Medusa: 加速大语言模型生成的简单框架
在人工智能和自然语言处理领域,大语言模型(LLM)的出现引发了一场革命。然而,这些模型的巨大规模也带来了生成速度慢的问题。为了解决这一挑战,研究人员开发了各种加速技术,其中最著名的是推测解码。但是,这些技术往往存在一些痛点,如需要一个优质的草稿模型、系统复杂性高、以及在使用基于采样的生成时效率低下等。
为了应对这些挑战,一个名为Medusa的创新框架应运而生。Medusa是一个简单而强大的框架,旨在通过多个解码头来加速大语言模型的生成过程。让我们深入了解Medusa的工作原理及其独特之处。
Medusa的核心理念
Medusa的核心思想是在同一个模型上训练多个解码头,而不是引入一个新的模型。这种方法有几个显著的优势:
-
参数高效训练: Medusa的训练过程非常参数高效,即使是计算资源有限的研究者也能进行。由于不需要额外的模型,也无需调整分布式计算设置。
-
放宽分布匹配要求: Medusa放宽了对匹配原始模型分布的严格要求,这使得非贪婪生成的速度甚至可以超过贪婪解码。
-
简化系统复杂性: 通过在同一模型上添加额外的"头部",Medusa避免了引入新模型带来的复杂性。
Medusa的工作原理
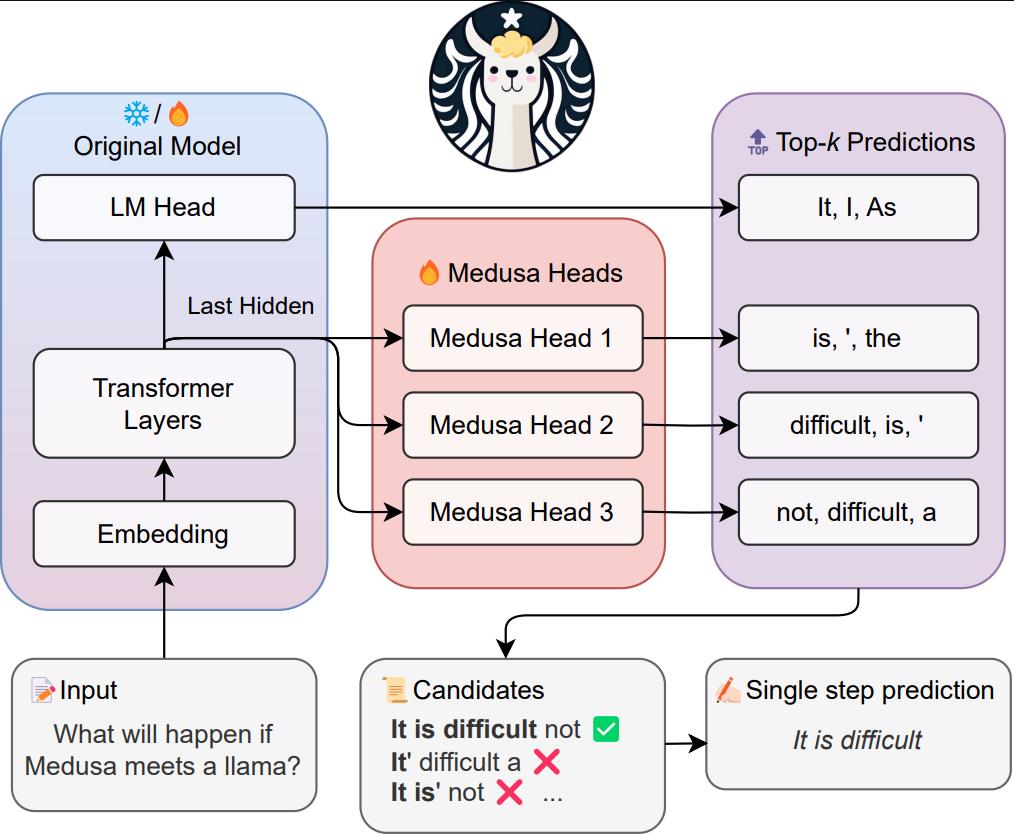
Medusa的工作流程可以概括为以下几个步骤:
-
添加额外解码头: Medusa在LLM上添加额外的"头部",用于同时预测多个未来的token。
-
保持原始模型不变: 在增强模型时,原始模型保持不变,只有新添加的头部在训练过程中进行微调。
-
多token预测: 在生成过程中,这些头部各自为相应位置产生多个可能的词。
-
树形注意力机制: 这些选项随后被组合并通过树形注意力机制进行处理。
-
接受机制: 最后,使用典型的接受机制从候选项中选择最长的合理前缀,用于进一步解码。
Medusa的性能表现
在初始版本中,Medusa主要针对批量大小为1的情况进行了优化,这是本地模型托管中常用的设置。在这种配置下,Medusa在各种Vicuna模型上实现了约2倍的速度提升。
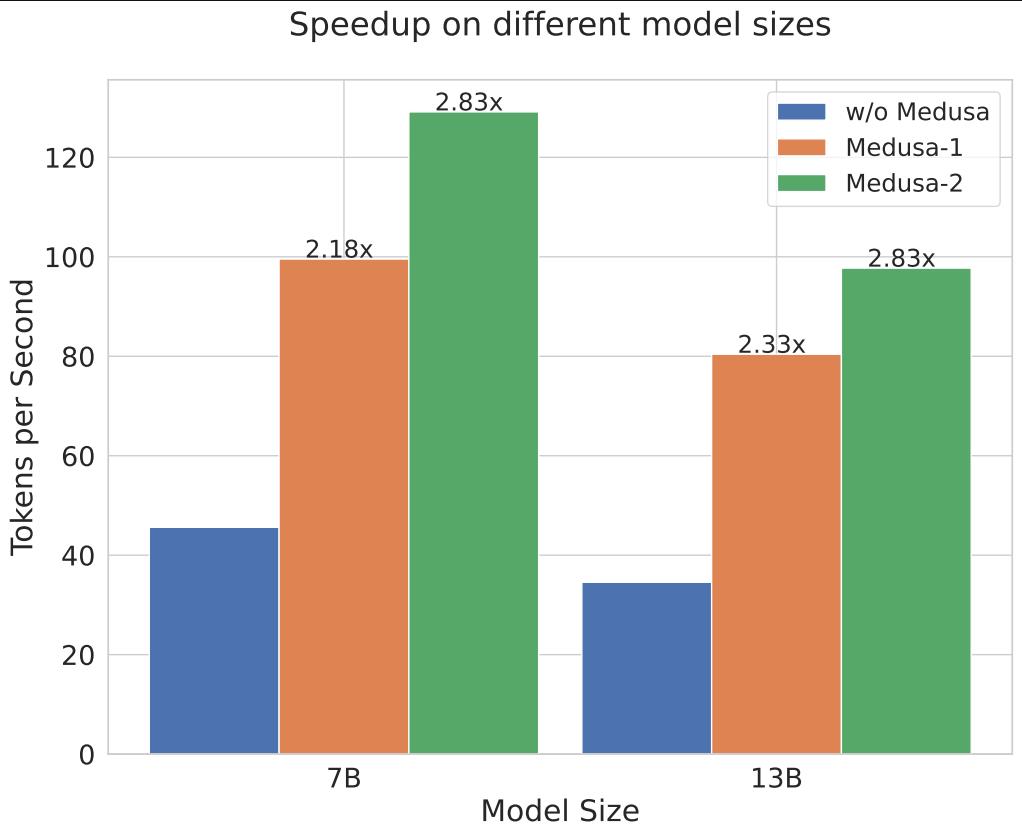
在最新的更新中,研究人员引入了Medusa-2,这是一种全模型训练方法。与只训练新头部的Medusa-1相比,Medusa-2需要一种特殊的配方,既能添加推测预测能力,又能保持原始模型的性能。此外,研究人员还添加了自蒸馏支持,允许将Medusa添加到任何经过微调的LLM中,而无需原始训练数据。
Medusa的应用场景
Medusa的模块化设计使其可以应用于任何需要商业逻辑的应用程序中。以下是一些可能的应用场景:
- 电子商务: 多区域和多渠道商店,具有无限定制选项。
- 市场: 设置具有多个供应商的市场。
- 订阅业务: 处理基于订阅的订单并设置自定义续订逻辑。
- 订单管理系统: 处理来自多个渠道的订单并路由到您的履行服务。
- B2B商店: 为B2B客户设置独特的价格列表、折扣和产品访问权限。
- 销售点(POS)系统: 支持POS系统和店内购买。
社区采用
Medusa已经被许多开源项目采用,包括:
- TensorRT-LLM
- TGI (Text Generation Inference)
- RTP-LLM
这些项目的采用证明了Medusa在加速LLM开发方面的潜力和价值。
未来展望
Medusa团队正在积极努力扩展其功能,包括将其集成到其他推理框架中,以实现更大的性能提升并将Medusa扩展到更广泛的设置。他们欢迎社区贡献,并鼓励对改进Medusa有想法的人开启问题进行讨论。
结论
Medusa代表了加速大语言模型生成的一个重要进展。通过其创新的多解码头方法,它成功地解决了现有加速技术的许多痛点。随着AI和自然语言处理领域的不断发展,像Medusa这样的工具将在推动技术进步和提高模型效率方面发挥关键作用。
无论您是研究人员、开发人员还是对AI感兴趣的爱好者,Medusa都为探索和改进大语言模型的生成过程提供了一个激动人心的机会。随着更多的采用和社区贡献,我们可以期待看到Medusa在未来取得更大的进展和应用。










