Mava: 基于JAX的分布式多智能体强化学习框架
 Ray
RayMava: 开启多智能体强化学习的新纪元 🚀
在人工智能研究的前沿,多智能体强化学习(Multi-Agent Reinforcement Learning, MARL)一直是一个充满挑战和机遇的领域。随着技术的不断进步,研究者们迫切需要一个高效、灵活且易用的MARL研究框架。Mava应运而生,它是由InstaDeep公司研究团队开发的一个基于JAX的分布式多智能体强化学习框架,旨在为MARL研究提供强大的支持。
Mava的核心特性
Mava的设计理念源于简洁性和高效性。它继承了PureJaxRL和CleanRL的代码哲学,提供了易于理解和扩展的单文件实现。同时,Mava充分利用了JAX的优势,如pmap和vmap,使得研究人员可以轻松实现分布式训练和快速迭代。
-
算法实现: Mava提供了多种MARL算法的实现,包括多智能体PPO(MAPPO)和独立PPO(IPPO)。这些算法遵循集中式训练去中心化执行(CTDE)和去中心化训练去中心化执行(DTDE)两种MARL范式。
-
环境支持: Mava集成了多个popular的MARL环境,如Robotic Warehouse、Level-Based Foraging和SMAX。这些环境都经过JAX化处理,以确保与Mava框架的无缝对接。
-
教育资源: 为了帮助新手快速入门,Mava提供了详细的Quickstart教程notebook,展示了如何使用Mava并突出了基于JAX的MARL的优势。
-
评估工具: Mava原生支持将实验结果记录为标准化的JSON文件,便于使用MARL-eval库进行下游实验绘图和数据聚合分析。

性能与速度的完美结合
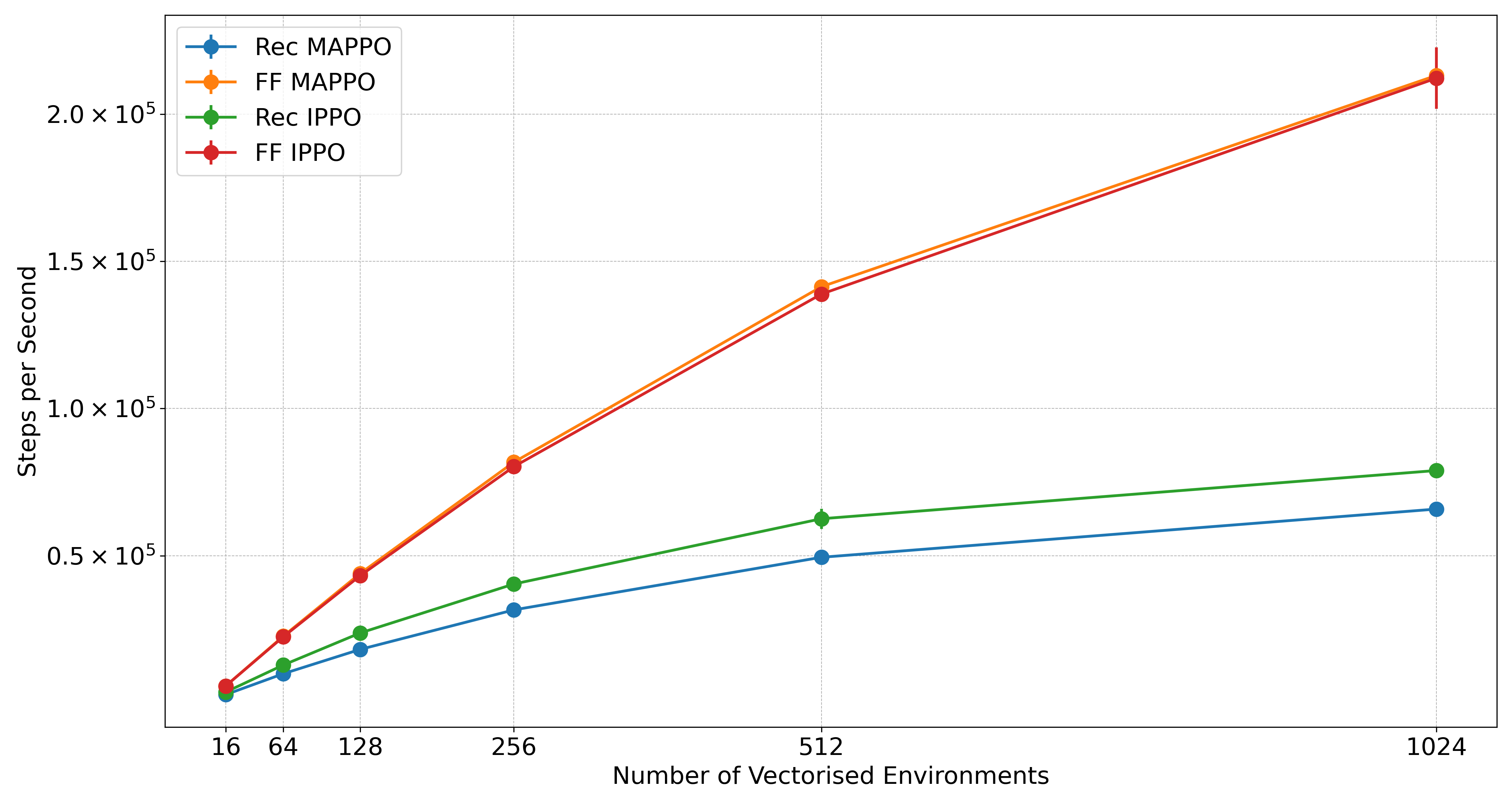
Mava的一大亮点是其卓越的性能和训练速度。通过与其他基准算法的对比实验,Mava展现出了令人印象深刻的结果:
-
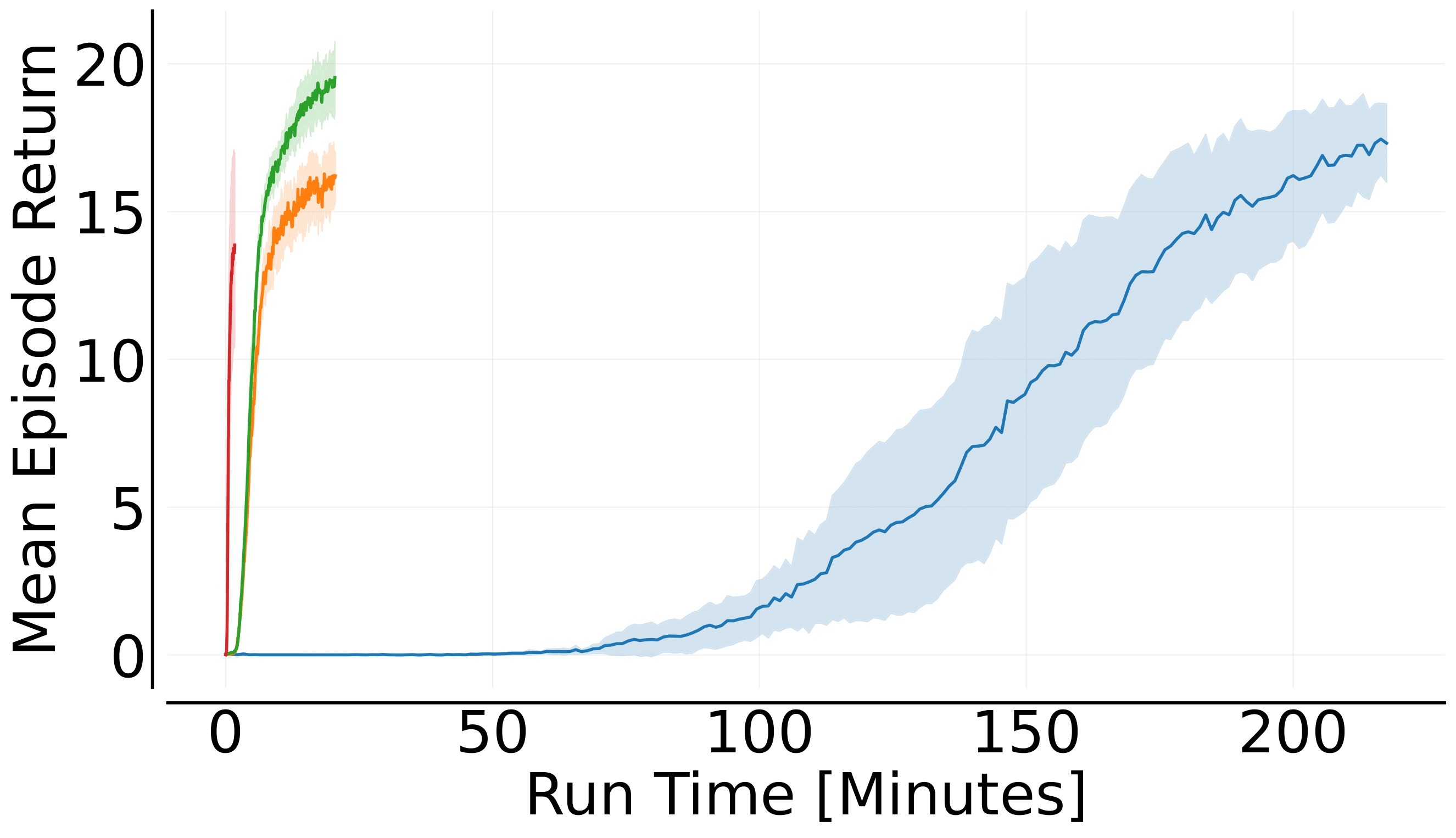
SMAX环境: 在SMAX�的多个任务中,Mava的循环IPPO和MAPPO系统表现出色,与JaxMARL中的基线算法相比具有竞争力。
-
Robotic Warehouse环境: Mava在简单的RWARE任务上的训练速度远超EPyMARL,展示了端到端JAX化MARL系统的优势。
-
Level-Based Foraging环境: Mava的循环MAPPO系统在LBF任务上同样表现优异,不仅性能卓越,而且训练速度显著提升。
使用Mava进行研究
对于有志于MARL研究的学者和工程师,Mava提供了一个理想的起点:
- 安装: Mava目前不作为库安装,而是作为研究工具使用。用户可以通过克隆GitHub仓库并进行pip安装来使用Mava。
git clone https://github.com/instadeepai/mava.git cd mava pip install -e .
- 快速开始: 运行一个Mava系统非常简单,只需执行对应的系统文件即可:
python mava/systems/ff_ippo.py
-
配置管理: Mava使用Hydra进行配置管理,允许用户通过YAML文件或命令行参数灵活调整系统设置。
-
高级用法: Mava支持将经验数据记录到Flashbax
Vault中,为离线MARL系统的研究提供了便利。
Mava的未来发展
Mava团队有着雄心勃勃的发展计划,包括:
- 支持更多环境
- 增强循环系统的鲁棒性
- 支持非JAX环境
- 实现离线策略算法
- 支持连续动作空间的环境和算法
结语
Mava作为一个强大的MARL研究框架,为研究人员提供�了一个高效、灵活且易用的工具。它不仅加速了MARL算法的实现和测试过程,还为推动整个领域的发展做出了重要贡献。无论您是MARL领域的新手还是经验丰富的研究者,Mava都将成为您不可或缺的得力助手。
让我们携手前进,共同探索多智能体强化学习的无限可能! 🌟
参考资源
如果您在研究中使用了Mava,请引用以下技术报告:
@article{dekock2023mava,
title={Mava: a research library for distributed multi-agent reinforcement learning in JAX},
author={Ruan de Kock and Omayma Mahjoub and Sasha Abramowitz and Wiem Khlifi and Callum Rhys Tilbury
and Claude Formanek and Andries P. Smit and Arnu Pretorius},
year={2023},
journal={arXiv preprint arXiv:2107.01460},
url={https://arxiv.org/pdf/2107.01460.pdf},
}
让我们一起,用Mava开启多智能体强化学习研究的新篇章! 🚀🌠
编辑推荐精选


讯飞智文
一键生成PPT和Word,让学习生活更轻松
讯飞智文是一个利用 AI 技术的项目,能够帮助用户生成 PPT 以及各类文档。无论是商业领域的市场分析报告、年度目标制定,还是学生群体的职业生涯规划、实习避坑指南,亦或是活动策划、旅游攻略等内容,它都能提供支持,帮助用户精准表达,轻松呈现各种信息。


讯飞星火
深度推理能力全新升级,全面对标OpenAI o1
科大讯飞的星火大模型,支持语言理解、知识问答和文本创作等多功能,适用于多种文件和业务场景,提升办公和日常生活的效率。讯飞星火是一个提供丰富智能服务的平台,涵盖科技资讯、图像创作、写作辅助、编程解答、科研文献解读等功能,能为不同需求的用户提供便捷高效的帮助,助力用户轻松获取信息、解决问题,满足多样化使用场景。


Spark-TTS
一种基于大语言模型的高效单流解耦语音令牌文本到语音合成模型
Spark-TTS 是一个基于 PyTorch 的开源文本到语音合成项目,由多个知名机构联合参与。该项目提供了高效的 LLM(大语言模型)驱动的语音合成方案,支持语音克隆和语音创建功能,可通过命令行界面(CLI)和 Web UI 两种方式使用。用户可以根据需求调整语音的性别、音高、速度等参数,生成高质量的语音。该项目适用于多种场景,如有声读物制作、智能语音助手开发等。


Trae
字节跳动发布的AI编程神器IDE
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


咔片PPT
AI助力,做PPT更简单!
咔片是一款轻量化在线演示设计工具,借助 AI 技术,实现从内容生成到智能设计的一站式 PPT 制作服务。支持多种文档格式导入生成 PPT,提供海量模板、智能美化、素材替换等功能,适用于销售、教师、学生等各类人群,能高效制作出高品质 PPT,满足不同场景演示需求。


讯飞绘文
选题、配图、成文,一站式创作,让内容运营更高效
讯飞绘文,一个AI集成平台,支持写作、选题、配图、排版和发布。高效生成适用于各类媒体的定制内容,加速品牌传播,提升内容营销效果。


材料星
专业的AI公文写作平台,公文写作神器
AI 材料星,专业的 AI 公文写作辅助平台,为体制内工作人员提供高效的公文写作解决方案。拥有海量公文文库、9 大核心 AI 功能,支持 30 + 文稿类型生成,助力快速完成领导讲话、工作总结、述职报告等材料,提升办公效率,是体制打工人的得力写作神器。


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效�的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号