出大事了,开源大模型界出大事了!
Meta前脚刚发布了“最强模型” Llama 3.1 405B,Mistral后脚就来踢馆,发布 Mistral Large 2,参数123B。
Mistral的 Large 2 模型的参数不到 Llama 3.1 的 三分之一,难道是梁静茹给它的勇气来踢馆吗?
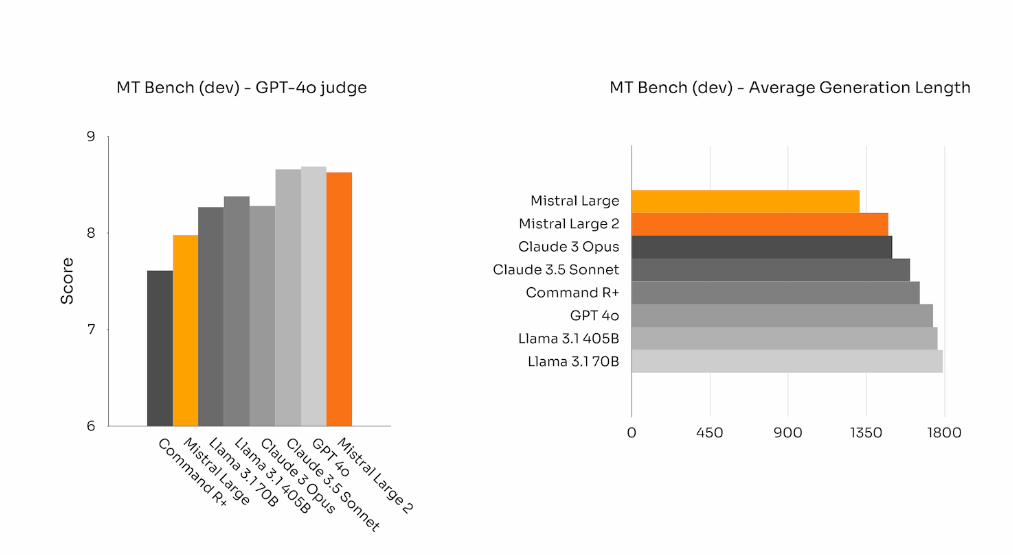
别着急,让我们来通过测试数据来对比一下。
扫码加入AI交流群
获得更多技术支持和交流
(请注明自己的职业)

数据对比
一、代码编写
Mistral的AI 最大的优势就是代码的编写,在这一点上那肯定是不能输给 Llama 3.1 的。
Mistral Large 2 支持包括Python、Java、C、C++、JavaScript和Bash在内的 80多种 编程语言,吸取Codestral 、Codestral Mamba经验,表现远超之前的Mistral Large。
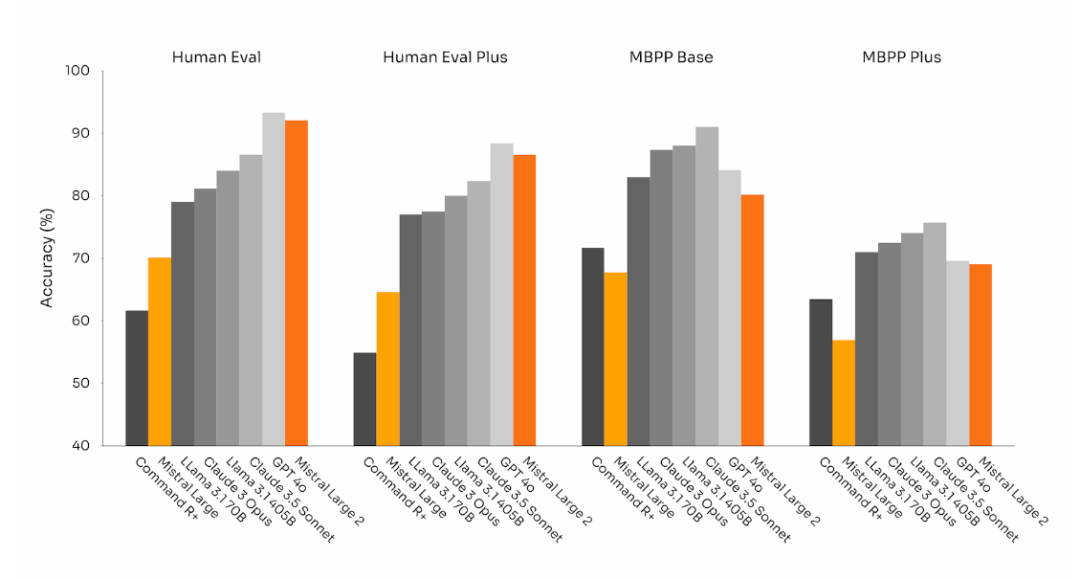
通过对比我们不难看出,在 Human Eval基准 上,Mistral Large 2 的代码生成能力只是略逊于GPT-4o,完爆 Llama 3.1。
而在 MBPP 基准上,Llama 3.1 也算是找回场子,不论是 405B 还是 70B 都优于 Mistral Large 2。
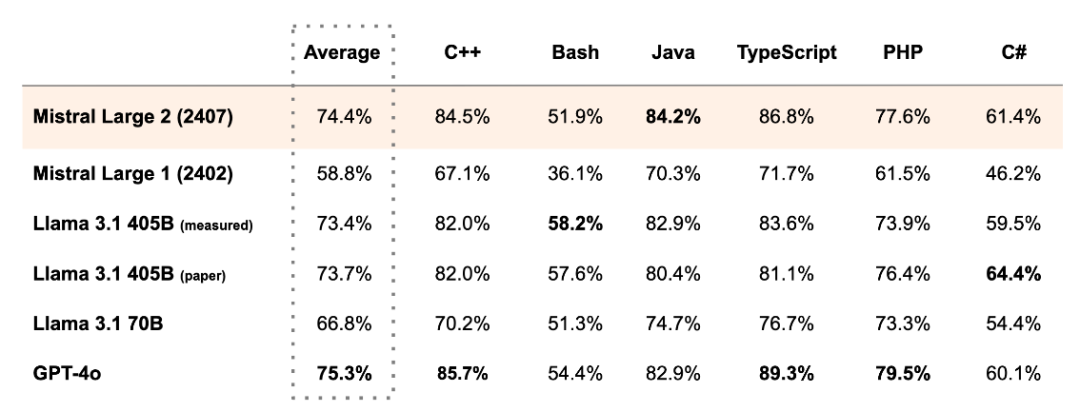
而在 MultiPL-E 的 多种编程语言基准 上,Mistral Large 2 更是多方面超越 Llama 3.1 405B,直逼GPT4o。
Mistral Large 2 还增加了 函数调用能力。
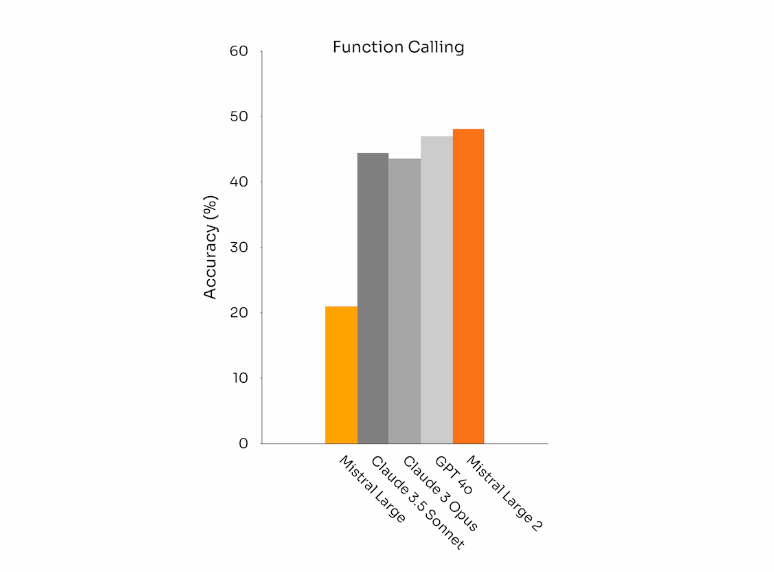
可以看到在这一能力上 Mistral Large 2 稳坐 冠军宝座,甚至干掉了GPT4o。
二、推理能力
数学推理也是困扰大模型已久的难题之一,这次 Llama 3.1 和 Mistral Large 2 在数学推理方面也是进步极大。
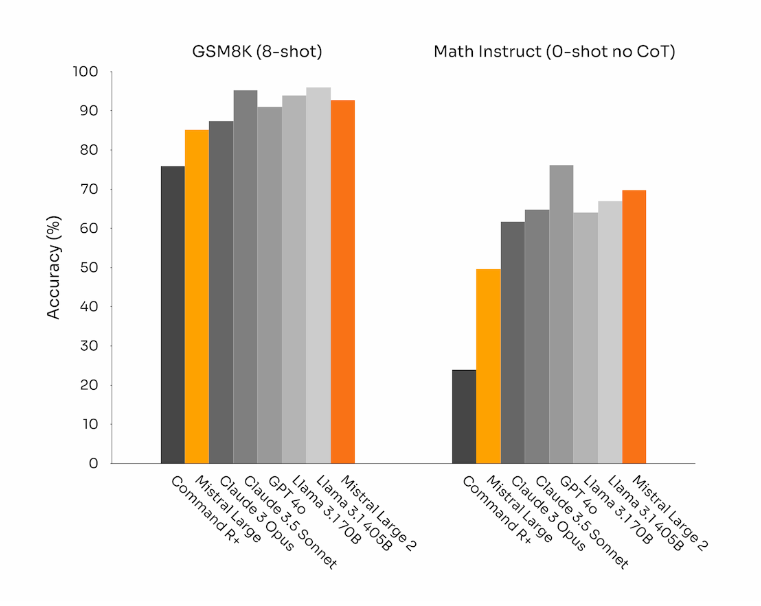
可以看到,在 GSM8K(8-shot)基准 下 Llama 3.1 405B 几乎是处于 最高水平,而 Mistral Large 2 也是 名列前茅。
在MATH(0-shot,无CoT)基准 下 Mistral Large 2 水平仅次于GPT4o,Llama 3.1 405B位列第三。
三、多语言文本指令优化
Mistral Large 2 具有 128k 上下文窗口。预训练版本的 MMLU 能达到 84.0%。
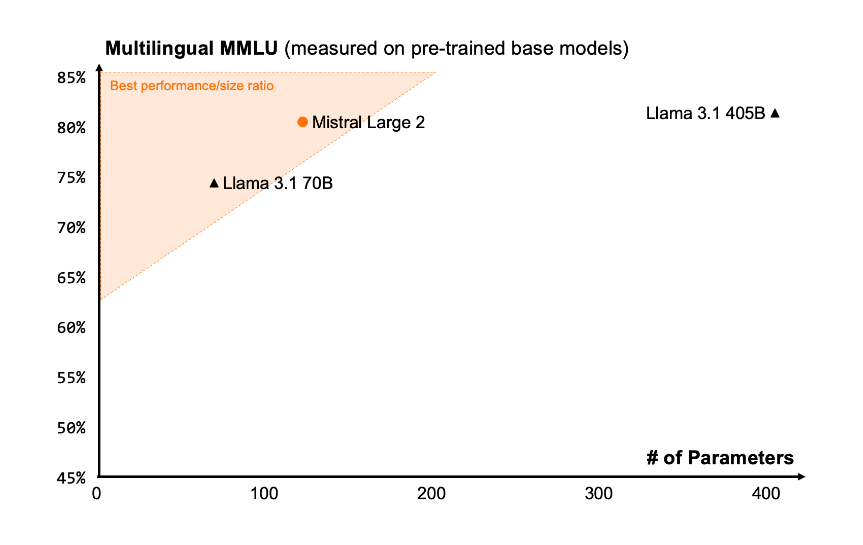
昨天发布的 Llama 3.1 针对八种不同语言进行了文本指令优化,但其中偏偏没有 中文,使得 Llama 3.1 中文水平极差。
但这次 Mistral Large 2 带上了,包括中文在内,还支持英语、日语、韩语、法语等 数十种语言。
据测试,在 多语言MMLU 上,Mistral Large 2 的平均性能 明显优于Llama 3.1 70b(高6.3%),与 Llama 3 405B 相当(低0.4%)。

四、指令遵循和对齐
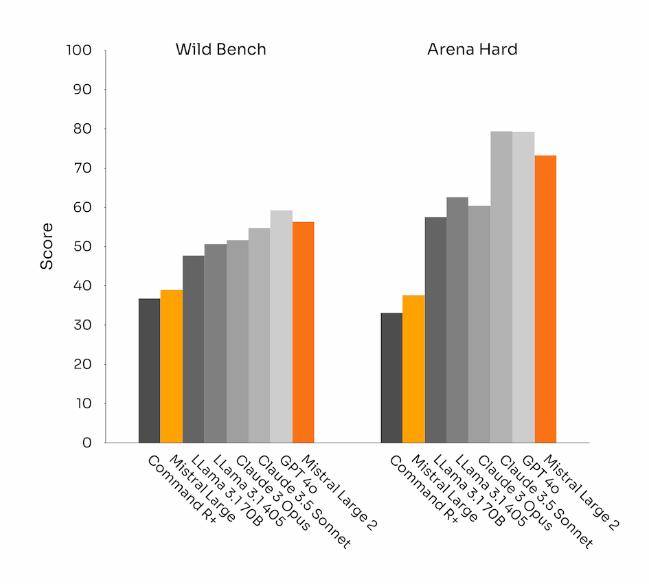
可以看出, Large2 在 Wild Bench和Arena Hard 上的表现都非常出色,处于顶尖状态,优于 Llama 3.1。