
引言
近年来,多模态大语言模型(MLLMs)在各种视觉理解任务中取得了显著进展。然而,大多数模型仅限于处理低分辨率图像,这限制了它们在需要详细视觉信息的感知任务中的有效性。为了突破这一限制,来自上海交通大学、上海人工智能实验室和南洋理工大学的研究人员提出了MG-LLaVA(Multi-Granularity LLaVA)模型,这是一种创新的多模态大语言模型,通过引入多粒度视觉流处理来增强模型的视觉处理能力。
MG-LLaVA的创新架构
MG-LLaVA的核心创新在于其多粒度视觉流处理机制。这种机制包括三个关键组件:
-
低分辨率特征: 保留了传统MLLMs的基础视觉处理能力。
-
高分辨率特征: 引入了额外的高分辨率视觉编码器,用于捕捉细粒度的视觉细节。
-
目标中心特征: 整合了离线检测器识别的边界框中的目标级特征。
这三种特征通过一个创新的Conv-Gate融合网络进行融合,最终生成丰富的视觉表示。
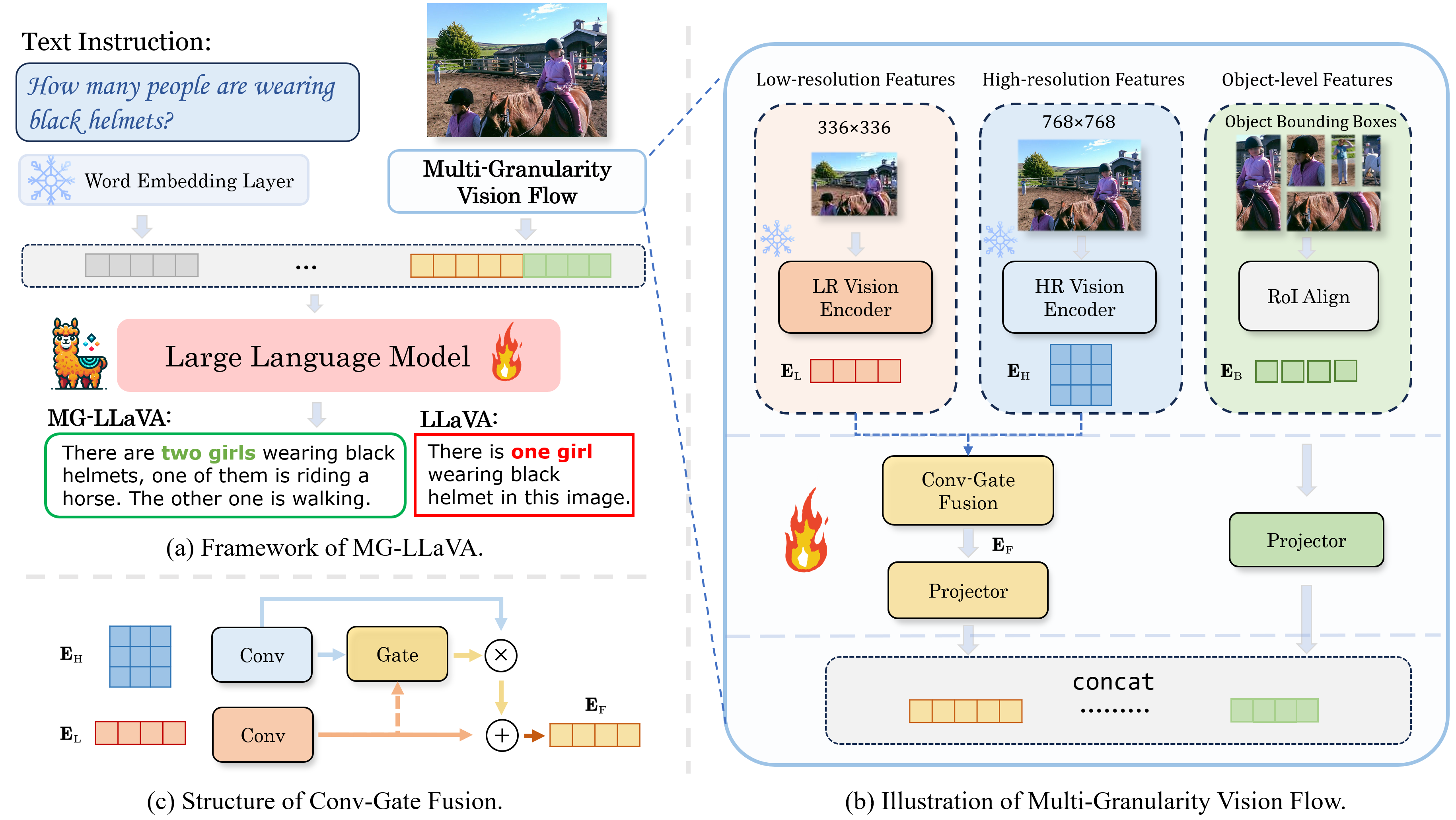
模型训练与性能
MG-LLaVA的训练过程完全基于公开可用的多模态数据,通过指令微调的方式进行。尽管如此,MG-LLaVA展现出了卓越的视觉感知能力。研究团队采用了从3.8B到34B参数不等的多个大语言模型,包括Phi-3-3.8B、Vicuna1.5-7B、Vicuna1.5-13B、llama3-8B和Yi1.5-34B。
在视觉编码器方面,MG-LLaVA使用了CLIP-Large-336和CLIP-ConvNext-320-d作为视觉编码器。这种组合使得模型能够同时处理低分辨率和高分辨率的视觉信息,大大增强了其视觉理解能力。
训练过程采用两阶段方法,包括预训练和微调。以Vicuna1.5-7B模型为例,在8个A100 GPU上的完整训练过程大约需要23小时。这种高效的训练策略使得MG-LLaVA能够快速适应新的视觉任务。
性能评估
MG-LLaVA在多个视觉理解基准测试中展现出了优异的性能:
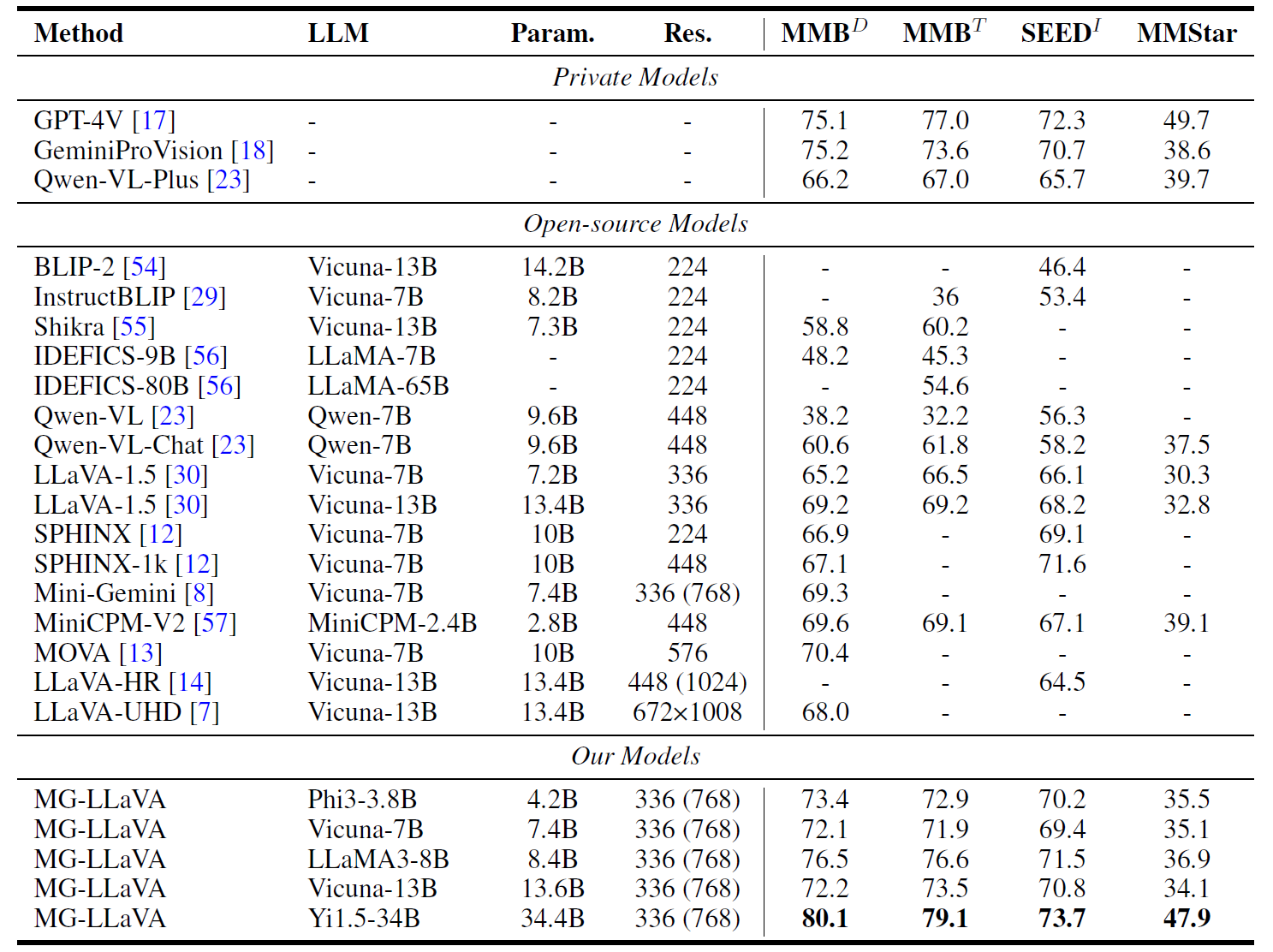
从上图可以看出,MG-LLaVA在多个视觉问答和图像理解任务中均取得了显著的性能提升。特别是在需要细粒度视觉理解的任务中,MG-LLaVA的优势更为明显。
此外,MG-LLaVA还支持对MMVet、LLaVA-Bench-in-the-wild、MMVP和MathVista等最新基准的评估,进一步证明了其在各种视觉理解任务中的强大能力和适应性。
技术细节与实现
MG-LLaVA的实现基于XTuner框架,这使得模型训练和评估过程变得高效和灵活。以下是一些关键的技术细节:
-
环境配置: 推荐使用Python 3.10构建虚拟环境。
-
数据准备: 研究团队提供了详细的数据准备指南,确保模型能够访问高质量的训练数据。
-
模型权重: 所有的模型检查点都可以在ModelZoo上获取。
-
训练过程: 训练分为预训练和微调两个阶段,研究团队提供了详细的训练脚本和配置文件。
-
评估: MG-LLaVA支持多种评估指标,包括MMBench、SEED、SQA、AI2D、TextVQA、POPE、GQA和VQAv2等。
-
优化技术: 训练过程中使用了DeepSpeed进行优化,支持ZeRO-1、ZeRO-2和ZeRO-3等策略。
应用前景与影响
MG-LLaVA的出现为视觉-语言AI领域带来了新的可能性。它的多粒度视觉处理能力使得模型能够更好地理解和分析复杂的视觉场景,这在诸如医疗影像分析、自动驾驶、智能监控等领域都有广泛的应用前景。
此外,MG-LLaVA的研究成果也为未来多模态AI模型的设计提供了新的思路。通过整合不同粒度的视觉信息,AI系统可以更接近人类的视觉认知能力,为创建更智能、更灵活的AI系统铺平了道路。
结论
MG-LLaVA代表了多模态大语言模型领域的一个重要突破。通过创新的多粒度视觉流处理机制,MG-LLaVA成功地增强了模型的视觉理解能力,特别是在处理需要细粒度视觉信息的任务时表现出色。这项研究不仅推动了视觉-语言AI的发展,也为未来更强大、更灵活的AI系统的设计提供了宝贵的insights。
随着MG-LLaVA的开源和进一步发展,我们可以期待看到更多基于此技术的创新应用,以及在各个领域中的实际落地。MG-LLaVA的成功也再次证明了开源合作在推动AI技术进步中的重要作用,为整个AI社区带来了新的机遇和挑战。
参考资料
- MG-LLaVA GitHub仓库
- MG-LLaVA: Towards Multi-Granularity Visual Instruction Tuning (arXiv论文)
- MG-LLaVA项目页面
对于有兴趣深入了解或使用MG-LLaVA的研究者和开发者,项目的GitHub仓库提供了详细的安装指南、使用说明和评估方法。通过探索和贡献这个开源项目,我们可以共同推动多模态AI技术的进步,为创造更智能、更有洞察力的AI系统贡献力量。









