
Mantis简介
在人工智能和计算机视觉领域,大型多模态模型(LMMs)的发展日新月异。然而,现有的模型主要专注于单图像视觉语言任务,在处理多图像任务时仍有很大提升空间。为了解决这一问题,研究人员开发了Mantis - 一种革命性的多图像指令调优模型。
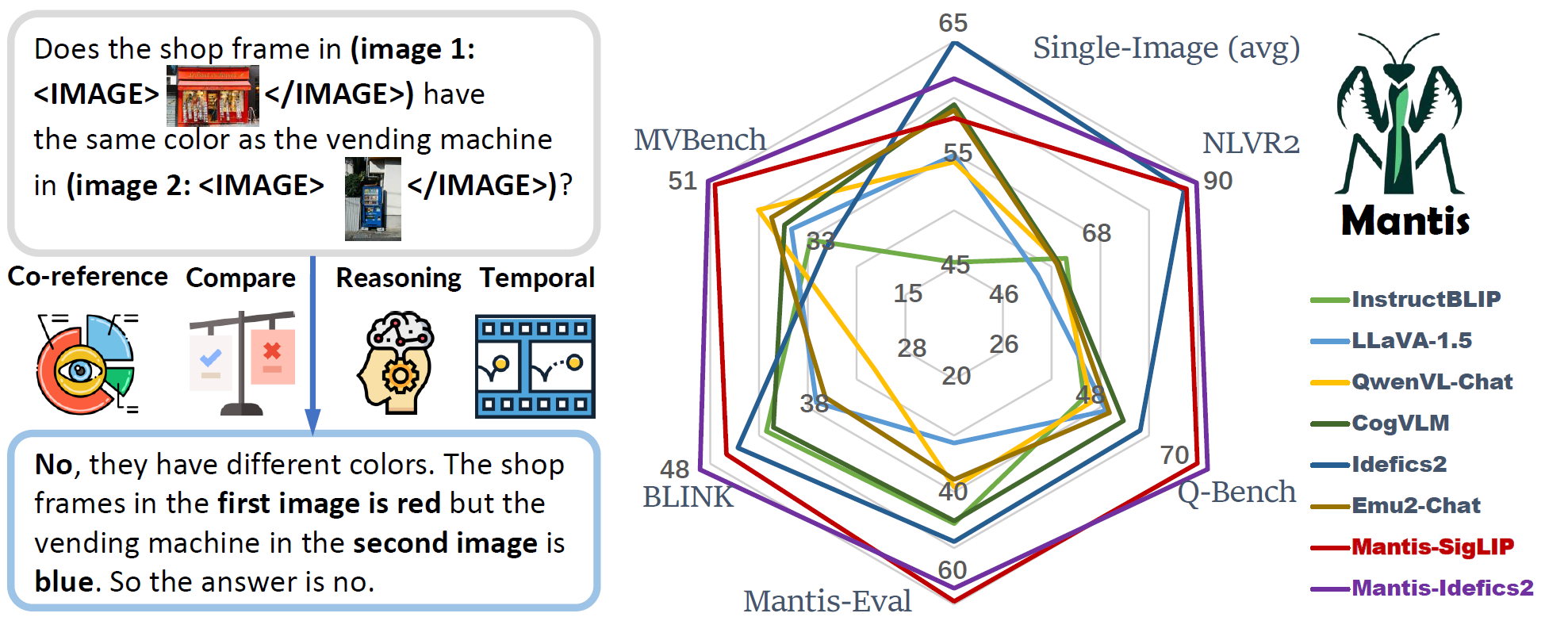
Mantis是基于LLaMA-3的大型语言模型,能够处理交错的文本和图像输入。它在Mantis-Instruct数据集上进行训练,仅使用了学术级别的计算资源(16块A100-40G GPU,训练时间36小时)。尽管如此,Mantis在多项多图像基准测试中都取得了最先进的性能,同时在单图像任务上也保持了与CogVLM和Emu2相当的强大表现。
Mantis的核心优势
与现有的多图像LMMs(如OpenFlamingo、Emu、Idefics等)相比,Mantis具有以下显著优势:
-
高效训练: 现有模型主要通过在数亿条嘈杂的网络图文数据上进行预训练来获得多图像处理能力,这种方法既不高效也不够有效。相比之下,Mantis采用了更加高效的训练方法。
-
强大性能: Mantis在5个多图像基准测试(NLVR2、Q-Bench、BLINK、MVBench、Mantis-Eval)中都达到了最先进的水平。
-
通用能力: 除了在多图像任务上表现出色,Mantis在单图像任务上也保持了强大的性能,与CogVLM和Emu2等模型相当。
-
资源效率: Mantis仅使用学术级别的计算资源就能达到如此优异的性能,这为研究人员和小型团队提供了更多可能性。
Mantis的技术细节
模型架构
Mantis基于LLaMA-3架构,并进行了多模态扩展以支持交错的文本和图像输入。它采用了先进的视觉编码器(如CLIP或SigLIP)来处理图像信息,并通过精心设计的多模态投影器将视觉特征与语言模型融合。
训练过程
Mantis的训练分为两个主要阶段:
-
预训练阶段: 在这一阶段,主要训练多模态投影器,使其能够有效地将视觉信息与语言模型融合。
-
指令微调阶段: 在Mantis-Instruct数据集上进行微调,该数据集包含721K条文本-图像交错的多图像指令数据。
这种两阶段训练方法使Mantis能够在有限的计算资源下快速获得强大的多图像处理能力。
数据集
Mantis的成功离不开高质量的训练数据。研究团队开发了两个关键数据集:
- Mantis-Instruct: 包含721K条文本-图像交错的数据,用于多图像指令调优。
- Mantis-Eval: 包含217个高质量样本,用于评估LMM的多图像处理技能。

Mantis的应用场景
Mantis的多图像处理能力为许多实际应用开辟了新的可能性:
-
智能照片分析: 能够同时分析多张照片,找出它们之间的关系和差异。
-
视觉推理: 在需要比较多个图像进行推理的任务中表现出色,如NLVR2基准测试。
-
视觉问答: 可以回答涉及多个图像的复杂问题,为用户提供更全面的信息。
-
图像编辑和创作: 通过理解多个参考图像,为创意工作提供更智能的辅助。
-
医疗影像分析: 可以同时分析多张医疗影像,为诊断提供更全面的支持。
-
安防监控: 能够同时处理多个摄像头的画面,提高异常检测的准确性。
Mantis的未来发展
尽管Mantis已经展现出了令人瞩目的性能,但研究团队仍在不断推进其发展:
-
模型优化: 计划通过改进模型架构和训练策略,进一步提升Mantis的性能和效率。
-
扩展应用: 探索Mantis在更多领域的应用可能,如视频理解、跨模态检索等。
-
开源合作: Mantis项目在GitHub上开源,欢迎社区贡献者参与改进和扩展。
-
伦理考虑: 研究团队也在关注多图像AI模型可能带来的伦理问题,致力于开发负责任的AI技术。
结语
Mantis的出现标志着多图像理解领域的一个重要里程碑。它不仅在性能上达到了新的高度,还以其高效的训练方法和广泛的应用前景,为人工智能和计算机视觉领域带来了新的可能性。随着Mantis的不断发展和完善,我们可以期待看到更多基于多图像理解的创新应用,这将为人类理解和处理视觉信息带来革命性的变化。
作为一个开源项目,Mantis也为研究人员和开发者提供了宝贵的资源。通过访问Mantis的GitHub仓库,你可以深入了解其实现细节,甚至为其发展做出自己的贡献。让我们共同期待Mantis在多图像人工智能领域继续引领创新,为科技发展贡献力量。









