
Marlin简介
Marlin是一个Mixed Auto-Regressive LINear内核,是目前最快的鱼类之一的名字。它是一个高度优化的FP16xINT4矩阵乘法内核,专为LLM推理而设计,可在中等批量大小(16-32个token)下实现接近理想的4倍加速,这与之前同等加速比工作只能在1-2个token的批量大小下实现形成鲜明对比。这使Marlin非常适合大规模服务、推测解码或CoT-Majority等高级多推理方案。

主要技术特点
Marlin采用了多项创新技术来充分利用GPU资源:
- 优化计算组织,使激活总是从L2缓存获取,并在寄存器中多次重用
- 异步执行全局权重加载
- 使用双缓冲进行共享内存加载
- 精心排序去量化和张量核心指令
- 离线重排量化权重和组标度
- 多个warp计算同一输出tile的部分结果
- 使用最大向量长度进行加载
- 实现"条带"分区方案
- 全局规约直接在L2缓存的输出缓冲区中进行
性能基准
与其他流行的4位推理内核相比,Marlin在各种批量大小下都能实现接近理想的加速比:
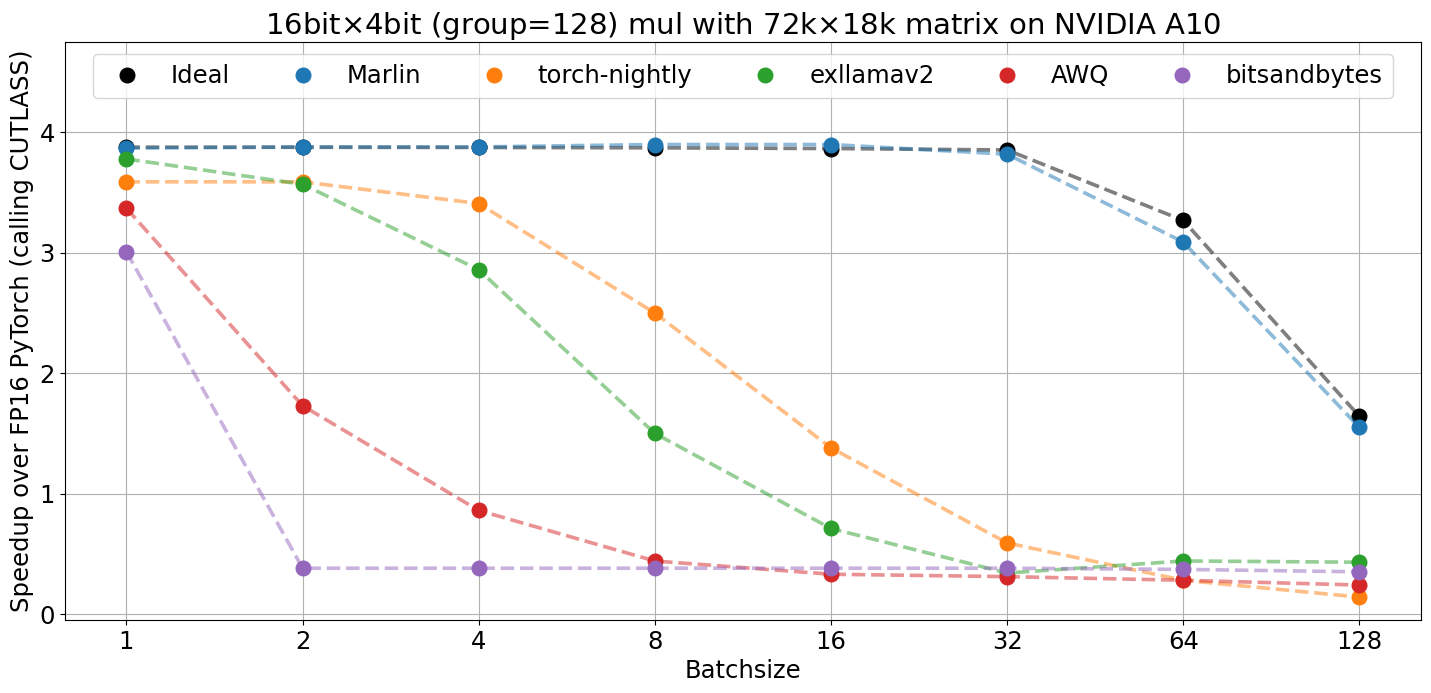
在真实矩阵和各种GPU上,Marlin也表现出色:
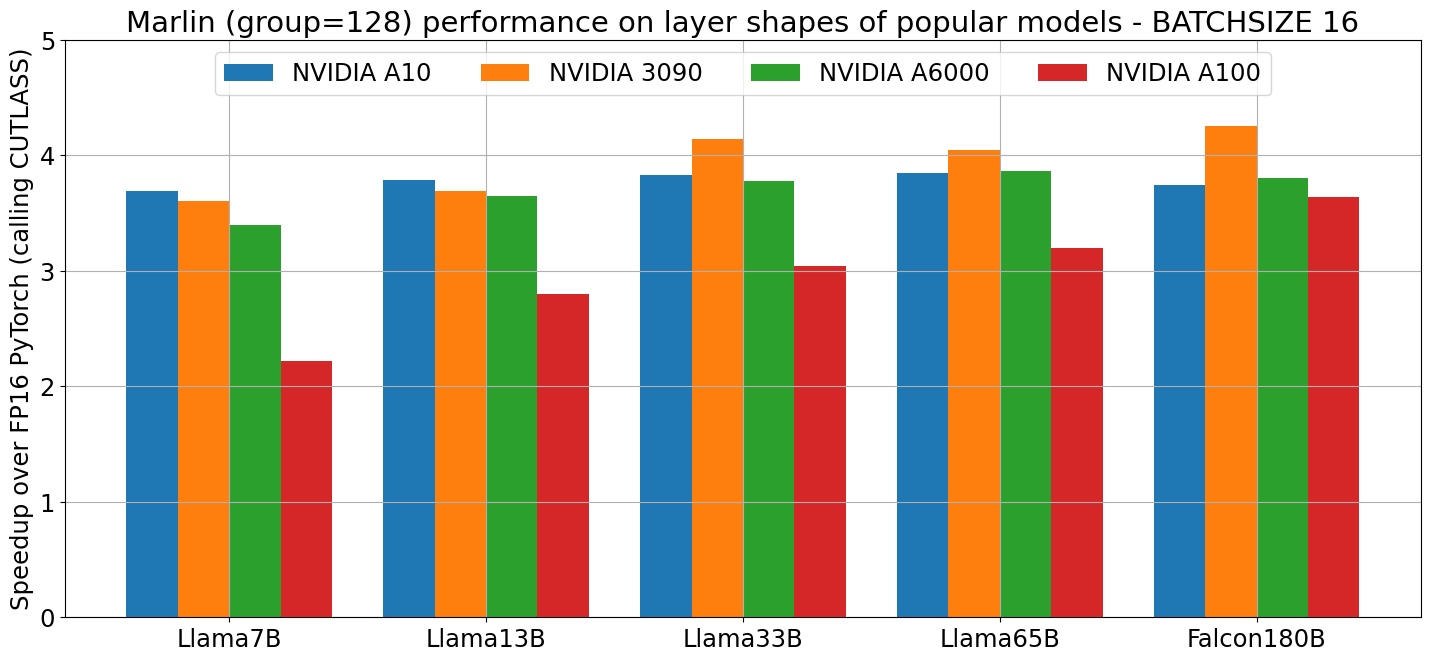
使用方法
-
安装要求:
- CUDA >= 11.8
- NVIDIA GPU with compute capability >= 8.0
- torch>=2.0.0
- numpy
-
安装Marlin:
pip install .
-
使用Marlin内核:
- 通过
marlin.Layer转换"假量化"的torch.Linear层 - 或直接调用
marlin.mul(..)
- 通过
-
运行测试和基准:
python test.py
python bench.py
其他资源
Marlin为LLM推理提供了强大的加速能力,欢迎探索使用!如果您觉得这个项目有用,请考虑在您的工作中引用它。










