
Magika: 谷歌革命性的AI文件类型识别工具
在数字时代,准确识别文件类型对于确定如何处理文件至关重要。无论是网络浏览器、代码编辑器还是其他软件,都需要依赖文件类型检测来决定如何正确渲染或处理文件。然而,传统的文件类型识别方法往往存在局限性和不准确性。为了解决这一问题,谷歌推出了一款革命性的AI驱动文件类型识别工具——Magika。
Magika的核心技术与优势
Magika采用了最新的深度学习技术,使用自定义的高度优化Keras模型来实现准确的文件类型检测。这个模型仅重约1MB,即使在单个CPU上运行也能在毫秒级内完成精确的文件识别。
Magika的主要优势包括:
-
高精度: 在超过100万个文件和100多种内容类型(包括二进制和文本文件格式)的评估中,Magika实现了99%以上的精确度和召回率。
-
快速高效: 模型加载后(这是一次性开销),每个文件的推理时间约为5毫秒。
-
广泛支持: 支持100多种内容类型,涵盖了常见的文件格式。
-
批处理能力: 可以同时处理多个文件,甚至可以一次处理数千个文件。
-
灵活性: 支持三种不同的预测模式,可以根据需求调整错误容忍度。
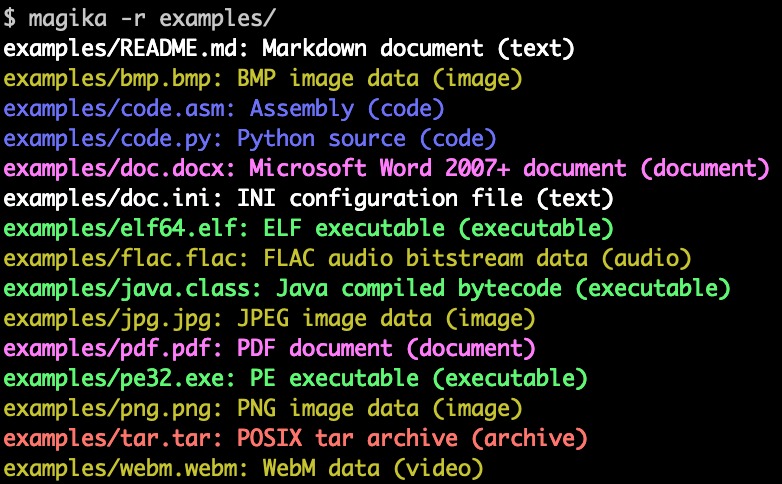
Magika在谷歌的应用
Magika已经在谷歌内部大规模应用,用于提高用户安全性。它通过将Gmail、Drive和Safe Browsing文件路由到适当的安全和内容策略扫描器,显著提升了文件类型识别的准确性。根据谷歌的数据,Magika将文件类型识别准确率提高了50%,使得可以扫描的文件数量增加了11%,未识别文件的比例降至3%。
Magika的开源与社区贡献
谷歌已经将Magika开源,并在GitHub上发布了代码和模型。开发者可以通过PyPI包管理器轻松安装Magika,无需GPU即可使用。此外,谷歌还提供了实验性的npm包,方便在Web应用中使用Magika。
开源Magika的目的是帮助其他软件提高文件识别准确性,并为研究人员提供一种可靠的大规模文件类型识别方法。谷歌鼓励社区参与Magika的改进,包括提高检测准确性、支持更多内容类型、为更多语言提供绑定等。
Magika的使用方法
Magika提供了多种使用方式:
- Python命令行工具
- Python API
- 实验性的TFJS版本(用于Web演示)
以下是一个使用Python API的简单示例:
from magika import Magika
m = Magika()
res = m.identify_bytes(b"# Example\nThis is an example of markdown!")
print(res.output.ct_label)
# 输出: markdown
Magika的未来发展
虽然Magika已经显著改进了文件类型识别的现状,但谷歌表示仍有提升空间。未来的工作方向包括:
- 进一步提高检测准确性
- 支持更多内容类型
- 为更多编程语言提供绑定
- 探索多格式文件(polyglot)的检测
谷歌欢迎社区成员报告遇到的问题、误检情况、功能请求以及对额外内容类型支持的需求。
结语
Magika代表了文件类型识别技术的一个重大突破。通过利用深度学习的力量,它不仅提高了识别的准确性和效率,还为开发者和研究人员提供了一个强大的工具。随着Magika的开源和社区的参与,我们可以期待看到更多创新应用和改进,进一步推动文件处理和安全领域的发展。
Magika的出现无疑将为数字世界带来更安全、更高效的文件处理体验。无论是个人用户、开发者还是企业,都有望从这一创新技术中受益。让我们共同期待Magika在未来带来的更多可能性和突破。










