
MEALPY简介
MEALPY (MEta-heuristic ALgorithms in PYthon) 是一个开源的Python库,包含了大量最先进的元启发式算法。这些算法属于基于种群的算法(PMA),是近似优化领域中最流行的算法。
MEALPY的主要特点包括:
- 免费开源:采用GNU通用公共许可证(GPL) V3许可
- 算法丰富:共有215种算法,包括190种官方算法(原始、混合、变体)和25种开发算法
- 文档完善:提供详细的在线文档
- 兼容性强:支持Python 3.7及以上版本
- 依赖简单:仅依赖numpy、scipy、pandas和matplotlib
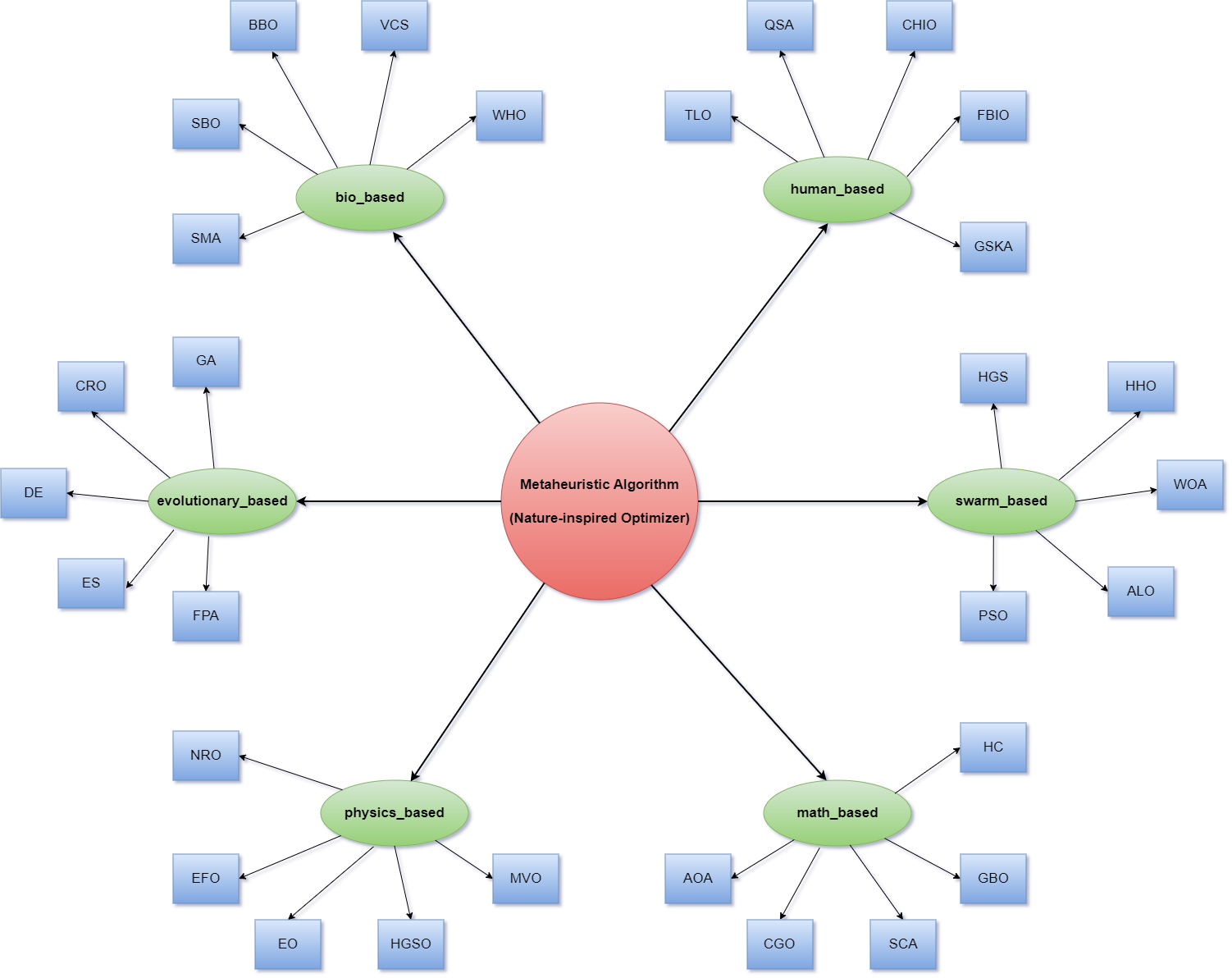
MEALPY的目标
MEALPY的主要目标是:
- 免费分享元启发式领域的知识
- 帮助各领域的研究人员快速访问优化算法
- 实现经典和最新的元启发式算法,涵盖元启发式的整个历史
MEALPY的应用
使用MEALPY,您可以:
- 分析元启发式算法的参数
- 对算法进行定性和定量分析
- 分析算法的收敛速度
- 测试和分析算法的可扩展性和稳健性
- 以多种格式(csv、json、pickle、png、pdf、jpeg)保存结果
- 导出和导入模型
- 解决各种优化问题
安装和使用
可以通过pip安装MEALPY的稳定版本:
pip install mealpy==3.0.1
安装完成后,可以像导入其他Python模块一样导入MEALPY:
import mealpy
print(mealpy.__version__)
print(mealpy.get_all_optimizers())
示例
简单的基准函数优化
from mealpy import FloatVar, SMA
import numpy as np
def objective_function(solution):
return np.sum(solution**2)
problem = {
"obj_func": objective_function,
"bounds": FloatVar(lb=(-100.,)*30, ub=(100.,)*30),
"minmax": "min",
"log_to": None,
}
model = SMA.OriginalSMA(epoch=100, pop_size=50, pr=0.03)
g_best = model.solve(problem)
print(f"Best solution: {g_best.solution}, Best fitness: {g_best.target.fitness}")
大规模优化
from mealpy import FloatVar, SHADE
import numpy as np
def objective_function(solution):
return np.sum(solution**2)
problem = {
"obj_func": objective_function,
"bounds": FloatVar(lb=(-1000.,)*10000, ub=(1000.,)*10000), # 10000维
"minmax": "min",
"log_to": "console",
}
optimizer = SHADE.OriginalSHADE(epoch=10000, pop_size=100)
g_best = optimizer.solve(problem)
print(f"Best solution: {g_best.solution}, Best fitness: {g_best.target.fitness}")
分布式/并行优化
MEALPY支持使用多线程或多进程进行分布式优化:
from mealpy import FloatVar, SMA
import numpy as np
def objective_function(solution):
return np.sum(solution**2)
problem = {
"obj_func": objective_function,
"bounds": FloatVar(lb=(-100.,)*100, ub=(100.,)*100),
"minmax": "min",
"log_to": "console",
}
optimizer = SMA.OriginalSMA(epoch=10000, pop_size=100, pr=0.03)
# 使用10个线程
optimizer.solve(problem, mode="thread", n_workers=10)
print(f"Best solution: {optimizer.g_best.solution}, Best fitness: {optimizer.g_best.target.fitness}")
# 使用8个CPU核心
optimizer.solve(problem, mode="process", n_workers=8)
print(f"Best solution: {optimizer.g_best.solution}, Best fitness: {optimizer.g_best.target.fitness}")
自定义问题
MEALPY允许用户定义自定义的优化问题。以下是一个优化SVM超参数的例子:
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn import datasets, metrics
from mealpy import FloatVar, StringVar, IntegerVar, BoolVar, MixedSetVar, SMA, Problem
# 加载数据集
X, y = datasets.load_breast_cancer(return_X_y=True)
# 创建训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1, stratify=y)
sc = StandardScaler()
X_train_std = sc.fit_transform(X_train)
X_test_std = sc.transform(X_test)
data = {
"X_train": X_train_std,
"X_test": X_test_std,
"y_train": y_train,
"y_test": y_test
}
class SvmOptimizedProblem(Problem):
def __init__(self, bounds=None, minmax="max", data=None, **kwargs):
self.data = data
super().__init__(bounds, minmax, **kwargs)
def obj_func(self, x):
x_decoded = self.decode_solution(x)
C_paras, kernel_paras = x_decoded["C_paras"], x_decoded["kernel_paras"]
degree, gamma, probability = x_decoded["degree_pras"], x_decoded["gamma_paras"], x_decoded["probability_paras"]
svc = SVC(C=C_paras, kernel=kernel_paras, degree=degree,
gamma=gamma, probability=probability, random_state=1)
# 拟合模型
svc.fit(self.data["X_train"], self.data["y_train"])
# 进行预测
y_predict = svc.predict(self.data["X_test"])
# 评估性能
return metrics.accuracy_score(self.data["y_test"], y_predict)
my_bounds = [
FloatVar(lb=0.01, ub=1000., name="C_paras"),
StringVar(valid_sets=('linear', 'poly', 'rbf', 'sigmoid'), name="kernel_paras"),
IntegerVar(lb=1, ub=5, name="degree_paras"),
MixedSetVar(valid_sets=('scale', 'auto', 0.01, 0.05, 0.1, 0.5, 1.0), name="gamma_paras"),
BoolVar(n_vars=1, name="probability_paras"),
]
problem = SvmOptimizedProblem(bounds=my_bounds, minmax="max", data=data)
model = SMA.OriginalSMA(epoch=100, pop_size=20)
model.solve(problem)
print(f"Best agent: {model.g_best}")
print(f"Best solution: {model.g_best.solution}")
print(f"Best accuracy: {model.g_best.target.fitness}")
print(f"Best parameters: {model.problem.decode_solution(model.g_best.solution)}")
结语
MEALPY是一个功能强大、易于使用的Python库,为各种优化问题提供了广泛的元启发式算法。无论您是研究人员、工程师还是数据科学家,MEALPY都能为您的优化任务提供宝贵的工具和解决方案。通过其丰富的算法库、灵活的问题定义和强大的分析工具,MEALPY可以帮助您更快、更有效地解决复杂的优化问题。
如果您在使用MEALPY时发现它对您的工作有所帮助,请考虑在您的研究中引用MEALPY。您的支持将有助于MEALPY的持续发展和改进,使更多人受益于这个开源项目。









