
Matryoshka Diffusion Models:高效训练高质量文本到图像模型的新方法
近年来,扩散模型(Diffusion Models)已经成为生成高质量图像和视频的主流方法。然而,训练高维度的扩散模型仍然面临着巨大的计算和优化挑战。为了解决这一问题,Apple 研究团队提出了一种名为 Matryoshka Diffusion Models (MDM) 的新方法,可以在有限的计算资源和数据集下,高效训练出高质量的大尺寸图像生成模型。
MDM 的核心思想
MDM 的核心思想是利用嵌套结构(Matryoshka结构)来组织模型,使得单个像素空间模型就可以生成多种分辨率的图像。具体来说,MDM 采用了以下关键技术:
-
嵌套 U-Net 架构:使用嵌套的 U-Net 网络,可以在单个模型中同时处理多种分辨率的图像特征。
-
多尺度训练:在训练过程中,同时优化多个分辨率的生成任务,提高模型的泛化能力。
-
自适应采样:根据输入提示和目标分辨率,自适应地选择合适的采样策略。
通过这种设计,MDM 可以用单个模型实现从64x64到1024x1024等多种分辨率图像的生成,大大提高了模型的效率和灵活性。
MDM 的主要优势
与传统的扩散模型相比,MDM 具有以下显著优势:
-
高效训练:只需训练一个模型就可以生成多种分辨率的图像,大大降低了计算资源需求。
-
强大的零样本泛化能力:在仅使用1200万张图像的CC12M数据集上训练,MDM就展现出了出色的大尺寸图像生成能力。
-
灵活的推理:可以根据需求生成不同分辨率的图像,满足各种应用场景。
-
高质量输出:生成的图像质量与专门针对单一分辨率训练的模型相当。
使用 MDM 生成图像
Apple 研究团队已经开源了 MDM 的实现代码和预训练模型。用户可以通过以下步骤快速上手使用 MDM 生成图像:
- 安装 ml_mdm 库:
pip install ml_mdm
- 下载预训练模型:
curl https://docs-assets.developer.apple.com/ml-research/models/mdm/flickr64/vis_model.pth --output vis_model_64x64.pth
curl https://docs-assets.developer.apple.com/ml-research/models/mdm/flickr256/vis_model.pth --output vis_model_256x256.pth
curl https://docs-assets.developer.apple.com/ml-research/models/mdm/flickr1024/vis_model.pth --output vis_model_1024x1024.pth
- 运行Web演示:
torchrun --standalone --nproc_per_node=1 ml_mdm/clis/generate_sample.py --port YOUR_PORT
通过Web界面,用户可以输入文本描述,选择目标分辨率,然后生成相应的图像。
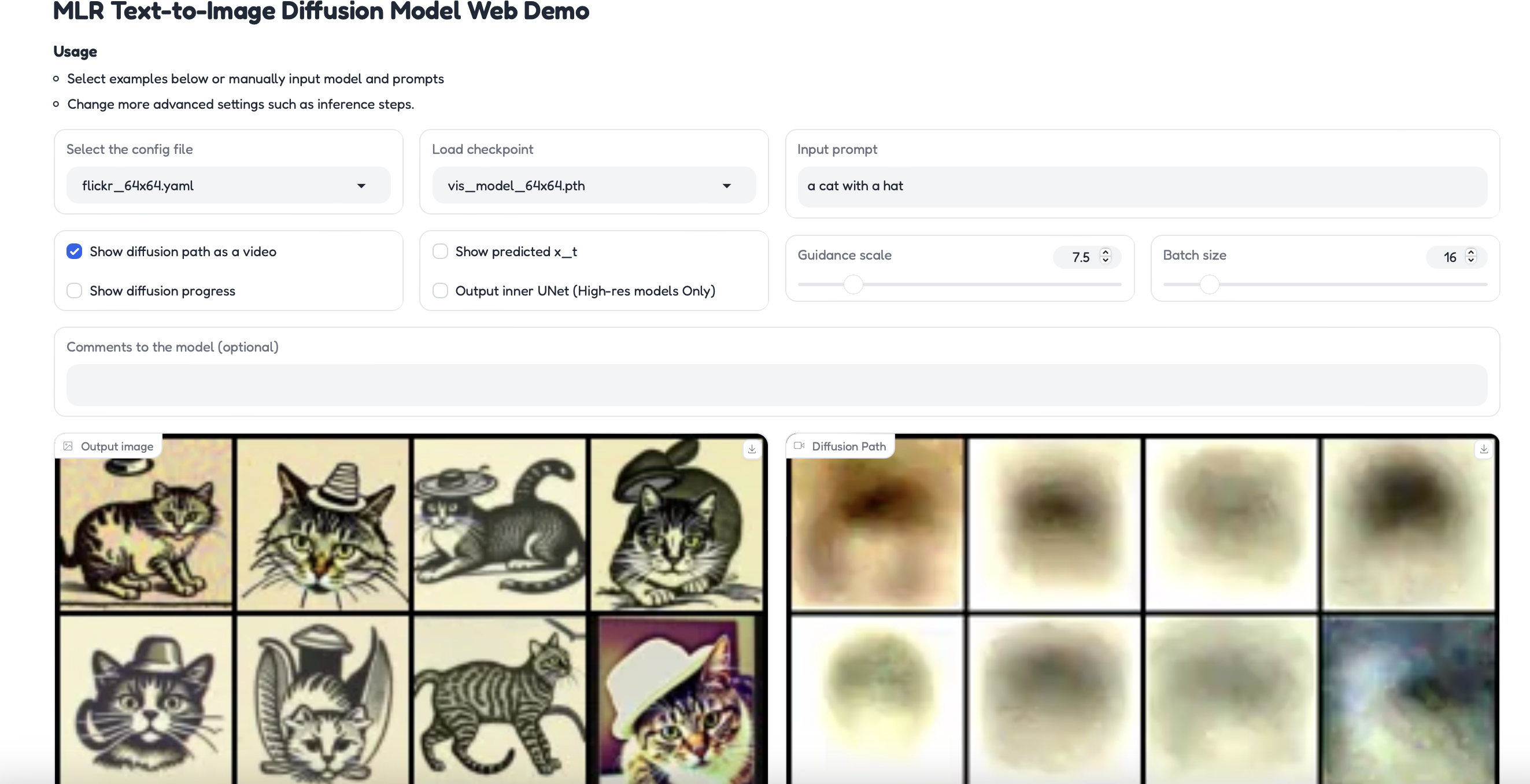
训练自己的 MDM 模型
除了使用预训练模型,研究人员还可以使用开源代码训练自己的 MDM 模型。主要步骤如下:
-
准备数据集:可以使用CC12M等公开数据集,或者自己收集的图文对数据。
-
配置训练参数:在 configs 目录下修改相应的配置文件。
-
启动训练:
torchrun --standalone --nproc_per_node=8 ml_mdm/clis/train_parallel.py \
--file-list=training_0.tsv \
--multinode=0 --output-dir=/mnt/data/outputs \
--config_path configs/models/cc12m_64x64.yaml \
--num-training-steps=100000 --warmup-steps 10000
- 采样生成图像:
torchrun --standalone --nproc_per_node=1 ml_mdm/clis/generate_batch.py \
--config_path configs/models/cc12m_64x64.yaml \
--min-examples 3 --test-file-list validation.tsv \
--sample-image-size 64 --model-file /mnt/data/outputs/vis_model_000100.pth
总结
Matryoshka Diffusion Models 为高质量文本到图像生成模型的高效训练提供了一种新的解决方案。它不仅可以在有限的计算资源和数据集下实现大尺寸图像的生成,还具有灵活的多分辨率输出能力。随着 MDM 相关代码和模型的开源,我们期待看到更多基于此技术的创新应用出现。
无论是图像生成、内容创作,还是计算机视觉研究,MDM 都为这些领域带来了新的可能性。研究人员和开发者可以基于开源代码进行进一步的探索和改进,推动文本到图像生成技术的不断发展。









