的同时,如何进一步提高算法的计算效率,使其适用于移动设备和实时应用。
-
视频增强:相比于单帧图像增强,低光照视频增强还需要考虑时间一致性等问题,有待进一步研究。
-
多模态融合:如何结合其他模态的信息(如红外、深度等)来提升低光照增强的效果。
-
可解释性:提高LLIE方法的可解释性和可控性,使其更加可信和易于调整。
-
特定任务优化:针对不同的下游任务(如目标检测、人脸识别等)优化LLIE方法,以获得更好的任务性能。
结论
低光照图像和视频增强是一个具有重要实际应用价值的研究�领域。本文对LLIE的发展历程、主要方法、数据集和评价指标等方面进行了全面的综述。随着深度学习技术的不断进步,LLIE领域已经取得了显著的成果。然而,仍然存在许多挑战和值得探索的方向。未来,结合多模态信息、提高方法的鲁棒性和可解释性、针对特定任务进行优化等方向可能会成为LLIE研究的重点。我们期待看到更多创新性的工作,推动LLIE技术在实际应用中发挥更大的作用。
参考资源
对于想要深入学习LLIE的研究者,以下是一些有用的资源:
-
LLIE_Survey GitHub仓库:包含了本文提到的许多方法的实现和数据集链接。
-
Awesome Low Light Image Enhancement:一个精心整理的LLIE相关资源列表。
-
Lighting the Darkness in the Deep Learning Era:另一个全面的LLIE相关资源集合。
编辑推荐精选


讯飞智文
一键生成PPT和Word,让学习生活更轻松
讯飞智文是一个利用 AI 技术的项目,能够帮助用户生成 PPT 以及各类文档。无论是商业领域的市场分析报告、年度目标制定,还是学生群体的职业生涯规划、实习避坑指南,亦或是活动策划、旅游攻略等内容,它都能提供支持,帮助用户精准表达,轻松呈现各种信息。


讯飞星火
深度推理能力全新升级,全面对标OpenAI o1
科大讯飞的星火大模型,支持语言理解、知识问答和文本创作等多功能,适用于多种文件和业务场景,提升办公和日常生活的效率。讯飞星火是一个提供丰富智能服务的平台,涵盖科技资讯、图像创作、写作辅助、编程解答、科研文献解读等功能,能为不同需求的用户提供便捷高效的帮助,助力用户轻松获取信息、解决问题,满足多样化使用场景。


Spark-TTS
一种基于大语言模型的高效单流解耦语音令牌文本到语音合成模型
Spark-TTS 是一个基于 PyTorch 的开源文本到语音合成项目,由多个知名机构联合参与。该项目提供了高效的 LLM(大语言模型)驱动的语音合成方案,支持语音克隆和语音创建功能,可通过命令行界面(CLI)和 Web UI 两种方式使用。用户可以根据需求调整语音的性别、音高、速度等参数,生成高质量的语音。该项目适用于多种场景,如有声读物制作、智能语音助手开发等。


Trae
字节跳动发布的AI编程神器IDE
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


咔片PPT
AI助力,做PPT更简单!
咔片是一款轻量化在线演示设计工具,借助 AI 技术,实现从内容生成到智能设计的一站式 PPT 制作服务。支持多种文档格式导入生成 PPT,提供海量模板、智能美化、素材替换等功能,适用于销售、教师、学生等各类人群,能高效制作出高品质 PPT,满足不同场景演示需求。


讯飞绘文
选题、配图、成文,一站式创作,让内容运营更高效
讯飞绘文,一个AI集成平台,支持写作、选题、配图、排版和发布。高效生成适用于各类媒体的定制内容,加速品牌传播,提升内容营销效果。


材料星
专业的AI公文写作平台,公文写作神器
AI 材料星,专业的 AI 公文写作辅助平台,为体制内工作人员提供高效的公文写作解决方案。拥有海量公文文库、9 大核心 AI 功能,支持 30 + 文稿类型生成,助力快速完成领导讲话、工作总结、述职报告等材料,提升办公效率,是体制打工人的得力写作神器。


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是�分布式存储领域的优质解决方案。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号